

Embedding的定义与目标
定义
将复杂、高维、离散、非结构化数据难直接处理的(如文本、图像、类别标签、用户行为等),转化为机器能理解的“数值身份证”(低维向量),向量维度对应数据潜在特征,核心是让类似数据在向量空间中更接近,便于计算机理解和处理。
目标
● 降维与结构化:把高维离散数据(如文本词汇表)压缩到低维连续空间,让类似内容(如“苹果”和“水果”)的向量距离更近。
● 语义/特征捕捉:向量需蕴含原始数据的语义、特征关系(如图像Embedding保留颜色、轮廓关联;文本Embedding体现语义类似性 )。
应用场景
● 文本领域:
○ 词嵌入(Word Embedding):把单词转低维向量,捕捉语义/上下文(如Word2Vec让“国王-男人+女人≈女王” );
○ 句子/文档嵌入:将整段文本转向量,用于文本分类、类似度计算(如BERT生成动态句向量,区分多义词“苹果”的水果/科技含义 )。
● 图像领域:
用卷积神经网络(CNN)等提取特征,再映射为向量(如FaceNet生成128维人脸向量,用于人脸识别、以图搜图 )。
● 图结构数据:
图嵌入(Graph Embedding)把节点、边转向量,捕捉图中结构关系(如社交网络中,好友多的用户向量更类似 )。
● 推荐/搜索场景:
用户行为、商品信息转向量,通过类似度匹配做推荐(如电商用商品Embedding找“同款”,平台用用户行为向量推“类似商品” )。
关键技术及演变历史
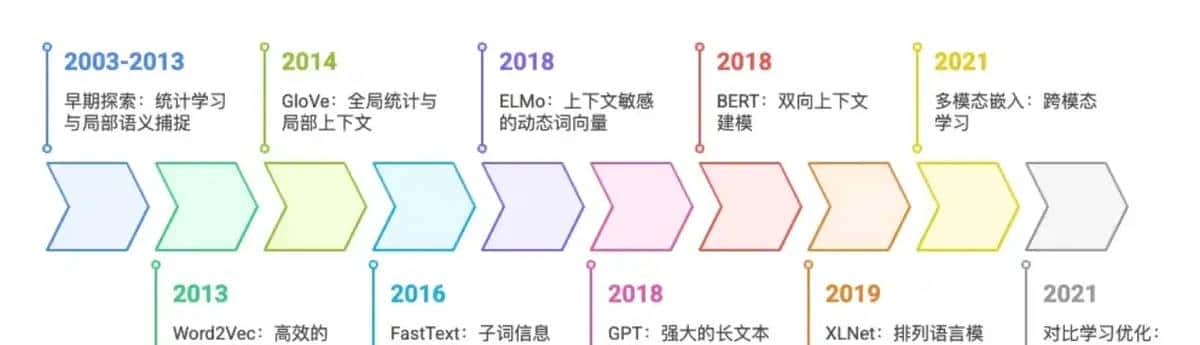
● 基础构建期(2003-2016):静态词向量主导(LSA→Word2Vec→GloVe→FastText),解决 “语义量化” 基础问题。
● 动态突破期(2017-2019):上下文敏感(ELMo→BERT→XLNet),解决 “一词多义”“长文本建模”。
● 多模态与优化期(2020 – 至今):跨模态(CLIP)+ 方法优化(SimCSE),拓展 Embedding 边界。
SVD(Singular value decomposition,奇异值分解)
它是一种纯粹的数学矩阵分解方法,对任意矩阵(列如文本场景里的词 – 文档矩阵 ),分解为左奇异矩阵、对角奇异值矩阵、右奇异矩阵的乘积,核心是数学层面的矩阵变换,不针对特定业务场景设计。
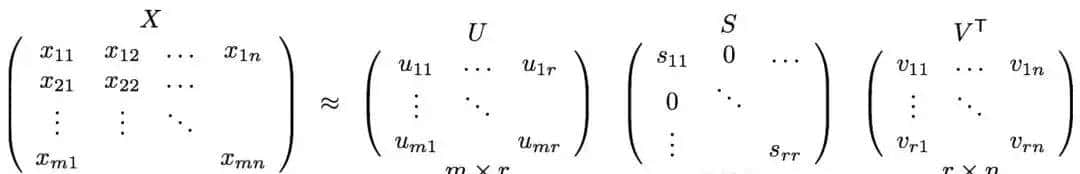
SVD一个主要优点是对矩阵降维,对于高维矩阵可以通过SVD表明成三个维度相对较低的矩阵.缺点是SVD分解要求矩阵是稠密的,一般采用对矩阵中的缺失值进行补全(列如补0、全局平均值、用户物品平均值补全等)得到稠密矩阵。再用SVD分解并降维。但实际过程中,元素缺失值是超级多的,导致了传统SVD不论通过以上哪种方法进行补全都是很难在实际应用中起效果。此外传统SVD在实际应用中还有一个严重的问题——计算复杂度(时间复杂度是,空间复杂度是)
LSA(潜在语义分析)
LSA是一种通过数学降维挖掘文本隐含语义结构的技术,诞生于20世纪90年代,主要解决信息检索中的词汇歧义与同义词匹配问题。其核心假设是:词汇的语义可通过上下文共现关系体现,类似语义的词会在类似文档中高频共现。
核心贡献:
- 实现文本数据降维:LSA利用奇异值分解(SVD)对词 – 文档矩阵进行分解,将高维稀疏的文本数据映射到低维的潜在语义空间。例如,在处理大量文档时,原始的词向量空间可能维度极高且稀疏,而LSA通过保留前(k)个最大奇异值及其对应的奇异向量,去除了一些噪声和不重大的信息,实现数据的有效压缩,同时保留了文本的主要语义结构,使得后续的分析和处理更加高效。
- 解决一词多义与一义多词问题:传统的信息检索和文本处理方法难以处理一词多义(polysemy)和一义多词(synonymy)的情况。LSA通过将词和文档映射到潜在语义空间,能够将具有类似语义的词(即使是不同的词形)聚集到一起,将同一个词在不同语义下的用法区分开来。例如,“苹果”既可以指水果,也可能是指某家科技公司,LSA可以根据上下文将其不同语义区分开;对于“汽车”和“轿车”这样的同义词,LSA能认识到它们在语义上的类似性,从而在信息检索等任务中提高召回率和准确率。
- 挖掘文本潜在语义结构:LSA能够发现文本数据中潜在的语义关系和结构。它通过分析词与词、词与文档之间的共现关系,揭示出隐藏在文本背后的主题、概念等语义信息。例如,在一个包含各种科技文章的文档集合中,LSA可以发现“人工智能”“机器学习”“深度学习”等词常常一起出现,从而识别出这些词与科技领域的某个特定主题相关,有助于对文本内容进行更深入的理解和分析。
- 提升信息检索与文本分类等任务的性能:在信息检索中,LSA可以根据文档在潜在语义空间中的表明,更准确地计算查询词与文档之间的语义类似度,从而返回更相关的检索结果,提高检索的准确性。在文本分类任务中,LSA能够思考到文本的潜在语义特征,将具有类似语义的文档归为同一类,使分类结果更加准确和合理。同样,在文本聚类中,LSA可以基于语义类似性将文档聚成不同的类别,有助于对大规模文档集合进行组织和管理。
- 语言和领域的通用性:LSA不局限于特定的语言或领域,它可以应用于不同语言的文本分析,并且在各种领域的文本数据上都能发挥作用,具有较强的通用性和适应性。无论是处理科技文献、新闻报道、文学作品还是其他类型的文本,LSA都能尝试挖掘其中的潜在语义信息。
核心原理
数学基础:从词-文档矩阵到SVD分解
LSA的底层逻辑基于线性代数中的奇异值分解(SVD),以下是核心数学流程:
- 构建词-文档矩阵(Term-Document Matrix)
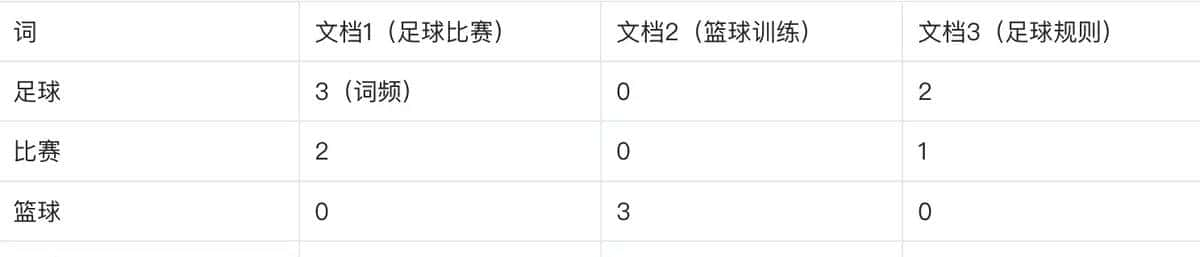
● 矩阵构造:设语料库有 m 个词、n 个文档,构造 m×n 矩阵 A,其中 Aij 表明词 i 在文档 j 中的权重(常用 TF-IDF 或词频)。
● 示例:
- 奇异值分解(SVD)降维
对矩阵 A 进行 SVD 分解:A=U⋅Σ⋅VT
● U:m×m 左奇异矩阵,行向量表明词的语义向量;
● Σ:m×n 对角矩阵,对角线元素为奇异值,表征语义维度的重大性;
● V:n×n 右奇异矩阵,列向量表明文档的语义向量。
降维操作:选取前 k 个最大奇异值(对应最主要的语义维度),舍弃次要维度,得到近似矩阵:Ak=Uk⋅Σk⋅VkT
其中 k≪min(m,n),降维后词与文档被映射到 k 维语义空间。 - 语义空间的含义
● 词向量:降维后的词向量中,类似语义的词(如“足球”和“绿茵场”)在空间中距离更近;
● 文档向量:降维后的文档向量可表明为词向量的加权和,反映文档的主题倾向(如“足球比赛”与“足球规则”在语义空间中接近)。
工作流程
- 语料预处理:
○ 分词、去停用词、词干提取(如“playing”→“play”)。 - 矩阵构建:
○ 计算TF-IDF权重,生成词-文档矩阵 ( A )。 - SVD分解与降维:
○ 保留前 ( k ) 个奇异值(一般 ( k=50 sim 300 ),依语料规模调整)。 - 语义映射与应用:
○ 词与文档映射到低维空间后,可用于检索、聚类等任务。
典型应用场景
- 信息检索(IR):
○ 解决“词汇不匹配”问题:如查询“足球赛事”时,能匹配到含“足球比赛”的文档(因语义相近)。
○ 示例:用户搜索“computer science”,LSA可将其与“CS”“informatics”等同义词关联。 - 文本聚类与分类:
○ 基于语义向量将文档分组(如将“机器学习论文”与“深度学习教程”归为一类)。 - 词义消歧:
○ 区分多义词在不同上下文中的语义(如“bank”在“河岸”与“银行”场景中的向量差异)。 - 文本摘要与类似度计算:
○ 通过语义向量计算文档间类似度,辅助生成摘要或推荐相关内容。
优缺点与局限性
优点:
● 语义层面建模:超越词形匹配,捕捉词汇隐含关联(如“计算机”与“PC”)。
● 数学原理严谨:基于线性代数理论,可解释性强。
● 无监督学习:无需标注数据,适用于大规模语料预处理。
缺点:
- 计算复杂度高:SVD对大规模矩阵(如百万级词-文档矩阵)计算耗时耗内存。
- 语义维度难定:人工设定降维维度 ( k ),缺乏理论指导(需凭经验调优)。
- 动态适应性差:新增文档需重新计算全量矩阵,无法增量更新。
- 主题解释性弱:降维后的语义维度缺乏明确的主题标签(如“科技”“体育”),需额外解读。
优缺点的演化
LSA是早期语义分析的经典方法,为后续技术奠定了基础:
● 向主题模型演进:LDA(2003年)通过概率建模改善了LSA的主题解释性问题。
● 向神经网络演进:Word2Vec(2013年)通过浅层神经网络生成词向量,解决了LSA的矩阵稀疏性问题(词-文档矩阵常因低频词导致大量0值)。
● 向上下文语义演进:BERT(2018年)通过预训练捕捉动态词义(如“bank”在不同句子中的不同向量表明),超越了LSA的静态语义建模。
Word2Vec
Word2Vec是由Google在2013年提出的词嵌入(Word Embedding) 模型,其核心目标是将自然语言中的词语转换为低维稠密的实数向量(词向量),使向量能捕捉词语的语义和语法关系。它通过神经网络学习词语的上下文关系,将词语映射到连续向量空间,使得语义相近的词在向量空间中距离更近。
Word2Vec的出现标志着自然语言处理从“符号表明”向“向量表明”的重大转变,其高效的训练机制和对语义关系的捕捉能力,使其成为NLP领域(如机器翻译、情感分析)的基础技术。尽管存在局限性,但它为后续预训练模型的发展奠定了核心思想——通过上下文学习词语的分布式表明。
核心贡献
其核心贡献主要体目前技术创新、效率优化和语义表明能力三个层面,具体如下:
1.开创分布式语义表明(Distributed Representation)的实用化路径
● 将语义映射为向量空间关系:
传统词袋模型(BOW)或独热编码(One-Hot)仅能表明词的离散存在,无法捕捉语义相关性(如“国王”与“王后”的关系)。而Word2Vec通过训练词向量,将语义转化为向量空间中的几何关系(如“国王 – 男人 + 女人 ≈ 王后”),首次实现了语义的可计算性。
● 用上下文预测建模语义关联:
基于“词的含义由其上下文决定”(Firth s hypothesis),通过Skip-Gram(用中心词预测上下文)或CBOW(用上下文预测中心词)模型,将词的语义关联转化为概率预测问题,使词向量能编码句法和语义关系(如名词、动词的分类,同义词聚类等)。
2.提出高效训练框架,推动词向量大规模应用
● 分层Softmax(Hierarchical Softmax)与负采样(Negative Sampling):
○ 传统神经网络在处理大规模词表时,输出层计算复杂度极高(Softmax需遍历所有词)。分层Softmax通过构建霍夫曼树,将计算复杂度从(O(V))降至(O(log V))((V)为词表大小)。
○ 负采样则随机选取少量非目标词(负例)进行训练,避免计算所有词的概率,进一步提升效率。例如,训练“国王”的上下文时,仅需预测少数负例词(如“苹果”“书本”),而非整个词表。
● 简化模型结构,实现千亿级数据训练:
Word2Vec舍弃复杂的神经网络结构(如多层隐藏层),采用单层神经网络+线性映射,配合上述优化方法,可在普通硬件上处理数十亿词的语料库(如维基百科、新闻文本),为后续预训练模型奠定工程基础。
3.揭示词向量的语义线性结构,开启“词向量运算”范式
● 类比推理(Analogy Reasoning)的突破性表现:
Word2Vec词向量可通过向量加减法实现语义逻辑推理,例如:
vector(“国王”) – vector(“男人”) + vector(“女人”) ≈ vector(“王后”)
vector(“北京”) – vector(“中国”) + vector(“法国”) ≈ vector(“巴黎”)
这种线性关系证明词向量能捕捉语义的组合性,为自然语言理解提供了数学基础。
● 语义聚类与维度可视化:
通过PCA或t-SNE降维后,词向量在空间中的分布呈现明显的语义聚类(如动物、颜色、动词等类别各自聚集),直观验证了模型对语义结构的捕捉能力。例如,“狗”“猫”“马”的向量在空间中邻近,而“苹果”“香蕉”等水果词形成另一簇。
4.推动自然语言处理从符号主义到连接主义的转型
● 为预训练模型提供基础范式:
Word2Vec证明了无监督学习在语义表明中的有效性,启发了后续ELMo、GPT、BERT等预训练模型的发展。其“基于上下文预测”的训练思路,成为预训练模型的核心框架(如BERT的掩码语言模型任务)。
● 降低NLP任务的门槛:
词向量作为通用语义表明,可直接应用于情感分析、命名实体识别、机器翻译等任务,替代传统的人工特征工程。例如,将词向量作为输入层,结合简单的神经网络即可实现文本分类,大幅提升模型泛化能力。
核心原理
Word2Vec算法将句子转换成词+数量并倒排,然后根据倒排词典构建哈夫曼树,然后应用最大似然估算概率
哈夫曼树
哈夫曼树是一种带权路径长度最短的二叉树,核心思想是:
● 对权值(如频率)高的节点赋予更短的路径,权值低的节点赋予更长的路径。
● 常用于数据压缩(如 Huffman 编码),通过减少高频元素的编码长度来降低整体数据量
核心架构:CBOW与Skip-gram
Word2Vec包含两种对称的神经网络架构,其中CBOW是采用词的上下文来预测该词,而Skip-gram则是采用词来预测其上下文。两者网络结构类似,一般所得到的词向量效果相差不大;但对于大型语料,Skip-gram要优于CBOW。二者的区别在于输入与输出的角色互换:
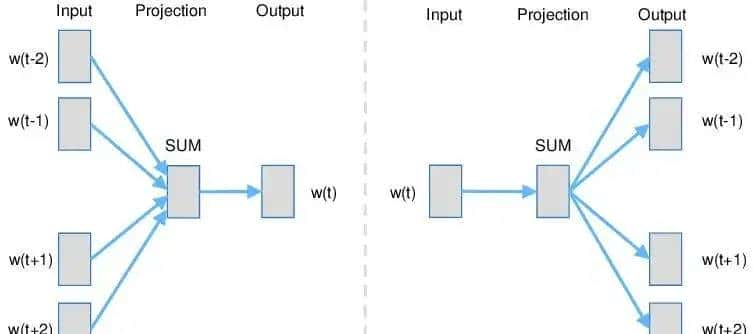
- CBOW(Continuous Bag of Words,连续词袋模型)
● 目标:通过上下文词语预测当前词语。
● 结构:
○ 输入:上下文词语的One-Hot向量(如“国王”和“女人”)。
○ 隐藏层:无激活函数,对输入向量加权求和。
○ 输出:目标词的概率分布(如预测“女王”)。
● 示例:输入“国王”和“女人”,预测“女王”。 - Skip-gram(连续跳字模型)
● 目标:通过当前词语预测上下文词语。
● 结构:
○ 输入:目标词的One-Hot向量(如“国王”)。
○ 隐藏层:映射为稠密向量。
○ 输出:上下文词的概率分布(如预测“男人”“王后”)。
● 示例:输入“国王”,预测其上下文“男人”“统治”等。
对比:
工作流程
以 Skip-Gram 模型 为例进行说明。
- 句子预处理
在训练之前,Word2Vec 第一会对输入的文本进行预处理,包括分词、去除停用词等操作,将句子转换为一系列的单词序列。 - 构建词汇表和倒排索引
● 构建词汇表:统计文本中所有单词的出现频率,并根据设定的最小频率阈值过滤掉罕见词。最终得到的单词集合即为词汇表(Vocabulary)。
● 倒排索引:将每个单词映射到一个唯一的索引值,方便后续的向量化处理。倒排索引的主要作用是快速定位单词在词汇表中的位置。 - 构建哈夫曼树(仅限Hierarchical Softmax)
在 Skip-Gram 模型中,如果使用 Hierarchical Softmax 作为输出层的优化方法,会构建一棵哈夫曼树。哈夫曼树的构建过程如下:
● 统计词频:根据词汇表中每个单词的频率,构建一个优先队列(最小堆)。
● 构建哈夫曼树:每次从队列中取出频率最小的两个节点,合并为一个新的节点,其频率为两个子节点频率之和。重复此过程,直到队列中只剩下一个节点,即为哈夫曼树的根节点。
● 编码路径:每个单词从根节点到叶子节点的路径被编码为一个二进制序列(左分支为0,右分支为1),用于后续的计算。 - 模型训练
Skip-Gram 模型的目标是通过中心词(Target Word)预测上下文词(Context Word)。训练过程如下:
● 输入词向量:将中心词通过嵌入层(Embedding Layer)转换为向量表明。
● 计算概率:
○ Negative Sampling:通过负采样方法,选择少量的负样本(非上下文词),计算中心词与上下文词(正样本)以及负样本之间的类似度,使用逻辑回归(Sigmoid 函数)计算预测概率。
○ Hierarchical Softmax:如果使用哈夫曼树,沿着从根节点到目标上下文词叶子节点的路径,通过二叉决策树计算概率。每个节点的输出是一个二分类问题(左分支或右分支),最终通过路径上的所有决策概率计算目标上下文词的生成概率。
● 优化目标:通过最大化上下文词的生成概率(或最小化负对数似然损失),使用随机梯度下降(SGD)或其他优化算法更新词向量。 - 最大似然估计
在训练过程中,Word2Vec 使用最大似然估计(MLE)来优化模型参数。具体来说,模型的目标是最大化上下文词给定中心词的条件概率: L=∑wi∈Context(wc)logP(wi∣wc) 其中,wc 是中心词,Context(wc) 是中心词的上下文词集合。通过优化这个目标函数,模型学习到的词向量能够捕捉词与词之间的语义关系。
典型应用场景
- 语义类似度计算:如判断“计算机”和“电脑”的向量距离。
- 文本分类与聚类:将文本转化为词向量的加权平均,作为分类器输入。
- 机器翻译与问答系统:捕捉跨语言的语义对应关系。
- 推荐系统:将用户行为转化为“词语”序列,用Word2Vec挖掘隐含关联。
- 情感分析:通过词向量捕捉情感极性(如“开心”与“悲伤”的向量差异)。
优缺点与局限性
优点
- 计算效率显著提升:通过层次Softmax(基于哈夫曼树)或负采样(NEG) 优化,显著降低Softmax计算复杂度,传统神经网络模型训练需数周,Word2Vec在单机上可在小时级完成训练。
- 模型结构简单易实现 : 仅包含输入层、隐藏层和输出层,无复杂神经网络结构(如CNN/RNN),训练过程可并行化(如利用CBOW的上下文词向量求和)
- 词向量通用性强 :预训练模型(如Google News词向量)可直接迁移至各类NLP任务(如情感分析、命名实体识别),无需针对任务微调。
缺点
- 静态词向量:无法处理多义词(如“苹果”指水果或公司),后续衍生出ELMo、BERT等动态模型。
- 上下文窗口固定:一般仅捕捉局部上下文(如窗口大小5-10),对长距离依赖建模能力弱。
- 需大量标注数据:训练依赖大规模语料库(如维基百科、新闻文本),小数据场景效果不佳。
优缺点的演化
优缺点的演化
● 动态词向量与上下文建模的突破: ELMo(Embeddings from Language Models)通过双向LSTM生成动态词向量,根据上下文实时调整词的表明。BERT(Bidirectional Encoder Representations from Transformers)进一步采用Transformer架构,通过双向注意力机制捕捉更复杂的语义依赖,此外BERT能通过全局上下文动态调整向量,解决Word2Vec的多义性瓶颈。
● 低频词优化与全局语义建模:GloVe(Global Vectors for Word Representation)通过全局共现矩阵分解和加权函数优化了这一问题,此外后续模型如FastText通过子词嵌入进一步缓解低频词问题,将“unhappiness”分解为“un-”“happi”“ness”等子词单元,即使未登录词也能通过子词组合生成向量。
● 预训练范式与语义推理的增强:Word2Vec的“即插即用”模式被预训练-微调范式取代
● 效率优化与模型轻量化:针对Word2Vec在极大型词表下的计算瓶颈,演化方向包括:
○ 模型蒸馏:TinyBERT通过知识蒸馏将BERT的参数压缩至原模型的1/7,同时保持相近性能,适合移动端部署。
○ 量化与剪枝:通过低精度计算(如FP16)和冗余参数裁剪,降低存储和计算成本。例如,DistilBERT在保持90%性能的同时,推理速度提升40%。
● 多模态与语义增强的融合:解决Word2Vec缺乏语义推理的问题,研究者将知识图谱与词向量结合:
○ 实体嵌入:将知识图谱中的实体(如“苹果公司”)与文本中的词语对齐,增强语义表明的结构化信息。例如,“苹果”的向量可关联到知识图谱中的“科技公司”节点。
○ 多模态预训练:CLIP模型联合训练文本和图像数据,使词向量能关联视觉概念,例如“猫”的向量不仅包含文本语义,还能映射到图像中的猫的特征。
GloVe(Global Vectors for Word Representation)
GloVe(Global Vectors for Word Representation)由斯坦福大学于 2014 年提出,其核心创新在于将全局共现统计信息与局部上下文窗口的优势结合,通过矩阵分解生成语义向量。
核心贡献
- 融合全局统计信息:与Word2Vec等基于局部上下文的模型不同,GloVe通过对全局共现矩阵进行优化,能够捕捉到更为全面的词汇关系。它思考了词汇之间的全局统计信息,而不仅仅是局部上下文,利用词与词之间的共现概率来训练词向量,使得词向量能够更好地反映词在整个语料库中的语义和句法关系。
- 高效利用统计数据:GloVe只训练单词 – 单词共现矩阵中的非零元素,而不是整个稀疏矩阵或单个上下文窗口的大型语料库,从而有效地利用统计信息。该模型通过矩阵分解技术,可以高效地学习大规模数据集的词向量,能够处理比Word2Vec更大的语料库,在计算效率上具有优势。
- 较好地捕捉词汇间线性关系:GloVe可以较好地捕捉词汇之间的线性关系,例如“king – man + woman = queen”这样的类比关系,通过词向量的运算可以得到正确的答案。这表明GloVe生成的词向量具有必定的语义和句法结构,能够在必定程度上反映词汇之间的逻辑关系。
- 结合不同模型优点:GloVe结合了全局矩阵分解和局部上下文窗口方法的优点,克服了传统基于计数的方法(如潜在语义分析LSA)在单词类比任务上表现相对较差,以及基于窗口的方法(如skip – gram模型)不能很好地利用语料库统计数据的缺陷。
- 生成可解释性词向量:由于GloVe是基于共现矩阵的统计信息,因此它的词向量更加直观,容易解释。通过查看词向量之间的关系,可以得到词与词之间的相关性,有助于理解词向量所代表的语义和句法信息。
核心原理
GloVe 的核心假设是:共现概率比可编码词与词之间的语义关系。例如,对于词 i、j、k,定义概率比:PjkPik,该比值能反映 “i 与 k 的相关性是否高于 j 与 k 的相关性”。例如,当 k 是 “固体” 时,i 为 “冰”、j 为 “蒸汽”,则 Pik/Pjk 远大于 1,而当 k 是 “气体” 时,该比值远小于 1,从而编码 “冰” 与 “蒸汽” 在物态上的差异。
工作流程
- 语料预处理
● 分词、去停用词,生成词序列(如 “自然语言处理”→“自然”“语言”“处理”)。 - 构建共现矩阵
● 滑动窗口(如窗口大小为 5)遍历语料,统计每个词对的共现次数 Xij,形成 V×V 矩阵(V 为词表大小)。 - 初始化向量与参数
● 随机初始化词向量 wi 和偏置项 bi,一般取值范围为 [−0.05,0.05]。 - 迭代优化目标函数
● 使用梯度下降法(如 Adam)最小化加权平方损失,迭代更新向量和偏置,直至收敛。
● 关键优化点:利用共现矩阵的对称性(Xij=Xji)减少计算量。 - 生成最终词向量
● 训练完成后,词向量 wi 即包含语义信息,可通过余弦类似度衡量词间相关性(如 “国王 – 男人 + 女人≈王后”)
典型应用场景
● 文本分类:利用 GloVe 生成的词向量作为特征,可以有效提升文本分类模型的性能。
● 语义类似度计算:通过计算词向量之间的余弦类似度,可以判断词或句子之间的语义类似性。
● 问答系统:将问题和答案的词向量进行匹配,提高问答系统的准确性和效率。
● 机器翻译:在翻译任务中,GloVe 词向量可以用于对齐源语言和目标语言的语义。
优缺点与局限性
优点:
● 全局信息与局部上下文结合:GloVe 既思考了全局的词共现信息,又保留了局部上下文的细节,能够更全面地捕捉词的语义。
● 性能稳定:在处理小型语料库时表现良好,生成的词向量具有较好的语义一致性。
● 线性关系捕捉能力强:能够很好地捕捉词向量之间的线性关系,例如“国王 – 男人 + 女人 ≈ 女王”。
缺点:
● 计算复杂度高:需要计算整个语料库的共现矩阵,内存和计算开销较大。
● 对稀疏数据处理不足:共现矩阵中大量稀疏值可能导致优化过程不稳定。
● 无法处理多义词:与 Word2Vec 类似,GloVe 生成的词向量是静态的,无法根据上下文动态调整。
优缺点演化
● BERT、GPT 等预训练模型:通过大规模语料库的自监督学习,生成动态词向量,能够更好地处理多义词和复杂语义。
● FastText:通过词形特征(如词前缀、后缀)生成词向量,对罕见词和多语言文本有更好的支持。
FastText
FastText由Facebook AI Research于2016年提出,其核心创新在于将子词信息与层次Softmax结合,在保证词向量质量的同时大幅提升训练和推理效率。它主要解决两个问题:
- 未登录词(OOV)处理:通过子词(subword)表明捕获词的内部结构。
- 高效文本分类:基于词向量的线性分类器,支持百万级类别。
核心贡献
FastText 的核心贡献并非追求 SOTA 精度,而是在效率与效果间找到了工业级平衡点:
- 子词嵌入:首次将形态学信息融入词向量,为后续预训练模型解决 OOV 问题提供底层方案。
- 高效分类框架:证明简单架构在大规模文本任务中的实用价值,推动 NLP 技术从实验室走向工业界。
- 跨语言迁移雏形:通过子词共享实现语言泛化,为多语言预训练模型(如 XLM-R)埋下伏笔。
核心原理
- 子词嵌入的数学原理
● 子词定义:对于词 w,其长度为 l,所有长度为 3≤k≤6 的连续字符片段称为子词,加上词的前后缀标记(如<hello>的子词包括<he、ell、lo>等)。
● 词向量生成:词 w 的向量为其所有子词向量的和:
vw=∑g∈Gwzg
其中 Gw 是词 w 的子词集合,zg 是子词 g 的向量。 - 层次Softmax优化
与Word2Vec类似,FastText使用哈夫曼树优化分类器,将计算复杂度从 ( O(V) ) 降至 ( O(log V) ),其中 ( V ) 是词表大小。对于文本分类任务,类别标签也被视为特殊词,通过层次Softmax加速预测。
工作流程
- 子词提取
● 输入词(如apple)被拆分为子词集合:<ap、app、ppl、ple、le>等,其中<和>是特殊标记。 - 向量训练
● 基于CBOW或Skip-gram架构,使用子词向量预测上下文词或标签。例如:
○ CBOW模式:通过上下文子词向量预测目标词。
○ Skip-gram模式:通过目标词子词向量预测上下文词。 - 文本分类
● 对于输入文本,将所有词的子词向量求和,得到文本表明,然后通过线性分类器预测类别:
y^=softmax(W⋅sum(vw1,vw2,…,vwn))
其中 W 是分类权重矩阵。
典型应用场景
- 高效文本分类
○ 新闻分类(如将文章归类为“政治”“科技”“体育”)。
○ 情感分析(判断评论是“正面”“负面”“中性”)。
○ 垃圾邮件检测(区分正常邮件与垃圾邮件)。 - 未登录词处理
○ 处理新生词汇(如“元宇宙”“AI大模型”)。
○ 支持形态丰富的语言(如土耳其语、芬兰语)。 - 跨语言迁移
○ 通过共享子词空间,实现跨语言文本分类(如英语模型处理法语数据)。 - 词向量预训练
○ 生成高质量词向量,用于下游任务(如命名实体识别、机器翻译)。
优缺点与局限性
优点:
- 处理未登录词:通过子词表明,即使训练中未出现的词(如“selfie”)也能生成合理向量。
- 训练速度极快:比Word2Vec快10倍以上,支持TB级语料训练。
- 轻量级模型:内存占用小,适合移动端部署。
- 多语言支持:子词粒度的表明天然支持跨语言学习。
缺点与局限性:
- 子词爆炸问题:词表随语料增大呈指数级增长,需控制子词长度(一般 ( k leq 6 ))。
- 多义性处理弱:与Word2Vec类似,每个词只有固定向量,无法区分多义词(如“苹果”的不同含义)。
- 长文本建模不足:简单的词向量求和忽略词序和句法结构,对长文本分类效果有限。
优缺点的演化
动态子词表明:BPE(字节对编码)通过合并高频字符对动态构建子词词汇表。XLNet,结合自回归和自编码优势,通过排列语言模型处理长文本依赖。
多模态融合:CLIP(OpenAI)将文本子词与图像特征对齐,实现跨模态检索(如输入文本“一只猫”检索图片)。
模型压缩与加速:量化技术,将32位浮点数压缩为8位整数,减少内存占用(如FastText量化后模型体积缩小4倍)。剪枝优化:去除冗余子词和连接,提升推理速度。
ElMo(Embeddings from Language Models)
ElMo由Allen Institute于2018年提出,是动态词向量的开创性工作。其核心突破在于:通过双向LSTM(BiLSTM) 捕捉词的上下文语义,为同一个词在不同语境中生成不同的向量表明。
核心贡献
- 打破静态词向量局限:证明语境动态表明对NLP任务的重大性,为BERT等预训练模型奠定理论基础。
- 多层特征融合范式:各层捕捉不同粒度语义(语法→语义→语境),启发后续模型的分层表明学习(如BERT的多层注意力)。
- 预训练+微调框架:确立现代NLP的主流研究范式,推动NLP从“特征工程”向“表明学习”转型。
核心原理
- 双向语言模型(BiLM)架构
● 前向LM:从左到右预测下一个词(如“我吃”预测“苹果”)。
● 后向LM:从右到左预测前一个词(如“吃苹果”预测“我”)。
● 联合训练:将前向和后向LSTM的隐藏状态结合,形成双向语境表明。 - 多层语境向量融合
ElMo一般包含3层BiLSTM(以基础版为例): - 底层:捕捉字符级语法特征(如词缀“ing”表明进行时)。
- 中层:捕捉短语级语义特征(如“breakfast”表明早餐)。
- 顶层:捕捉句子级语境特征(如“我早餐吃breakfast”中的“breakfast”)。
最终词向量为各层向量的加权和:
et=γ∑k=0Lskhk,t
其中 γ 是缩放系数,sk 是各层权重,hk,t 是第 k 层第 t 个词的隐藏状态。
工作流程
- 预训练阶段
● 语料:使用大规模无标注文本(如BooksCorpus、Wikipedia)。
● 目标函数:最大化前向和后向语言模型的对数似然:
∑k=1Nlogp(wk∣w1,…,wk−1)+logp(wk∣wk+1,…,wN)
● 输出:训练完成后,得到多层BiLSTM模型,可用于生成任意文本的语境向量。 - 下游任务适配
● 冻结与微调:
○ 固定预训练的BiLSTM参数,仅调整权重 ( s_k ) 和 ( gamma )。
○ 或在特定任务数据上微调部分BiLSTM层(如顶层)。
● 向量拼接:将ElMo向量与任务特定特征(如词袋、CNN特征)拼接,输入分类器。
典型应用场景
- 多义性处理
○ 例:“bank”在“river bank”(河岸)和“bank account”(银行)中生成不同向量。 - 复杂NLP任务
○ 问答系统(如SQuAD):捕捉问题与答案的语义关联。
○ 情感分析:区分“这部电影很烂”(负面)和“烂苹果不能吃”(中性)。
○ 命名实体识别:识别“Apple”作为公司名或水果名。 - 低资源语言任务
○ 通过跨语言预训练(如多语言ElMo),提升小语种模型效果。
优缺点与局限性
优点:
- 动态词向量:首次实现“一词多义”表明,解决静态词向量(如Word2Vec)的根本缺陷。
- 双向语境建模:同时思考上下文信息,优于单向模型(如GPT的自回归预训练)。
- 任务灵活性:通过加权组合各层向量,适配不同任务(如语法任务更依赖底层,语义任务依赖顶层)。
缺点:
- 计算成本高:多层LSTM训练和推理速度慢,难以处理长文本。
- 特征融合粗糙:加权求和方式未显式建模层间依赖,不如Transformer的自注意力机制高效。
- 深层优化不足:LSTM的梯度消失问题限制了模型深度(ElMo仅3层BiLSTM,而BERT有12/24层Transformer)。
优缺点的演进方向
架构升级:LSTM → Transformer
● BERT(2018):用双向Transformer替代LSTM,通过掩码语言模型(MLM)预训练,性能全面超越ElMo。
● GPT(2018):用单向Transformer(自回归)预训练,虽未双向但开启生成式预训练范式。
预训练任务创新
● ELMo的改善:后续模型如RoBERTa优化掩码策略(动态掩码、全词掩码)。
● 多任务预训练:XLNet结合自回归和自编码,通过排列语言模型解决BERT的预训练-微调差异。
参数规模与效率平衡
● 轻量级ElMo变体:如ALBERT通过参数共享压缩模型,保留语境表明能力。
● 动态路由机制:类似Mixture of Experts(MoE),根据输入动态激活部分网络,降低计算量。
跨模态与多语言扩展
● VisualELMo:将图像特征与语言模型融合,用于图文理解。
● XLM-R:在100+语言上预训练,通过共享子词空间实现跨语言迁移。
GPT(Generative Pre-trained Transformer)
GPT 是由 OpenAI 开发的一系列基于 Transformer 架构的预训练语言模型,主要用于自然语言生成任务。其核心思想是利用大量的无监督文本数据进行预训练,学习语言的通用模式和结构,然后通过微调(fine-tuning)或提示(prompting)的方式将其应用于特定的自然语言处理任务。
核心贡献
1.证明 “规模化” 的力量:参数量与数据量驱动性能提升
GPT 系列验证了 “更大模型 + 更多数据 = 更强能力” 的趋势,启发后续模型(如 PaLM、Claude)走向千亿级参数规模。
发现 “涌现能力”:当模型规模超过临界值,会突然获得小模型不具备的推理、规划等能力(如链式思维 Chain of Thought)。
大规模无监督预训练的可行性验证,在 GPT 之前,大多数 NLP 模型依赖于有监督学习,需要大量标注数据。GPT 通过无监督学习,利用海量的未标注文本数据,学习语言的通用特征。这种方法大大减少了对标注数据的依赖,降低了开发成本,同时提高了模型的泛化能力。
2.推动 “提示学习” 成为主流范式
展示了模型在零样本和少样本学习任务中的强劲能力。通过设计合适的提示,GPT 可以直接生成任务所需的输出,而无需针对每个任务进行微调。大幅降低 NLP 应用门槛
3.开启生成式 AI 的商业化浪潮
ChatGPT(基于 GPT-3.5)的爆发式应用推动生成式 AI 进入大众视野,催生文本生成、代码辅助(如 GitHub Copilot)、对话机器人等千亿级市场。
4.多模态与通用智能的探索
GPT-4 首次实现文本 + 图像的联合理解,为通用人工智能(AGI)提供了技术路径参考,后续模型如 GPT-4V 进一步强化视觉推理能力。
核心原理
● 预训练阶段:使用无监督学习,通过预测文本中的下一个单词来学习语言模型。这种任务称为“语言建模”(language modeling)。
● Transformer 架构:基于 Transformer 编码器(GPT-1、GPT-2)或解码器(GPT-3 及后续版本)架构,能够处理长文本序列并捕捉复杂的语义关系。
● 微调与提示:预训练模型可以通过微调(针对特定任务进行训练)或提示(通过设计特定的输入格式引导模型生成所需输出)的方式应用于各种自然语言处理任务。
工作流程
- 预训练阶段:
○ 数据收集:收集大量的文本数据,如书籍、网页、新闻文章等。
○ 预训练任务:使用语言建模任务,即预测文本中的下一个单词。例如,给定句子“今天天气很好,适合出去”,模型需要预测下一个单词可能是“散步”“游玩”等。
○ 模型训练:通过反向传播和梯度下降等优化方法,训练模型参数,使模型能够更好地预测下一个单词。 - 微调阶段(可选):
○ 任务特定数据:针对具体的自然语言处理任务(如情感分析、问答系统等),准备标注好的训练数据。
○ 模型微调:在预训练模型的基础上,使用任务特定的数据进行进一步训练,调整模型参数以适应特定任务。 - 提示阶段(可选):
○ 设计提示:根据任务需求设计特定的输入格式(提示),引导模型生成所需的输出。例如,对于问答任务,提示可以是“问题:…… 答案:”。
○ 模型推理:将设计好的提示输入模型,模型根据预训练知识生成回答。
典型应用场景
- 文本生成:
○ 创意写作:生成故事、诗歌、新闻报道等。
○ 内容创作:辅助撰写文章、博客、广告文案等。 - 问答系统:
○ 开放域问答:根据用户输入的问题,生成详细的答案。
○ 智能客服:自动回答常见问题,提供客户支持。 - 语言翻译:
○ 多语言翻译:将一种语言的文本翻译成另一种语言。 - 情感分析:
○ 文本情感判断:分析文本中的情感倾向(如正面、负面或中性)。 - 代码生成:
○ 编程辅助:生成代码片段、调试提议等。 - 教育与学习:
○ 语言学习:生成语法练习、词汇学习材料等。
○ 知识问答:协助学生解答学科问题。
优缺点与局限性
优点:
● 强劲的语言生成能力:能够生成高质量、连贯的文本,适用于多种自然语言处理任务。
● 广泛的适用性:通过微调或提示,可以应用于各种自然语言处理任务,无需针对每个任务重新训练模型。
● 预训练数据丰富:利用大量的无监督文本数据进行预训练,模型能够学习到丰富的语言知识和模式。
● 上下文理解能力强:能够根据上下文动态生成词向量,有效处理多义词和复杂语义。
缺点:
● 计算资源需求高:预训练和微调阶段需要大量的计算资源,对硬件要求较高。
● 训练成本高:训练一个大规模的 GPT 模型需要大量的时间、金钱和计算资源。
● 输出不可控:生成的文本可能存在偏差、错误或不符合用户期望的情况。
● 对数据质量敏感:预训练数据的质量直接影响模型的性能,如果数据中存在偏见或错误,模型也可能生成有问题的内容。
优缺点的演化
优化方向:
● 模型压缩:通过知识蒸馏、量化等技术,减小模型规模,提高推理效率。
● 多模态融合:结合图像、语音等多模态数据,提升模型的综合理解能力。
● 对齐与安全:通过更好的训练数据筛选和对齐机制,减少生成内容的偏差和错误。
替代技术:
● 其他预训练模型:如 BERT、T5 等,虽然在某些任务上与 GPT 有类似之处,但在双向上下文建模等方面有各自的优势。
● 强化学习与人类反馈:通过强化学习和人类反馈机制,进一步优化模型的生成内容,使其更符合人类的价值观和期望。
BERT(Bidirectional Encoder Representations from Transformers)
BERT 是由 Google 在 2018 年提出的一种预训练语言模型,基于 Transformer 架构,通过无监督学习的方式对大量文本数据进行预训练,以学习语言的通用特征和语义信息。BERT 的出现极大地推动了自然语言处理(NLP)领域的发展,成为许多 NLP 任务的基准模型。
核心贡献
- 双向上下文理解:BERT 是首个大规模应用的双向语言模型,能够同时思考上下文中的左侧和右侧信息来生成词的向量表明,在 BERT 之前,大多数语言模型(如 Word2Vec、GloVe 和早期的 RNN/LSTM)只能捕捉单向依赖关系(如从左到右或从右到左)。这限制了模型对复杂语义的理解能力。
- 预训练与微调范式的普及:提出了“预训练 + 微调”的范式,通过大规模无监督预训练学习通用语言知识,然后在特定任务上进行微调
- 掩码语言模型(MLM)任务的创新:引入了掩码语言模型(Masked Language Model, MLM)任务,通过随机掩盖部分单词并预测这些单词,学习单词之间的双向依赖关系
- 预测(NSP)任务的引入:在 BERT 之前,大多数语言模型只能处理单个句子的语义,无法捕捉句子之间的关系,NSP 任务使得 BERT 能够更好地处理句子对任务(如问答系统、自然语言推理等),提升了模型在这些任务上的性能.
核心原理
BERT 的核心思想是利用双向 Transformer 编码器架构来学习上下文相关的词向量表明。
BERT算法的输入输出如下图:输入文本,输出向量
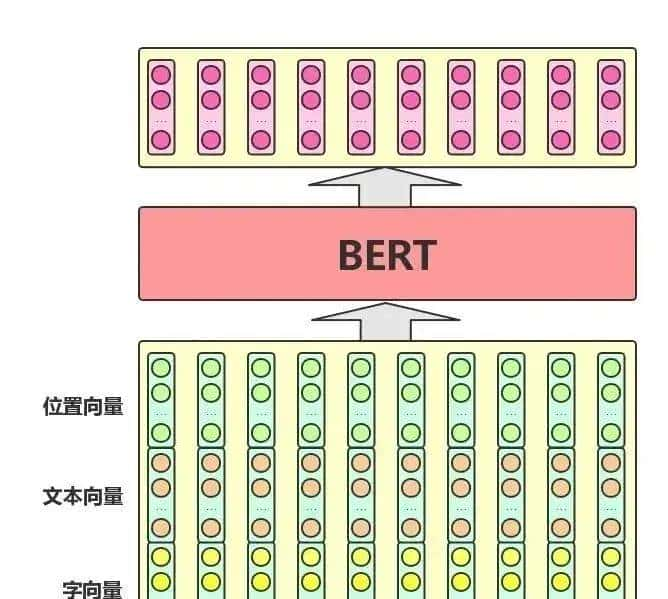
文本向量:该向量的取值在模型训练过程中自动学习,用于刻画文本的全局语义信息,并与单字/词的语义信息相融合
位置向量:由于出目前文本不同位置的字/词所携带的语义信息存在差异,因此,BERT模型对不同位置的字/词分别附加一个不同的向量以作区分
了解了BERT模型的输入/输出和预训练过程之后,我们来看一下BERT模型的内部结构。
前面提到过,BERT模型的全称是:BidirectionalEncoder Representations from Transformer,也就是说,Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分,因此,下面我们从Attention机制开始,介绍如何利用Attention机制构建Transformer模块,在此基础上,用多层Transformer组装BERT模型。
Attention机制
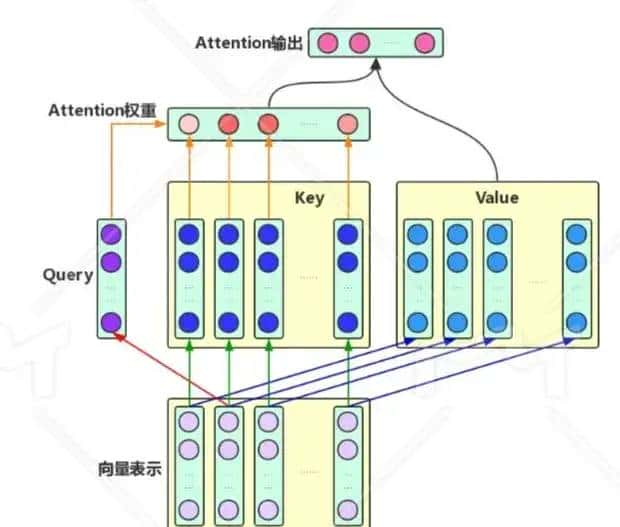
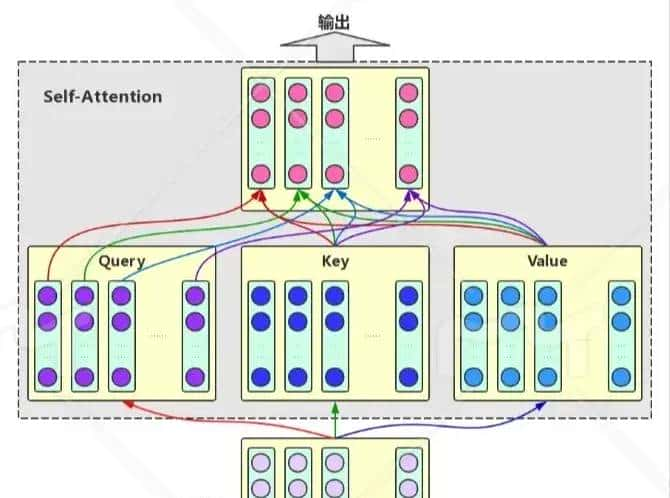
Attention机制的中文名叫“注意力机制”,顾名思义,它的主要作用是让神经网络把“注意力”放在一部分输入上,即:区分输入的不同部分对输出的影响。这里,我们从增强字/词的语义表明这一角度来理解一下Attention机制
Attention机制主要涉及到三个概念:Query、Key和Value。目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的类似性作为权重,把上下文各个字的Value融入目标字的原始Value中。
想象你在一个大型图书馆里:
- 查询(Query)就像你脑海中的问题或需求。列如,“我想了解人工智能”。
- 键(Key)就像每本书的标题或目录。它们是书籍内容的简要概括。
- 值(Value)就是书籍的实际内容。
目前,注意力机制的工作方式是: - 你带着你的问题(Query)在图书馆里走动。
- 你快速浏览每本书的标题和目录(Key),看看哪些可能与你的问题相关。
- 对于看起来相关的书,你会多花些时间翻阅其内容(Value)。
-
最后,你综合了所有相关书籍的信息,形成了对你问题的答案。
详细图如下
Self-Attention
对于输入文本,我们需要对其中的每个字分别增强语义向量表明,因此,我们分别将每个字作为Query,加权融合文本中所有字的语义信息,得到各个字的增强语义向量,如下图所示。在这种情况下,Query、Key和Value的向量表明均来自于同一输入文本,因此,该Attention机制也叫Self-Attenti on。
自注意力(Self-Attention)是注意力机制的一种特殊形式,它允许输入序列中的每个元素都能和序列中的其他元素进行交互。
想象一群人在开会讨论问题。每个人发言时,都会根据之前其他人说的内容来调整自己的发言。这就像自注意力的工作方式。
简单来说:
● 注意力机制主要用于处理输入和输出序列之间的依赖关系。
● 自注意力机制则专注于处理序列内部的依赖关系。
应用场景:
● 注意力机制一般在编码器-解码器结构中使用,作为连接两者的桥梁。例如,在机器翻译任务中,它协助模型在生成目标语言时关注源语言的相关部分。
● 自注意力机制可以在同一个模型中多次使用,是网络结构的一个组成部分。它在处理长序列时特别有效,如长文本理解或图像处理。
工作原理:
● 注意力机制计算输入序列和输出序列之间的相关性,为输入的不同部分分配不同的权重。
● 自注意力机制计算序列内部各元素之间的相关性,允许每个元素与序列中的所有其他元素进行交互。
信息处理方式:
● 注意力机制像人类大脑一样,在面对大量信息时,能够筛选出最重大的部分进行处理。
● 自注意力机制更像是序列中的每个元素都在相互”交谈”,相互理解彼此的重大性。
计算复杂度:
● 注意力机制的计算复杂度一般较低,由于它只在编码器和解码器之间进行一次计算。
● 自注意力机制的计算复杂度较高,由于它需要计算序列中每个元素与其他所有元素的关系。
灵活性:
● 自注意力机制比传统的注意力机制更加灵活,能够捕捉到更复杂的序列内部依赖关系。
详细图如下:
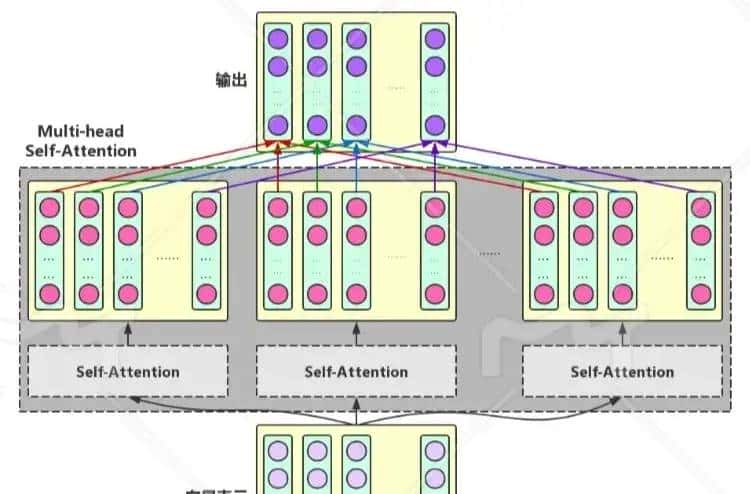
Multi-head Self-Attention
多头自注意力机制是自注意力的一个扩展,它允许模型同时从不同的角度来关注信息,为了增强Attention的多样性,进一步利用不同的Self-Attention模块获得文本中每个字在不同语义空间下的增强语义向量,并将每个字的多个增强语义向量进行线性组合,从而获得一个最终的与原始字向量长度一样的增强语义向量。
想象你在看一部复杂的电影。你可能会同时关注多个方面:人物的表情、对话的内容、场景的布置等。多头自注意力就是让模型也能够同时从多个角度来”看”输入数据。
可以把自注意力机制比作一个高效的会议:
● 每个与会者(输入元素)都有机会发言(Query)。
● 其他人根据自己的专业(Key)来决定是否应该仔细听(给予高的注意力分数)。
● 最后,每个人根据听到的内容(加权的Value)来更新自己的观点。
多头自注意力则像是同时进行多场平行的小组讨论
● 每个小组关注不同的主题
● 最后汇总所有小组的成果
详细图如下:
Transformer Encoder
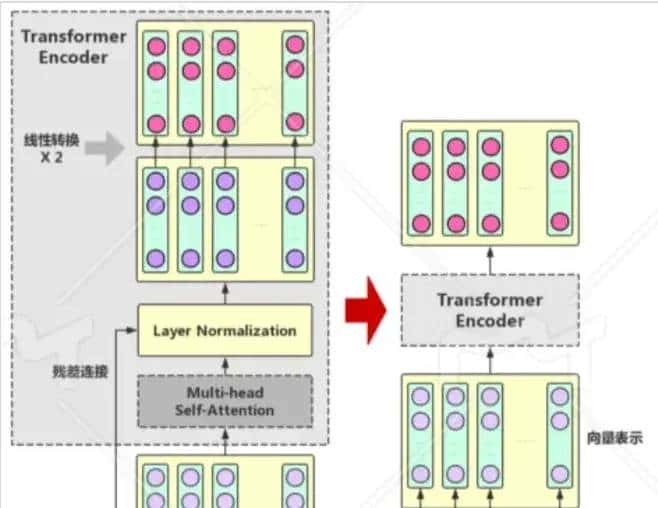
在Multi-headSelf-Attention的基础上再添加一些“佐料”,就构成了大名鼎鼎的Transformer Encoder。实际上,Transformer模型还包含一个Decoder模块用于生成文本,但由于BERT模型中并未使用到Decoder模块,因此这里对其不作详述。下图展示了Transformer Encoder的内部结构,可以看到,Transformer Encoder在Multi-head Self-Attention之上又添加了三种关键操作:
● 残差连接(ResidualConnection):将模块的输入与输出直接相加,作为最后的输出。这种操作背后的一个基本思考是:修改输入比重构整个输出更容易(“锦上添花”比“雪中送炭”容易多了!)。这样一来,可以使网络更容易训练。
● Layer Normalization:对某一层神经网络节点作0均值1方差的标准化。
● 线性转换:对每个字的增强语义向量再做两次线性变换,以增强整个模型的表达能力。这里,变换后的向量与原向量保持长度一样。
工作流程
- 预处理:
○ 对输入文本进行分词,使用 WordPiece 分词方法将文本转换为子词(subword)单元。
○ 在句子对的开头添加 [CLS] 标记,在句子之间添加 [SEP] 标记,用于区分不同的句子。 - 预训练阶段:
○ 掩码语言模型:随机掩盖部分单词,模型通过上下文预测被掩盖的单词。
○ 下一句预测:判断两个句子是否连贯。
○ 使用大量无监督文本数据进行预训练,学习语言的通用特征和语义信息。 - 微调阶段:
○ 对于具体的自然语言处理任务(如情感分析、问答系统等),在预训练模型的基础上添加任务特定的输出层。
○ 使用标注好的任务数据对模型进行微调,调整模型参数以适应特定任务。
典型应用场景
- 文本分类:
○ 情感分析(判断文本的情感倾向)。
○ 主题分类(判断文本的主题类别)。 - 问答系统:
○ 开放域问答(根据问题生成答案)。
○ 阅读理解(从给定的文本中提取答案)。 - 命名实体识别(NER):
○ 从文本中识别出人名、地名、组织名等实体。 - 语义类似度计算:
○ 判断两个句子之间的语义类似度。 - 文本生成:
○ 生成文本摘要、故事、新闻报道等。
优缺点与局限性
优点:
● 双向上下文理解:BERT 能够捕捉单词之间的双向依赖关系,生成的词向量能够更好地反映语义信息。
● 强劲的泛化能力:通过大规模无监督预训练,BERT 学习到了通用的语言特征,能够快速适应多种自然语言处理任务。
● 微调简单高效:在预训练模型的基础上进行微调,一般只需要少量的任务数据即可获得较好的性能。
● 多语言支持:BERT 提供了多语言版本(如 mBERT、XLM-R),能够处理多种语言的文本。
缺点:
● 计算资源需求高:预训练和微调阶段需要大量的计算资源,对硬件要求较高。
● 模型复杂度高:BERT 模型的参数量大,推理速度较慢,难以在资源受限的设备上实时运行。
● 对数据质量敏感:预训练数据的质量直接影响模型的性能,如果数据中存在偏见或错误,模型也可能生成有问题的内容。
● 难以解释:BERT 的内部工作机制较为复杂,难以解释其生成结果的具体缘由。
优缺点的演化方向
优化方向:
● 模型压缩:通过知识蒸馏、量化等技术,减小模型规模,提高推理效率。
● 多模态融合:结合图像、语音等多模态数据,提升模型的综合理解能力。
● 对齐与安全:通过更好的训练数据筛选和对齐机制,减少生成内容的偏差和错误。
替代技术:
● 更高效的预训练模型:如 ALBERT、DistilBERT 等,通过模型压缩和优化,提高了推理效率。
● 多任务学习模型:如 T5、GPT 等,通过多任务学习和提示学习,进一步提升了模型的性能和灵活性。
XLNet
XLNet 是一种基于 Transformer 架构的预训练语言模型,由杨植麟等人于 2019 年提出。其核心目标是解决 BERT 在预训练阶段的局限性(如 [MASK] 标记导致的预训练 – 微调差异),同时融合自回归(AR)和自编码(AE)模型的优势,实现更高效的双向语境建模。
核心贡献
- 预训练与微调的一致性:PLM 不需要引入 [MASK] 标记,避免了预训练和微调阶段的不一致性,使得模型在微调时能够更好地适应下游任务。
- 引入了双流自注意力机制:包括内容流(Content Stream)和查询流(Query Stream),其中内容流,处理上下文信息,生成上下文相关的表明。查询流基于内容流的输出,预测目标词。这种机制使得模型能够更高效地利用上下文信息,提升预测的准确性。
核心原理
核心思想包括:
● 排列语言建模(Permutation Language Modeling, PLM):通过对输入序列的所有可能排列进行建模,XLNet 能够学习到双向上下文信息。这与 BERT 的掩码语言模型(MLM)不同,PLM 不需要在预训练阶段引入 [MASK] 标记,从而避免了预训练和微调阶段的不一致性。
● 双流自注意力机制(Two-Stream Self-Attention):XLNet 使用内容流和查询流两种自注意力机制。内容流用于处理上下文信息,而查询流用于预测目标词,这使得模型能够更好地利用上下文信息。
● 相对位置编码:与 Transformer-XL 类似,XLNet 采用了相对位置编码,允许模型捕捉更长距离的依赖关系。
架构设计
XLNet 基于 Transformer-XL 架构,具有以下特点:
● 段级循环机制:通过在段间传播隐藏状态,模型能够跨段保留上下文信息,从而扩展上下文长度,捕捉更长期的依赖关系。
● 广义自回归目标:XLNet 使用广义自回归目标进行预训练,类似于 GPT 模型中使用的自回归目标,允许生成多样化且连贯的文本。
典型应用场景
XLNet 在多种自然语言处理任务上表现出色,包括但不限于:
● 文本分类:情感分析、新闻分类、客户服务自动化等。
● 问答系统:自动回答问题,生成详细的答案。
● 命名实体识别(NER):从文本中识别出人名、地名、组织名等实体。
● 文本生成:生成文本摘要、故事、新闻报道等。
优缺点与局限性
优点
● 双向上下文学习:通过排列语言建模,XLNet 能够学习到双向上下文信息,而不需要引入 [MASK] 标记。
● 长文本处理能力:借助 Transformer-XL 的段级循环机制和相对位置编码,XLNet 能够有效处理长文本。
● 预训练与微调的一致性:解决了 BERT 中预训练和微调阶段不一致的问题,提高了模型在下游任务中的性能。
缺点
● 训练复杂度高:排列语言建模增加了训练的复杂度,导致收敛速度较慢。
● 计算资源需求大:与 BERT 类似,XLNet 的训练和推理需要大量的计算资源。
优缺点的演化方向
● 降低计算复杂度:原始 XLNet 的排列组合计算量随序列长度呈指数增长,后续通过稀疏排列(如 SparseXLNet)优化;
● 结合生成任务:XLNet-Base 被用于文本生成任务(如摘要、对话),弥补 BERT 在生成场景的不足。
SimCSE(Simple Contrastive Learning of Sentence Embeddings)
是一种基于对比学习的句向量表征框架,发表于 EMNLP 2021。它旨在通过对比学习提升句子嵌入向量的质量,解决传统方法(如 BERT 的 [CLS] 向量)在文本匹配任务中表现不佳的问题。
核心贡献
- 解决各向异性问题:通过对比学习,使预训练 Embedding 的空间分布更均匀,解决了各向异性问题,提升了句向量表征的质量。
- 无需大量标注数据:无监督的 SimCSE 无需额外标注数据,仅利用标准 dropout 操作构造正样本,就能显著提高句子嵌入的质量,降低了数据获取成本。
- 性能提升显著:无论是无监督还是有监督的 SimCSE,在语义文本类似性(STS)任务等多个自然语言处理任务上都超越了之前的先进方法,能有效提升模型在文本类似性任务上的性能。
核心原理
SimCSE 的核心在于对比学习,通过拉近正样本对的距离,拉远负样本对的距离,从而学习到更好的句子嵌入向量。它包含无监督和有监督两种方法。
● 无监督方法:
○ 使用 Dropout 数据增强技术,将同一个句子输入模型两次,每次应用不同的 Dropout 掩码,生成两个不同的嵌入向量作为正样本对。
○ 负样本则是同一个 batch 中的其他句子。
○ 对比学习的损失函数为 InfoNCE 损失,通过计算正样本对和负样本对的余弦类似度来优化模型。
● 有监督方法:
○ 借助自然语言推理(NLI)数据集,将蕴含(entailment)样本作为正样本对,矛盾(contradiction)样本作为负样本对。
○ 这种方法利用了标注数据,能够更直接地优化句子嵌入向量。
典型应用场景
SimCSE 在多种自然语言处理任务中表现出色,包括但不限于:
● 文本类似度计算:用于判断两个句子或文本片段的语义类似度。
● 问答系统:通过计算问题和答案之间的类似度来匹配问题和答案。
● 文本分类:利用句子嵌入向量进行文本分类。
● 信息检索:在大规模文本数据中检索与查询语义相关的文本。
优缺点与局限性
优点
● 解决各向异性问题:通过对比学习,SimCSE 能够改善预训练嵌入向量的各向异性问题,使嵌入空间分布更均匀。
● 简单高效:无监督方法仅依赖 Dropout 数据增强,无需额外标注数据,即可显著提升句子嵌入质量。
● 灵活适用:支持无监督和有监督两种方式,可根据具体任务选择合适的方法。
缺点
● 数据增强的局限性:无监督方法依赖 Dropout 数据增强,可能在某些情况下不够稳定。
● 对比学习的复杂性:对比学习的训练过程相对复杂,需要较大的 batch size 和计算资源。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...