

一、为什么要把「配置管理」和「日志」放在一起聊?
如果你在一线写一段时间 Java / Spring 项目,很快会发现一个现实:
线上 90% 的问题,不是代码写错,而是「配置没管好」+「日志没打好」。
典型的几种场景:
- 配置改了不生效: 从 application.yml 改到 K8s ConfigMap,又加了一层 Nacos / Consul,最后谁覆盖谁,完全说不清,只能靠猜。
- 配置打错导致事故: 列如把 spring.datasource.url 写错一个字母,数据库连不上;把 SPRING_PROFILES_ACTIVE 打成了 prodution,线上直接跑成默认配置。
- 日志要么太少,要么太多: 日志太少 → 线上一出问题只剩“猜”; 日志太多 → ELK / Loki 被刷爆,重大信息淹没在一片 INFO 里。
而云原生时代把这两个问题又放大了一遍:
- 配置不再只是一个本地 application.yml,而是: 镜像里的默认配置 + 环境变量 + ConfigMap + Secret + 各种配置中心……
- 日志也不再只是一个本地 logs/app.log,而是: 容器 stdout → Sidecar / Agent → 日志平台 → 报警系统……
配置,是系统的“输入”;日志,是系统的“输出”。 一个负责告知程序「该怎么跑」,一个负责告知人类「它刚刚是怎么跑的」。
更关键的是,在 Spring / Spring Boot 的世界里:
- 配置管理有清晰的底层抽象:Environment + PropertySource
- 日志有统一的抽象和门面:Logger + Appender,上层用 SLF4J,底层可以是 Logback / Log4j2 / JUL
当你真正理解这两套“抽象 + 机制”之后:
- 云原生给你的各种能力(ConfigMap / Secret / Nacos / Vault / Cloud Config / Loki / ELK……),在你眼里都只是不同的配置源 / 不同的日志后端;
- 换云厂商、换配置中心、换日志平台,更多是运维侧的变更,而不是“重写一遍 Java 代码”。
所以,这篇文章刻意把「配置管理」和「日志」放在一起聊,目标只有一个:
帮你建立一套统一的“世界观”:
Spring 里配置怎么流动,日志怎么流动,它们如何一起在云原生架构里协同工作。
二、Java 配置世界观:从 Java SE 到 Spring Boot
先把一个核心观点放在前面:
Spring Boot 的各种“外部化配置”魔法,本质上只是:
把各种配置源封装成 PropertySource,按顺序塞进 Environment。
谁优先级高,谁就排在更靠前的位置(或者后插覆盖前面)。
理解这一点,你就能从 Java SE 一路顺畅走到 Spring Boot、Kubernetes、配置中心。
2.1 Java SE 时代的配置手段:赤裸裸的基础能力
在没有 Spring 的年代,Java 应用要读配置,手里就三把“原始武器”:
1)系统属性(System Properties)
java -Dapp.env=prod -Dapp.threadPoolSize=32 -jar app.jarString env = System.getProperty("app.env");
int threadPoolSize = Integer.getInteger("app.threadPoolSize", 8);特点:
- 通过 -Dkey=value 在 JVM 启动时指定;
- 对整个 JVM 进程是全局的。
2)环境变量(Environment Variables)
export APP_ENV=prod
java -jar app.jarString env = System.getenv("APP_ENV");特点:
- 由操作系统 / 容器注入;
- 适合做“云原生式”的配置注入(Docker / K8s 很喜爱用它)。
3)属性文件(.properties)
app.env=prod
app.datasource.url=jdbc:mysql://localhost:3306/appProperties props = new Properties();
try (InputStream in = getClass().getResourceAsStream("/app.properties")) {
props.load(in);
}
String env = props.getProperty("app.env");特点:
- 人类可读、易于版本管理;
- 但没有统一的优先级机制,多个文件时要自己决定“谁覆盖谁”。
你可以把这一层理解为:Java 提供的都是“原材料”,没有搭好“整体厨房”。
2.2 Spring Environment & PropertySource:给配置世界加一个「统一抽象」
Spring 做的第一件事,就是定义了一个统一入口:Environment。
核心接口:
public interface Environment extends PropertyResolver {
String[] getActiveProfiles();
boolean acceptsProfiles(String... profiles);
}它内部维护了一个 MutablePropertySources,可以简单理解为:
class MutablePropertySources implements Iterable<PropertySource<?>> {
// 有序列表
List<PropertySource<?>> propertySourceList;
}而每一个 PropertySource<?>,就是一个配置来源,列如:
- MapPropertySource(“systemProperties”, System.getProperties())
- SystemEnvironmentPropertySource(“systemEnvironment”, System.getenv())
- OriginTrackedMapPropertySource(“applicationConfig: [classpath:/application.yml]”, …)
- 自定义的 NacosPropertySource / ConsulPropertySource / VaultPropertySource……
当你通过 Environment.getProperty(“server.port”) 取值时,底层做的事情实则超级简单:
for (PropertySource<?> ps : propertySources) {
Object value = ps.getProperty("server.port");
if (value != null) {
return convertIfNecessary(value);
}
}
return null;也就是说:
配置优先级 = propertySources 列表的顺序;
取值时,谁先给出非空值就用谁。
这一下子就解决了 Java SE 时期的几个痛点:
- 有了统一入口:无论配置来自文件、环境变量还是配置中心,代码都只关心 Environment;
- 有了统一优先级:通过 PropertySource 的顺序来表达“谁能覆盖谁”。
2.3 Spring Boot:把「外部化配置」做到极致
有了 Environment + PropertySource 的抽象,Spring Boot 在此基础上做了三件超级重大的事:
1)定义「配置优先级」规则,文档 + 源码双重兜底
典型优先级(从低到高,略化版):
- SpringApplication#setDefaultProperties 设置的默认值;
- @PropertySource 引入的属性文件;
- 配置文件(application.yml / application-*.yml,外部 > 内部,profile > 通用);
- 环境变量 / 系统属性;
- 命令行参数(–server.port=9000 等)。
你在本地改 application-dev.yml、在 Docker 里用 -e SPRING_DATASOURCE_URL=…,在 K8s 里用 ConfigMap 配 SPRING_PROFILES_ACTIVE——这些行为之所以“理所当然地生效”,靠的就是这套优先级链。
2)支持多种配置格式和 profile 机制
同时支持 .properties 和 .yml;支持 application-{profile}.yml,通过:
- spring.profiles.active=dev(配置文件内)
- SPRING_PROFILES_ACTIVE=prod(环境变量)
- –spring.profiles.active=test(命令行) 来选择激活哪个环境。
这直接映射到云原生场景:镜像内部带上多套 profile,环境差异通过外部指定 profile 与配置源来实现。
3)引入 ConfigData / spring.config.import 机制,方便接各种配置中心
例如:
spring:
config:
import:
- "optional:consul:"
- "optional:configserver:"
这些 import 背后,实则就是在启动阶段,通过一个 ConfigDataEnvironmentPostProcessor,再往 Environment 里插入更多 PropertySource,列如:
- 来自 Git 的配置;
- 来自 Consul / Nacos / Zookeeper 的配置;
- 来自 Vault / 云厂商 Secret Manager 的敏感配置……
机制没有变:只是多了几种“配置源的实现”。
2.4 小结:从 Java SE 到 Spring Boot,配置世界观升级了什么?
如果用一句话概括这段演化:
Java SE 给了原材料:系统属性、环境变量、属性文件;
Spring 给了统一抽象:Environment + PropertySource;
Spring Boot 给了一整套“云原生友善”的规则和实现: 外部化配置、优先级链、Profile、ConfigData、配置中心集成。
当你脑子里对这条演化线是清晰的:
- 再面对「Docker 环境变量没生效」「K8s ConfigMap 覆盖不了镜像配置」之类的问题时,你只需要问一句: “它们在 PropertySource 列表里的顺序到底是怎样的?”
- 再思考引入 Nacos / Consul / Config Server / Vault 时,你只需要思考: “它们会以什么形式挂到 Environment 上?优先级排在哪儿?”
三、云原生视角:Spring 配置是如何与 Docker / Kubernetes 整合的?
前一节我们讲的是“Spring 内部怎么看配置”:Environment + PropertySource。 这一节换个视角:站在 Docker / Kubernetes 这一侧,看它们怎么把配置“喂”给 Spring。
核心思路只有一句话:
容器镜像尽量做成「不可变工件」,所有环境差异通过外部配置注入。
而 Spring 天生就擅长吃「外部配置」——环境变量、命令行、文件、配置中心。
所以整合的过程,实则就是:把 Docker / K8s 的能力,映射到 Spring 支持的配置源上。
3.1 镜像不可变:配置必须外部化
在传统部署里,你可能会直接改 application-prod.yml 然后重启服务; 但到了容器世界,一个镜像最好是:
- 一次构建,多环境复用;
- 不要由于 QA 改了一个小配置就重新打镜像。
这意味着:
- 镜像里可以放默认配置(开发用、通用配置);
- 所有环境差异(数据库地址、消息队列地址、开关位、外部服务端点……)都必须放到镜像外面,交给容器编排系统来注入。
而恰好,Spring Boot 的外部化配置规则天然适配这种模式:
- 镜像里:application.yml 只写默认值;
- 镜像外:用环境变量 / 挂载文件 / 配置中心覆盖掉这些默认值。
3.2 Docker 层面的整合:环境变量和命令行参数是第一阶武器
我们先不看 K8s,先看最小单位:单个 Docker 容器。
方式一:环境变量 + Spring Boot 映射规则
docker run
-e SPRING_PROFILES_ACTIVE=prod
-e SPRING_DATASOURCE_URL=jdbc:postgresql://db:5432/app
-e SPRING_DATASOURCE_USERNAME=appuser
-e SPRING_DATASOURCE_PASSWORD=secret
your-org/app:1.0.0
Spring Boot 会做几件事:
- 把所有环境变量读进 System.getenv();
- 封装为 SystemEnvironmentPropertySource;
- 按自己的命名规则,把 SPRING_DATASOURCE_URL 映射到配置属性 spring.datasource.url;
- 由于环境变量的优先级很高,自然可以覆盖 application.yml 中的同名配置。
好处是:
- 不用改代码,不用改镜像,只要改 Docker 启动参数;
- 超级符合 12-Factor 里 “Config in environment” 的理念。
方式二:命令行参数(Command Line Args)
docker run your-org/app:1.0.0
--spring.profiles.active=prod
--server.port=9000
--logging.level.com.example.payment=DEBUG命令行参数在 Spring Boot 的配置优先级里属于“顶级选手”:
- 被封装为一个 CommandLinePropertySource;
- 放在 PropertySource 链比较靠后的位置(优先级高),可以覆盖环境变量和配置文件。
小结一下 Docker 这层:
在没有任何额外 Spring Cloud 依赖的前提下,你已经可以用:
- 镜像内 application.yml + 环境变量 + 命令行参数 搞定绝大多数“多环境配置”的需求。
3.3 Kubernetes:ConfigMap / Secret 变成 Spring 的配置源
到了 Kubernetes,一般不会直接在 Deployment 里写一堆 env: name: value, 而是会用 ConfigMap + Secret 来管理配置。
这两个东西跟 Spring 的整合,主要有两种方式。
3.3.1 ConfigMap / Secret → 环境变量(最常用,也最简单)
ConfigMap 定义:
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
SPRING_PROFILES_ACTIVE: "prod"
SPRING_DATASOURCE_URL: "jdbc:postgresql://postgres:5432/app"
SPRING_DATASOURCE_USERNAME: "appuser"
---
apiVersion: v1
kind: Secret
metadata:
name: app-secret
type: Opaque
stringData:
SPRING_DATASOURCE_PASSWORD: "super-secret"Deployment 注入:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app
spec:
template:
spec:
containers:
- name: app
image: your-org/app:1.0.0
envFrom:
- configMapRef:
name: app-config
- secretRef:
name: app-secretK8s 做的事情:
- 把 ConfigMap / Secret 里的 key/value 注入成容器环境变量。
Spring Boot 做的事情:
- 像前面 Docker 那节一样,从环境变量构建 SystemEnvironmentPropertySource;
- 自动把 SPRING_… 映射为 spring…. 配置;
- 再通过 PropertySource 优先级,覆盖掉 application.yml 中的默认值。
你写的 Java 代码完全不用关心这些配置从哪来的,只管 @ConfigurationProperties / @Value 拿值就行。
3.3.2 ConfigMap → 文件挂载 + spring.config.additional-location
有些团队更偏爱“文件型配置”,列如:
- 需要给非 Spring 的程序共享这个配置;
- 或希望 ConfigMap 直接就是一份 application-prod.yml,一目了然。
这种情况,可以把 ConfigMap 挂载到容器内某个目录,然后让 Spring Boot 额外扫描该目录。
ConfigMap:
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config-file
data:
application-prod.yml: |
server:
port: 8080
spring:
datasource:
url: jdbc:postgresql://postgres:5432/app
username: appuserDeployment:
volumeMounts:
- name: config
mountPath: /config
volumes:
- name: config
configMap:
name: app-config-fileSpring Boot 启动参数:
java -jar app.jar
--spring.profiles.active=prod
--spring.config.additional-location=optional:file:/config/Spring Boot 会:
- 把 /config/application-prod.yml 当成额外的 ConfigData Source;
- 生成新的 PropertySource,优先级高于 jar 内部的配置文件;
- 最终在 Environment 里形成一条清晰的覆盖链:
jar 内 application.yml < jar 内 application-prod.yml < /config/application-prod.yml
3.4 再进一步:Spring Cloud Kubernetes / Config / Consul / Vault
上面这两种方式已经足够应付许多中小项目了,但在更复杂的云原生场景里,你可能还会遇到:
- 多个服务共享一套配置;
- 需要动态刷新配置(不重启 Pod);
- 配置有版本、灰度、审计要求。
这时候就轮到各种“配置中心”登场了,例如:
- Spring Cloud Kubernetes Config:直接把 ConfigMap/Secret 当配置中心用;
- Spring Cloud Config:Git 仓库做配置源;
- Spring Cloud Consul / Nacos / etcd:KV 存储做配置中心;
- Spring Cloud Vault / KMS / Secrets Manager:专门负责密钥和敏感配置。
从 Spring / Spring Boot 的角度看,它们做的事高度类似:
- 在启动早期,通过 spring.config.import 或特殊的 EnvironmentPostProcessor;
- 从对应的后端(K8s API / Git / Consul / Vault……)拉取配置;
- 封装成一个个 PropertySource;
- 按约定好的优先级插入到 Environment 中;
- 可选地支持:配置变更 → 触发 @RefreshScope Bean 刷新。
换句话说:
不管后端是 K8s ConfigMap,还是 Consul/Nacos,还是 Vault / Cloud Config,
对 Spring 来说,永远只是多个不同实现的 PropertySource。
这就是把“配置管理”从具体技术细节中解耦出来的真正威力。
四、Java 日志底层结构:Logger + Appender + Filter + Formatter
讲完“配置”的世界观,来看看“日志”这边。 有一个超级重大的感受:
换成任何一个 Java 日志框架(JUL / Log4j / Logback / Log4j2),
你看到的结构,基本都是同一套骨架: Logger → LogEvent → Appender → Layout/Formatter + Filter。
掌握这套骨架,你就不容易被各种框架的配置细节搞晕。
4.1 抽象模型:所有 Java 日志框架都在玩同一套东西
可以先用一张“脑补图”来记忆:
业务代码 ──> Logger ──(LogEvent)──> [Filter?] ──> Appender ──> 输出端
│
└─> 父 Logger(可选,向上冒泡)拆开来说:
1)Logger(日志记录器)
按名字组织成一棵树:
- root
- com
- com.example
- com.example.service.UserService
每个 Logger 一般有:
- level:当前日志级别(TRACE / DEBUG / INFO / WARN / ERROR)
- appenders:本 Logger 直连的输出器列表
- additivity / useParentHandlers:是否继续往父 Logger 传递事件
2)LogEvent / LogRecord(日志事件)
一次 logger.info(“order {} created”, orderId) 实际上会构造一个事件对象,包含:
- 时间戳;
- 线程名;
- Logger 名;
- Level;
- 日志消息(字符串或模板+参数);
- Throwable(异常栈);
- MDC / ThreadContext(当前上下文,如 requestId / userId 等)。
3)Filter(过滤器)
- 细粒度控制:这条日志要不要过?
- 可以挂在 Logger、Appender 上;
- 可以根据 Level、线程、MDC、甚至自定义字段做复杂判断。
4)Appender / Handler(输出器)
真正把日志写出去的地方;
常见类型:
- ConsoleAppender(控制台,stdout/stderr)
- FileAppender / RollingFileAppender(文件 / 滚动文件)
- AsyncAppender(异步队列)
- KafkaAppender、SocketAppender、HTTP Appender 等(发到远程服务)
5)Layout / Formatter(格式化器)
- 决定最后写出来的文本格式或 JSON 结构;
- 列如 Logback 中常见的 %d{HH:mm:ss.SSS} %-5level [%thread] %logger{36} – %msg%n;
- 也有专门做 JSON 日志的 Layout,如 LogstashEncoder。
这一套抽象,对应到代码里一般是类似这样的调用链:
logger.info("user {} created", userId);
// 伪代码展开:
if (logger.isInfoEnabled()) { // 1. 快速 level 判断
LogEvent event = new LogEvent(...); // 2. 构造事件对象
logger.log(event); // 3. 交给 logger 处理
}
// logger.log(...) 内部大致:
for (Appender appender : this.appenders) {
if (appender.passesFilters(event)) { // 4. 过滤器检查
appender.append(event); // 5. 写出(同步/异步)
}
}
if (this.additivity) { // 6. 是否传给父 logger
parent.logger.log(event);
}不同框架的类名不同,性能优化方式不同,但这个“管线结构”是一致的。
4.2 JDK 自带 java.util.logging(JUL):最基础的那一版
JUL 是 Java SE 里自带的日志实现,许多框架(尤其是早期或强调零依赖的)会用它作为默认 logger。
关键类结构可以对应到刚才的抽象模型:
java.util.logging.Logger
- 对应 Logger;
- 通过 Logger.getLogger(“com.example”) 获取;
- 有 log(Level, String)、info()、warning() 等方法;
- 有 setLevel()、addHandler()、setUseParentHandlers(boolean)。
java.util.logging.LogRecord
- 对应 LogEvent,记录一次日志的所有信息。
java.util.logging.Handler
- 对应 Appender;
- 常见实现:ConsoleHandler、FileHandler、SocketHandler、MemoryHandler 等。
java.util.logging.Filter
- 对应 Filter;可以挂在 Logger 或 Handler 上。
java.util.logging.Formatter
- 对应 Layout / Formatter;
- 如 SimpleFormatter、XMLFormatter。
java.util.logging.LogManager
- 管理所有 Logger;
- 负责加载 logging.properties 配置文件;
- LogManager.getLogManager().getLogger(“”) 返回 root logger。
一个简单的 logging.properties 例子:
# 根 logger 级别
.level=INFO
# 指定某个包的级别
com.example.level=FINE
# 配置根 logger 使用的 Handler
handlers= java.util.logging.ConsoleHandler
# ConsoleHandler 的级别和格式
java.util.logging.ConsoleHandler.level=INFO
java.util.logging.ConsoleHandler.formatter=java.util.logging.SimpleFormatter虽然目前生产环境你大致率不会直接用 JUL,但它有两个价值:
- 它是 Java 平台上日志机制的最基础实现,许多容器(Tomcat 等)都跟它打过交道;
- 理解它,有助于你看懂各种“jul-to-slf4j”、“log4j-jul”之类的桥接包,理解日志是怎样“从一个世界导向另一个世界”的。
4.3 从 JUL 到 Logback / Log4j2:在同一骨架上进化
后来的 Log4j、Logback、Log4j2 做的事情,本质上是在同一套骨架上不断增强:
- 更灵活、强劲的配置能力(XML / YAML / Groovy / JSON);
- 性能优化(无锁队列、异步 appender、垃圾回收友善等);
- 更丰富的输出方式(文件滚动策略、归档、压缩、多目标路由等);
- 更强的扩展性(自定义 Appender / Filter / Layout / 插件体系)。
但你会发现,它们的核心概念还是那几个:
- Logger:树状组织 + 级别控制;
- Appender:输出目的地;
- Filter:过滤规则;
- Layout / Encoder:格式化;
- LoggerContext / Configuration:管理整套配置与状态。
这就是为什么我们在项目里可以做到:
代码层只依赖 SLF4J(一个统一门面),
然后在不同项目 / 不同环境里自由选择 Logback 或 Log4j2 作为实现, 而业务日志调用完全不用改。
五、Facade 思想:为什么项目里只写 SLF4J 就够了?
前面我们已经拆过日志的“骨架”,目前来回答一个很现实的问题:
为什么目前大家几乎清一色推荐「代码里只用 SLF4J」,而不是直接依赖 Logback / Log4j2?
这背后就是经典的 Facade(门面)模式。
5.1 Facade vs 实现:先把角色分清
在 Java 日志生态里,大致有两类东西:
1)Facade(门面 / 抽象层)
典型代表:
- SLF4J(Simple Logging Facade for Java)
- 较老的 commons-logging
- 某些容器 / 框架内部用的 JBoss Logging
特点:
- 只定义接口,不负责真正写日志;
- 不关心日志“写到哪儿、怎么写”,只描述“我要打日志”。
2)具体实现(Implementation)
典型代表:
- Logback
- Log4j 2
- JDK 自带的 java.util.logging(JUL)
- 老的 Log4j 1.x(已过时)
特点:
- 提供 Logger、Appender、Layout 等具体实现;
- 决定性能、配置方式、输出能力。
Facade 做的是“统一 API”;实现做的是“干脏活”。
5.2 为什么业务代码只依赖 SLF4J 就够了?
假设你直接在业务代码里写的是 Logback 的 API:
import ch.qos.logback.classic.Logger;
import org.slf4j.LoggerFactory;
Logger log = (Logger) LoggerFactory.getLogger(MyService.class);
log.info("...");当你有一天想从 Logback 换到 Log4j2 时,会发生什么?
- 所有 import 都得改;
- 有些 API 名称不一样;
- 某些高级用法/扩展点甚至根本迁不动。
而如果你一开始就只用 SLF4J 的接口:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyService {
private static final Logger log = LoggerFactory.getLogger(MyService.class);
public void doSomething(String userId) {
log.info("Process user {}", userId);
if (log.isDebugEnabled()) {
log.debug("Detail for user {} ...", userId);
}
}
}那么:
- 要换实现,只需要在 依赖和配置层面 换掉 Logback → Log4j2;
- 业务代码完全不用改一行。
这就是为什么说:
Facade 把“如何打日志”的问题,从“写代码”移到了“配依赖 + 写配置文件”这一层。
对一个中大型项目,或者需要长期维护的 SaaS 系统,这一点超级关键。
5.3 一个典型的依赖搭配:SLF4J + Logback
以 Spring Boot 默认的组合为例:
- org.slf4j:slf4j-api(日志门面)
- ch.qos.logback:logback-classic(实现 + 对 SLF4J 的绑定)
Maven 或 Gradle 里大致就是:
<!-- Spring Boot starter 里已经隐式包含了这些,一般不用你手动加 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</dependency>spring-boot-starter-logging 会自动拉进:
- slf4j-api
- logback-classic
- 一些桥接包(把 JUL / JCL 日志导入 SLF4J)
然后你的业务代码只 import SLF4J:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;配置则写在 logback-spring.xml 或 application.yml 里, 切换实现只是换一下 starter:
- 想用 Log4j2:排除 spring-boot-starter-logging,改用 spring-boot-starter-log4j2;
- 想用纯 JUL:也可以自定义 LoggingSystem。
代码完全不动,日志实现可以自由更换,这就是 Facade 带来的最大价值。
5.4 桥接包的作用:把“野生日志”统一收口
真实项目里,不是所有依赖都乖乖用 SLF4J,有些老库可能:
- 用 JUL(java.util.logging);
- 用 commons-logging;
- 用 Log4j 1.x。
如果不做处理,你会遇到:
- 一部分日志走 SLF4J → Logback;
- 一部分日志走 JUL → 控制台;
- 又有一部分走 Log4j 1.x → 自己的文件;
整个项目日志像散落各处的水管,维护极其痛苦。
解决方案就是桥接(bridge):
- jul-to-slf4j:把 JUL 的日志转到 SLF4J;
- jcl-over-slf4j:把 commons-logging 的日志转到 SLF4J;
- log4j-to-slf4j:把 Log4j 的 API 调用转到 SLF4J。
最终形成:
所有日志 API → 全部汇聚到 SLF4J → 由一个具体实现(Logback / Log4j2)真正落地。
这就像是:
- 项目里大家说的方言再多,最后都统一翻译成“普通话(SLF4J)”,
- 然后由你选的一个“播报系统”(Logback / Log4j2)负责对外广播。
六、日志动态配置:从配置文件扫描到 Actuator 在线调级
前面我们讲的是“日志的结构”和“Facade 的好处”。 目前回到一开始关心的一个点:日志动态配置。
目标:在不重启服务的情况下,临时改变日志行为(尤其是级别),用完再恢复。
6.1 动态日志配置到底解决什么痛点?
几个典型场景:
1)线上问题偶现,DEBUG 没开,线索不足
- 你总不能为了开 DEBUG 重启所有 Pod,还要改镜像 / 改配置;
- 更糟糕的是,一旦全局 DEBUG,日志量爆炸,磁盘 / 日志平台扛不住。
2)灰度排障
- 只想对某一批实例、某一个业务模块打开更详细的日志;
- 故障排完立刻拉回 INFO。
3)动态调优日志输出
- 某条日志过于频繁,想在运行时降低级别或干脆关掉;
- 临时增加一个 appender,把特定日志打到单独的文件做审计。
这些都要求“在线调整,不重启生效”。
而这正好对应日志系统的两个可变点:
- Logger 的 level;
- Logger / Appender 的绑定关系(往哪里写)。
6.2 Logback / Log4j2:基于配置文件的“自动热加载”
先看最基础、最直观的一种方式:配置文件扫描(reload on change)。
6.2.1 Logback 的扫描机制
在 logback-spring.xml 或 logback.xml 里,你可以这么写:
<configuration scan="true" scanPeriod="30 seconds">
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<logger name="com.example.payment" level="INFO" additivity="false">
<appender-ref ref="CONSOLE" />
</logger>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>关键点:
- scan=”true”:开启配置文件扫描;
- scanPeriod=”30 seconds”:每 30 秒检查一次配置文件是否变化。
当你线上修改了 logback-spring.xml(列如把 com.example.payment 调成 DEBUG), Logback 会:
- 监测到文件时间戳变化;
- 重新解析配置;
- 重建 LoggerContext(Logger 树、Appender 等);
- 后续新日志按新配置处理。
优点:
- 实现简单,通用,不依赖 Spring 生态;
- 可以调整的不仅仅是 level,还可以改 pattern、appender 等等。
缺点:
- 需要能改配置文件(容器里一般要配挂载卷);
- 生效有一点延迟(取决于 scanPeriod);
- 重建 LoggerContext 的过程要小心,配置写错可能导致日志“短暂失声”。
6.2.2 Log4j2 的 monitorInterval 与 API 方式
Log4j2 的 XML 配置里有类似的东西:
<Configuration monitorInterval="30">
<!-- appenders, loggers... -->
</Configuration>- monitorInterval=”30″ 表明每 30 秒检查配置文件变更;
- 一旦检测到变化,重新加载配置。
除此之外,Log4j2 还提供了编程方式改 level,例如:
import org.apache.logging.log4j.core.config.Configurator;
Configurator.setLevel("com.example.payment", Level.DEBUG);这就给了你通过管理接口 / 自定义 API 动态调级的能力—— Spring Boot Actuator 正是借助这类 API 做“在线调级”的。
6.3 Spring Boot 的 LoggingSystem:统一动态控制入口
在 Spring Boot 的世界里,又多了一层抽象:LoggingSystem。
它会根据 classpath 上的依赖,选择对应实现:
- 有 Logback → 使用 LogbackLoggingSystem
- 有 Log4j2 → 使用 Log4J2LoggingSystem
- 啥都没有 → 退回到 JUL
它对外提供统一的操作,例如:
- 设置某个 logger 的 level;
- 初始化 / 重新初始化日志系统。
你平时在 application.yml 里写的这些:
logging:
level:
root: INFO
com.example.payment: DEBUG本质上就是在启动时,Spring Boot 读取这些配置,然后调用 LoggingSystem 设置对应 Logger 的 level。
而当你启用 Actuator 的 /actuator/loggers 端点时, Spring Boot 也是借助 LoggingSystem 来完成“在线调级”。
6.4 Actuator /actuator/loggers:最实用的在线调级方式
在 Spring Boot 项目里,只要引入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>并在配置里打开 loggers 端点(例如只对内网开放):
management:
endpoints:
web:
exposure:
include: health,info,loggers你就自动获得了一个超级好用的“动态日志控制台”。
1)查看当前所有 logger 及其级别
GET /actuator/loggers返回类似:
{
"levels": ["OFF", "ERROR", "WARN", "INFO", "DEBUG", "TRACE"],
"loggers": {
"ROOT": {...},
"com.example": {...},
"com.example.payment": {
"configuredLevel": "DEBUG",
"effectiveLevel": "DEBUG"
}
}
}2)查看某个 logger 的详情
GET /actuator/loggers/com.example.payment3)在线调整某个包 / 类的日志级别
POST /actuator/loggers/com.example.payment
Content-Type: application/json
{ "configuredLevel": "DEBUG" }想关回去:
POST /actuator/loggers/com.example.payment
Content-Type: application/json
{ "configuredLevel": "INFO" }这背后发生的事情是:
- Actuator 接收到请求 → 调用 LoggingSystem#setLogLevel(“com.example.payment”, LogLevel.DEBUG);
- LoggingSystem 根据底层实现(Logback / Log4j2)调用对应 API;
- 修改 Logger 树上这个节点的 level;
- 立即生效,不需要重启服务,也不需要改配置文件。
你可以很自然地把它整合进你的运维体系:
- 内部运维面板 / Grafana 面板上加个“日志调级”操作;
- 故障排查手册里写明:临时对哪些包调 DEBUG;多久后调回去;是否需要配合变更单 / 告警抑制一起使用。
6.5 云原生场景下的“动态日志”最佳实践
最后,用几条经验把动态日志配置在云原生里的用法收一下:
1)策略上:局部调级,避免全局 DEBUG
- 准确到包甚至类名;
- 利用日志 Facade + 规范化包结构,提前在代码结构上为“局部调级”做好准备。
2)实现上:优先选 Actuator 在线调级,配置文件扫描作为补充
- Actuator 适合粒度细、频率低的调级;
- 配置文件扫描适合整体模式切换、非 Spring 应用或基于配置中心的统一控制。
3)安全上:对外网关闭 /actuator/loggers
- 只允许内网或运维专用网络访问;
- 可以加 gateway / auth / 审计。
4)配合配置管理:日志级别也可以是“配置中心的一部分”
- 列如把日志级别放在 ConfigMap / Nacos / Config Server 里;
- 通过配置刷新 + LoggingSystem 统一调节;
- 对某环境做“统一降噪”或“统一提级”时会很有用。
当你把“配置管理的抽象(Environment + PropertySource)”和“日志机制的抽象(Logger + Appender + Filter + Formatter + Facade + LoggingSystem)”都吃透之后:
不管底下是 Docker 还是 K8s,不管上面接的是 ELK 还是 Loki,
你都可以把它们当作“可插拔的后端”,而不是“绑死的技术选型”。
七、把配置和日志放在一起:云原生 Java 服务的最佳实践小结
配置管理和日志体系,实则是同一套“解耦思路”的两面:
– 配置:把“怎么跑”从代码里拿出来,交给外部世界决定;
– 日志:把“跑了啥”从内部世界拿出来,交给人和平台消费。
7.1 配置管理:从“写死在 yml”到“云原生友善的配置布局”
1)镜像内只放“默认值”和“开发配置”
src/main/resources/application.yml
- 放一些环境无关的默认值(线程池大小、业务开关默认状态等);
- 或开发环境常用配置(本地数据库、本地 Redis 等)。
多个 profile 文件列如 application-dev.yml、application-prod.yml 也可以打进镜像,但不直接在镜像里写死启用哪个 profile。
2)环境差异一律外部化
Profile 选择:
- Docker:-e SPRING_PROFILES_ACTIVE=prod
- K8s:ConfigMap + SPRING_PROFILES_ACTIVE=prod
环境特定配置(DB、MQ、三方服务地址等):
- 优先通过 ConfigMap / Secret → 环境变量;
- 或 ConfigMap → 挂载配置文件 + spring.config.additional-location;
- 如果使用配置中心,则通过 spring.config.import 把它们“拉进” Environment。
3)敏感配置永不进仓库、永不进镜像
数据库密码、访问密钥、Token 等:
- K8s Secret;
- 或 Vault / KMS / Secrets Manager;
在 Spring 里保持同样的属性名,列如:
- spring.datasource.username
- spring.datasource.password
让 “敏感 vs 非敏感” 这件事完全交给基础设施处理,对代码来说全部都是 “Environment 里的配置”。
4)配置获取统一用 @ConfigurationProperties
和满世界 @Value(“${xxx}”) 相比,@ConfigurationProperties 有几个巨大的优势:
- 支持绑定对象结构,配置更清晰;
- 能配合校验注解(@Validated),启动时就发现错误配置;
- 更容易做“切换配置源”——只要 Environment 里有这几个 key,绑定就能成功。
示例:
@ConfigurationProperties(prefix = "cloudchat.storage")
public class StorageProperties {
private String endpoint;
private String accessKey;
private String secretKey;
private String bucket;
}不管后端是 MinIO、S3 还是阿里云 OSS,只要统一这一组配置键,Cloud-Native 化就只是“在不同环境填不同值”的问题。
7.2 日志体系:从“能打日志”到“可观测、可调节的日志”
1)代码层只用 SLF4J,统一出口
- 业务代码一律:
private static final Logger log = LoggerFactory.getLogger(CurrentClass.class);- 不直接依赖 Logback / Log4j2 API。
- 第三方库的各种 JUL / commons-logging / Log4j1,通过桥接包统一导向 SLF4J。
这样你要改日志实现时:
- 改依赖(spring-boot-starter-logging → spring-boot-starter-log4j2);
- 换配置文件(Logback XML → Log4j2 XML / YAML);
- 业务代码零改动。
2)标准化包结构,为“局部调级”预留空间
设计项目包结构时刻意这么做:
- com.rendazhang.app.web — Controller 层;
- com.rendazhang.app.service — 业务层;
- com.rendazhang.app.repository — 数据访问层;
- com.rendazhang.app.integration — 外部服务调用;
- com.rendazhang.app.infrastructure — 基础设施相关。
然后在 application.yml / logback-spring.xml 里对这些包做不同的默认 level:
logging:
level:
root: INFO
com.rendazhang.app.integration: DEBUG这样线上排障时,你可以很自然地做到:
- 只对 com.rendazhang.app.payment 开 DEBUG;
- 或只对 com.rendazhang.app.integration 开 DEBUG;
- 而不会“全盘 DEBUG 刷爆日志”。
3)日志输出优先 stdout,配合云原生日志采集
在 K8s 里,最推荐的模式是:
- 应用日志 → stdout/stderr;
- 由节点上的 agent(Fluent Bit / Filebeat 等)或 Sidecar 把 stdout 收集到 ELK / Loki / 云日志服务;
- 如有需要,再在 Logback / Log4j2 层面增加少数关键文件日志(如审计日志)。
好处:
- 容器生命周期与日志生命周期解耦;
- 迁移集群 / 云厂商时,只要保证“stdout 被采集”即可;
示例(Logback):
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{yyyy-MM-dd'T'HH:mm:ss.SSS} %-5level [%thread] %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE"/>
</root>
4)为运维准备好“在线调级通道”
引入 Actuator,开放 /actuator/loggers(只在内网 / 管理网络可访问);
形成排障 SOP:
- 通过 /actuator/loggers 查看当前 level;
- 对某个包(如 com.rendazhang.app.payment)调到 DEBUG;
- 持续观察状态 + 日志;
- 故障定位完,立刻调回 INFO;
- 把这次调级过程记录到变更 / 值班记录。
配合配置管理,还可以把一些“默认调级策略”放到配置中心,
对某环境统一做日志降噪或者统一提级。
7.3 一张“配置流 & 日志流”的整体心智图
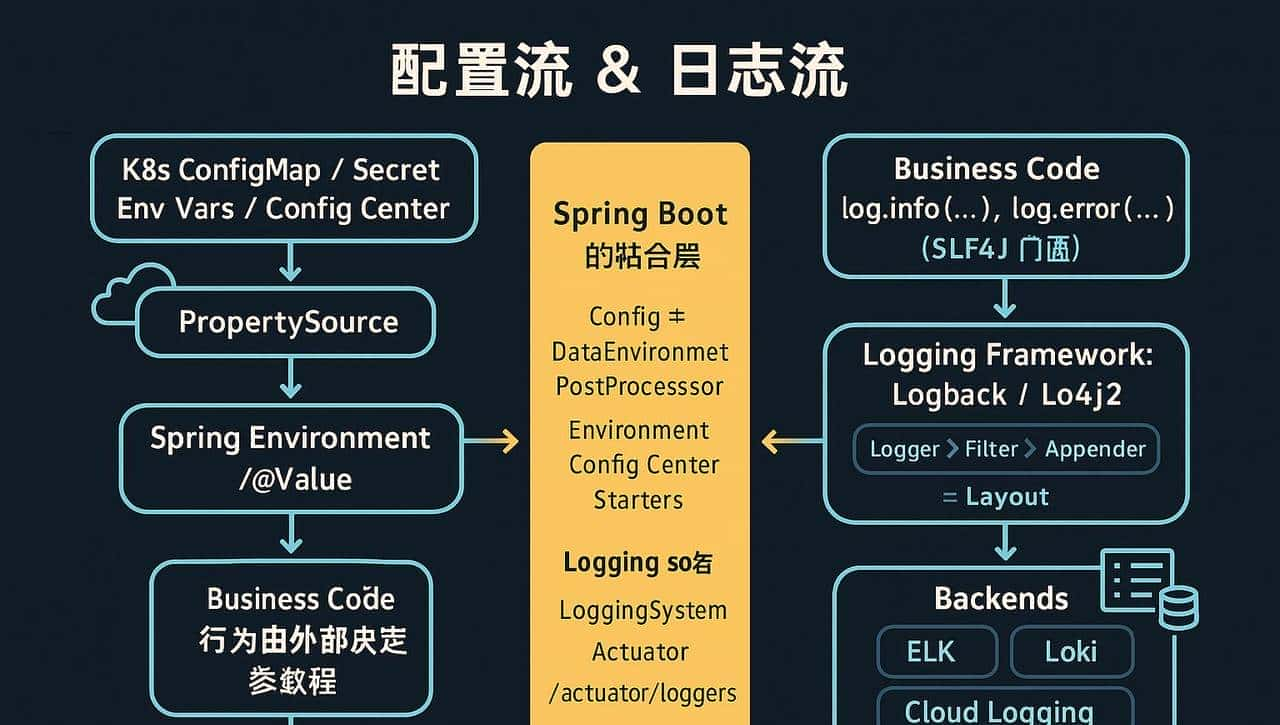
—
左边:配置流(Config Flow)
K8s ConfigMap / Secret / 环境变量 / 配置中心
↓(变成 PropertySource)
Spring Environment
↓
@ConfigurationProperties / @Value 注入到 Bean
↓
业务代码读到“外部世界决定的行为参数”
右边:日志流(Log Flow)
业务代码 log.info(…) / log.error(…)
↓(SLF4J 门面)
Logback / Log4j2 / JUL
↓(Logger → Filter → Appender → Layout)
stdout / 文件 / Kafka / HTTP / 日志代理
↓
ELK / Loki / 云日志服务 / 报警系统
中间:Spring Boot 的粘合层
Config 侧:
ConfigDataEnvironmentPostProcessor、Environment、各种配置中心 starter;
Logging 侧:LoggingSystem、Actuator /actuator/loggers。
—
这就是一个完整的“云原生 Java 服务”在配置与日志层面的世界地图。
八、结语:理解机制,才能“换底盘不换代码”
Java / Spring 世界里,配置管理和日志体系的底层机制,实则早就为云原生准备好了。
真正限制你的,不是框架,而是你对这套机制的理解深度。
当你把这些东西搞清楚后来,会发生几件很现实的变化:
1)换基础设施不再恐惧
- 从裸机到 Docker,到 Kubernetes,再到不同云厂商;
- 从本地 yml 到 ConfigMap / Secret,再到 Consul / Nacos / Config Server / Vault;
- 从裸输出文件到 ELK / Loki / 云日志平台;
你会发现,自己的 Java 代码可以基本“不动声色”地适应这些变化—— 由于你知道:
- 它们要么变成了新的 PropertySource;
- 要么变成了新的 Appender 或日志采集方式。
2)排障能力直线上升
以前你看到“线上配置改了不生效”会有点懵,目前你会很自然地问:
- 这几个配置源在 PropertySource 链上的优先级顺序到底是怎样的?
- Spring Boot 启动日志里,哪些配置最终生效?能不能从 Environment dump 一下?
以前你面对“日志看不到/太多”会很焦虑,目前你会想:
- 是不是 logger 层级没设好、additivity 影响了传播?
- 是不是 stdout 没被正确采集,而不是应用没打日志?
- 是不是只需要对某个包动态调级,而不是全局 DEBUG?
3)对系统的“掌控感”增强
你不再只是“会用注解、会写 Controller”,而是能回答:
- 为什么这条配置会以这个值生效?
- 为什么这条日志会出目前这个地方?
- 如果我要换一套配置中心或日志平台,需要改动的是哪一层?
这种掌控感,正是从“会写业务代码”走向“会设计系统”的关键一步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...