
我把网站截图、5张发票、奇怪字体图片和一段视频都丢给 Qwen 3‑VL,结果比我想象的还“机智”——但也暴露了几个必须注意的问题

第一要说的是,Qwen 3‑VL 的确 把“看图理解+生成动作”这件事做得很流畅。我用网页版体验(本地跑模型对普通电脑来说成本太高),把一个网站的截图直接上传,提示它“完美复刻我上传的网站照片信息”,它给出了可运行的 HTML/CSS/JS 片段,还附带了静态资源的引用方式。说实话,我当场把这段代码部署成了一个 demo 链接,复制效果和视觉细节都让人惊讶。我的同事张姐看到后感叹,这种工具把前端工程日常中重复性工作彻底降级了。
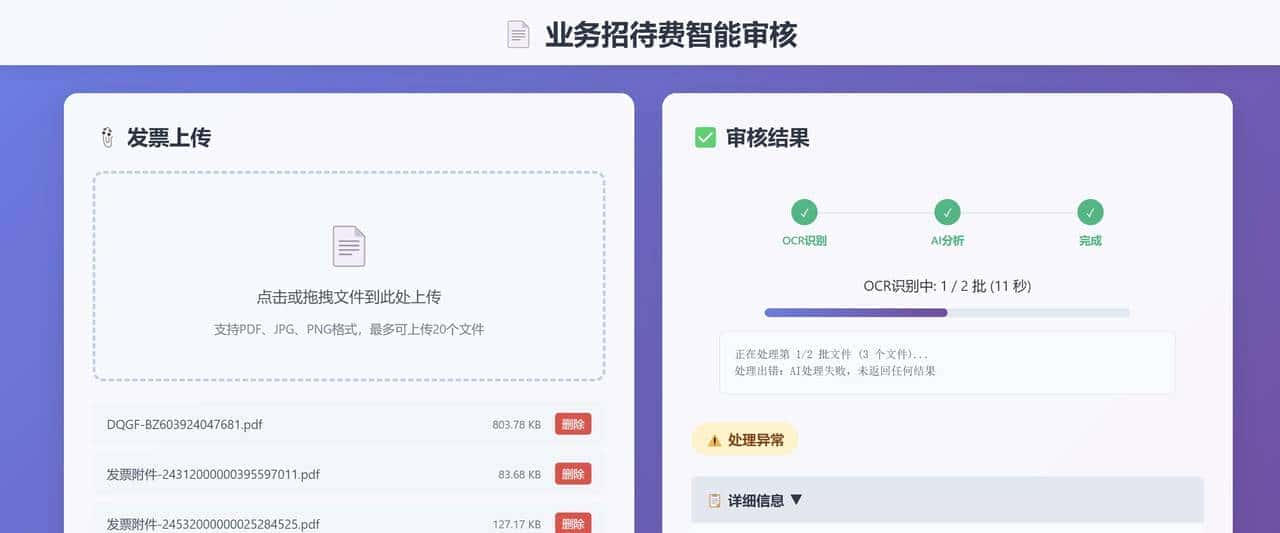
其次在票据识别上,体验既刺激又必须谨慎。我把五张发票合并成一张图片并对发票号做了马赛克处理,模型依旧能识别出各张单据的位置和字段,连一些格式不统一的报销单也能把金额、日期、税率归类出来。我的朋友小李把公司一周的差旅票据丢进去,节省的手工录入时间几乎是半天到一天。但我也发现两个问题:一是对部分手写痕迹和模糊角落的识别并不稳定,二是敏感信息的上传有潜在风险,所以务必在上传前做脱敏处理,并在企业等级场景下优先思考内部部署或采用合规的加密通道。
再者是对“难认字体”和视频字幕的表现。我找了张蝌蚪体风格的老海报,把图片扔进模型,它能把字形还原成文本,这一点尤其对文化类档案数字化有价值。对一段演示视频我让模型提取语音内容并生成可下载的 SRT,模型不仅能对画面中的界面文本做 OCR,还能把视觉线索和语音做语义关联,生成时间轴相对准确的字幕文件。我对两个不同生成的字幕文件做类似度比对,结果支持用类似度作为 OCR 精度的粗判指标,这对后续人工校对能省不少力。
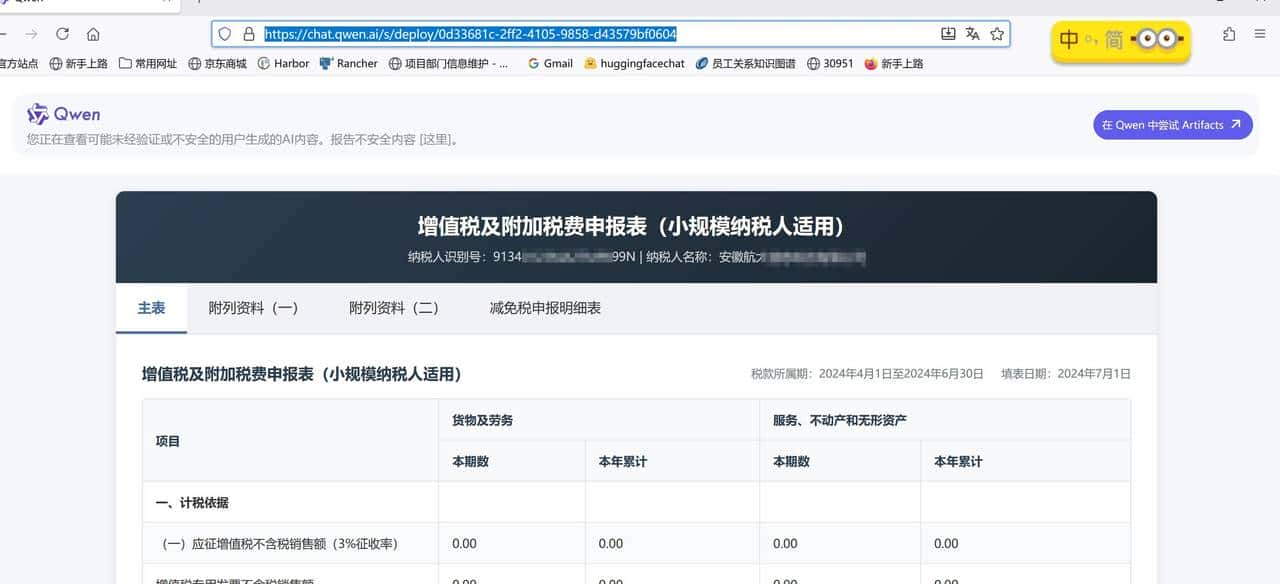
不过技术再牛,也不是万金油。一个明显的风险是“幻觉”或者说错误生成,尤其在需要准确数值和法律税务判断的场景。像增值税申报表这种格式化且涉及税务合规的文件,模型可以把字段提取出来并生成填写提议,但不能替代会计复核或税务局的最终判定。我同事做了一个小测试:模型把某一栏的金额识别成了相近但错误的数字,如果直接导出表单并提交,会带来合规风险。因此把模型作为“助手”而非“裁判”是我反复强调的原则。
接着说可操作的使用提议,既是给开发者也是给普通用户的落地指南。实操时先把要识别的文件做最小化脱敏,图片分辨率控制在模型输入推荐范围内,PDF 最好预先转成高质量图片再上传。提示词要具体:告知模型你需要输出的字段名、格式(例如 JSON 或 SRT)以及期望的容错策略,同时请求返回置信度或位置坐标以便人工校验。对于大批量任务,提议把文件分块上传并用类似度或置信度过滤初筛结果,再进行抽样复核。
不仅如此,部署与分享也变得更容易。我试过网页版一键部署的功能,把生成的静态页面分享到小组里,同事可以直接打开链接验证效果。这降低了沟通成本,但也提出了权限管理的问题:共享链接默认权限需谨慎设置,避免把含敏感信息的副本暴露在公网上。

最后我想说的是,这类多模态模型会把许多“重复性认知劳动”交给机器,使得我们能把时间花在更有判断力的工作上。但它带来的不仅是效率红利,还有对数据治理、隐私保护和职业角色边界的挑战。产品经理和团队需要构建“人机协同”流程:由模型先出草稿,人来做复核与合规判断,最后形成可交付产物。
你有没有想过把哪些日常繁琐的文档或图片交给这样的模型试试?分享一下你的场景、顾虑或者你最期待它解决的一个问题,让我们一起讨论现实中到底该怎么用才既高效又安全。

来源:chat.qwen.ai,HuggingFace,ModelScope
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...