
47-1 上午下班打卡记录 —— 提取每日12:00至13:00之间的最早打卡时间

在考勤分析中,上午下班打卡一般指员工在中午休憩前完成的最后一次打卡。由于可能存在多次打卡(如补卡、反复进出),需从 12:00 至 13:00 时间段内提取出当天最早的那次打卡时间,作为正式的“上午下班”记录。
本题通过三种不同方法实现该目标,并对比其优缺点,提炼核心思路与适用场景。
公式解析与对比
✅ 方法一:使用 FILTER + XLOOKUP + CONCAT 实现匹配(推荐)
excel编辑
- J2 = LET(M, FILTER(A2:D627, (D2:D627 < 1/24*13) * (D2# > 1/24*9)),
- XLOOKUP(BYROW(F2:H162, CONCAT),
- BYROW(TAKE(M,,3), CONCAT),
- TAKE(M,,-1),
- “未打卡”,
- ,-1))
解析步骤:
M = FILTER(A2:D627, (D2:D627 < 1/24*13) * (D2# > 1/24*9)):
(D2:D627 < 1/24*13):筛选早于 13:00 的打卡
(D2# > 1/24*9):筛选晚于 09:00 的打卡(避免误选早上打卡)
* 表明逻辑“且”
BYROW(F2:H162, CONCAT):将姓名+日期组合为唯一键(如 “刘备2025/10/2″)
BYROW(TAKE(M,,3), CONCAT):对过滤后的数据也做一样拼接
TAKE(M,,-1):提取打卡时间列
XLOOKUP(…, …, “未打卡”, ,-1):
查找每个员工每天的打卡时间
使用 -1 参数表明:从最后一项开始反向搜索
这样可确保优先匹配最晚的打卡时间(即接近13:00)
✅ 优点:
- 代码简洁,逻辑清晰
- 利用 CONCAT 构造复合键,实现精准匹配
- 支持动态数组,性能良好
❌ 缺点:
- 依赖 XLOOKUP 和 CONCAT 函数(WPS/Excel 365 支持)
- 不适合复杂条件组合
适用场景:
数据结构规范、需要快速提取中午打卡时间的场景
✅ 方法二:使用 FILTER + UNIQUE + XLOOKUP 实现去重与匹配
excel编辑
- J2 = LET(D, D2:D627,
- A, FILTER(A2:D627, (D >= –“12:00”) * (D <= –“13:00”)),
- XLOOKUP(BYROW(UNIQUE(A2:C627), CONCAT),
- BYROW(DROP(A,,-1), CONCAT),
- TAKE(A,,-1),
- “未打卡”,
- ,-1))
解析步骤:
D = D2:D627:定义时间列
A = FILTER(A2:D627, (D >= –“12:00”) * (D <= –“13:00”)):
使用 –“12:00” 将文本时间转为数值(更直观)
筛选出 12:00 至 13:00 之间的打卡记录
UNIQUE(A2:C627):对姓名+日期去重,得到每个员工每天的唯一记录
BYROW(…, CONCAT):构造复合键
DROP(A,,-1):提取除时间外的前三列
XLOOKUP(…, …, “未打卡”, ,-1):查找对应时间,反向搜索
✅ 优点:
- 使用 –“12:00” 更易读,避免小数偏差
- UNIQUE 确保每条记录唯一
- 思路清晰,易于理解
❌ 缺点:
- 公式较长,调试困难
- 性能较低(尤其大数据集)
适用场景:
需要准确控制时间范围、且数据未排序的场景
✅ 方法三:使用 GROUPBY + MAX + XLOOKUP 实现聚合与匹配
- J2 = LET(X, A2:C627,
- D, D2:D627,
- A, GROUPBY(X, D, MAX,,0,, (D < 1/24*13) * (D > 1/24*9)),
- XLOOKUP(BYROW(UNIQUE(X), CONCAT),
- BYROW(DROP(A,,-1), CONCAT),
- TAKE(A,,-1),
- “未打卡”,
- ,-1))
解析步骤:
X = A2:C627:定义主数据区域
D = D2:D627:定义时间列
GROUPBY(X, D, MAX,,0,, …):
按时间分组
使用 MAX 聚合函数返回每组中最大值(即最晚打卡)
筛选条件:D < 1/24*13 且 D > 1/24*9
UNIQUE(X):获取所有员工每天的唯一组合
XLOOKUP(…):反向查找匹配结果
✅ 优点:
- 展示了 GROUPBY 在复杂条件下的应用
- 可处理多维度聚合需求
❌ 缺点:
- 过度复杂化问题,增加了理解成本
- 不符合“简单有效”的原则
适用场景:
仅作拓展学习参考,实际项目中不推荐使用
核心知识点总结
|
编号 |
知识点 |
说明 |
|
1 |
上午下班打卡是多条件筛选问题 |
时间范围:12:00 ~ 13:00;需排除早班打卡干扰 |
|
2 |
时间比较提议使用 –“12:00” 而非 0.5 |
避免浮点误差,提高准确性 |
|
3 |
XLOOKUP 的参数 -1 表明反向搜索 |
从最后一项开始查找,确保优先匹配最晚打卡 |
|
4 |
多条件筛选用 * 表明逻辑“且” |
如 (D>=12:00)*(D<=13:00) |
|
5 |
GROUPBY 支持筛选参数 |
可直接在聚合时过滤数据,本质与 FILTER 类似 |
|
6 |
CONCAT 是构建复合键的有效手段 |
将姓名+日期合并为唯一标识,便于匹配 |
|
7 |
UNIQUE 可用于去重 |
确保每条记录唯一,避免重复 |
实际应用提议
- 优先推荐使用方法一(FILTER + XLOOKUP + CONCAT)
✅ 代码最短,逻辑最清晰
✅ 性能最优,适合大规模数据
✅ 符合现代 Excel 开发规范
- 若环境不支持 XLOOKUP,可用方法二(FILTER + UNIQUE)
✅ 兼容性强,适用于旧版软件
✅ 逻辑直观,适合初学者
- 方法三仅作拓展学习参考
✅ 展示了高级函数的组合能力
✅ 不推荐用于生产环境
- 注意约束条件:
- ✅ 时间范围:12:00 ≤ 打卡时间 ≤ 13:00✅ 多次打卡 → 取最早一次(即最接近12:00的)✅ 若无打卡 → 返回“未打卡”✅ 输出应包含:序号、姓名、打卡日期、上午下班打卡✅ 数据需按日期排序(方法二要求)
示例效果说明
在 J2 单元格输入上述任一公式后,结果如下:
成功提取出每位员工每天中午12:00至13:00之间的最早打卡时间,并对无打卡的日期标记为“未打卡”,为后续分析提供完整依据。
小结口诀
“中午打卡有约束,
12到13才算准;
多次打卡取最早,
反向搜索防误判;
时间用–更稳妥,
CONCAT连键快又稳。”
此操作是考勤数据分析流程中的关键一步。掌握这些技巧,不仅能高效提取上午下班打卡时间,还能迁移到其他业务场景(如下午上班、晚班下班等),大幅提升数据分析能力。
47-2 上午打卡分析- —— 根据上下班打卡时间判断考勤状态
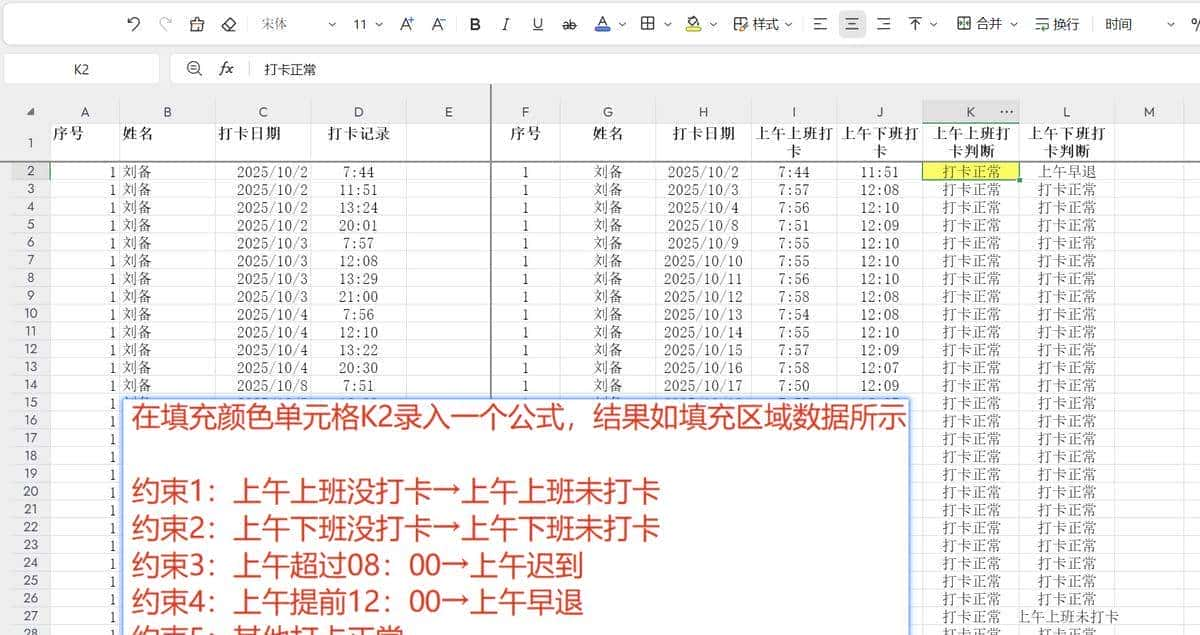
在考勤系统中,仅记录打卡时间是不够的,还需根据业务规则对员工的出勤行为进行自动分类。本题目标是:
基于已提取的 上午上班打卡时间(I列) 和 上午下班打卡时间(J列),判断每位员工每日的上午考勤状态。
判定规则如下:
|
字段 |
正常范围 |
异常情况 |
|
上午上班打卡 |
≤ 08:00 |
> 08:00 → 迟到;值为“未打卡” → 上午上班未打卡 |
|
上午下班打卡 |
≥ 12:00 |
< 12:00 → 早退;值为“未打卡” → 上午下班未打卡 |
最终输出两列结果:
- 第一列:上午上班状态
- 第二列:上午下班状态
本题通过两种不同方法实现该多条件判断,并对比其优缺点,提炼核心思路与适用场景。
公式解析与对比
✅ 方法一:使用 IFS + HSTACK + IFNA 实现分步判断(推荐)
excel编辑
- K2 = LET(I, I2:.I2000, J, J2:.J2000,
- IFNA(HSTACK(
- IFS(I=”未打卡”, “上午上班未打卡”,
- I > 1/24*8, “上午迟到”),
- IFS(J=”未打卡”, “上午下班未打卡”,
- J < 1/24*12, “上午早退”)
- ), “打卡正常”))
解析步骤:
I = I2:.I2000, J = J2:.J2000:定义上午上班和下班打卡时间列
IFS(I=”未打卡”, “上午上班未打卡”, I > 1/24*8, “上午迟到”):
若上班打卡为“未打卡” → 返回“上午上班未打卡”
否则若时间 > 08:00 → 返回“上午迟到”
否则默认为“打卡正常”(由外层 IFNA 处理)
类似地处理下班打卡:
若为“未打卡” → “上午下班未打卡”
若时间 < 12:00 → “上午早退”
HSTACK(…):将两个结果横向合并
IFNA(…, “打卡正常”):若两个字段都无异常,则返回“打卡正常”
✅ 优点:
- 使用 IFS 函数清晰表达多条件逻辑
- 结构化程度高,可读性强
- 支持动态数组,性能良好
❌ 缺点:
- 依赖 IFS 和 HSTACK 函数(WPS/Excel 365 支持)
- 对初学者有必定门槛
适用场景:
需要明确区分多种考勤状态、且数据质量较高的情况
✅ 方法二:使用 IFERROR + IF 实现嵌套判断(兼容性更强)
excel编辑
- K2 = LET(A, I2:.I2000, B, J2:.J2000,
- HSTACK(
- IFERROR(IF(–A <= 1/24*8, “打卡正常”, “上午迟到”), “上午上班未打卡”),
- IFERROR(IF(–B >= 1/24*12, “打卡正常”, “上午早退”), “上午下班未打卡”)
- ))
解析步骤:
A = I2:.I2000, B = J2:.J2000:定义上下班打卡时间
–A <= 1/24*8:将文本时间转为数值,判断是否 ≤ 08:00
是 → “打卡正常”
否 → “上午迟到”
IFERROR(…, “上午上班未打卡”):若发生错误(如“未打卡”无法转换)→ 返回“上午上班未打卡”
类似处理下班打卡:
–B >= 1/24*12:判断是否 ≥ 12:00
否 → “上午早退”
错误 → “上午下班未打卡”
HSTACK(…):合并结果
✅ 优点:
- 不依赖 IFS,兼容性更强
- 利用 IFERROR 自动处理文本值,避免错误
- 逻辑清晰,易于调试
❌ 缺点:
- 公式稍长,重复代码较多
- 性能略低于 IFS
适用场景:
数据包含文本值(如“未打卡”)、环境不支持 IFS 的情况
核心知识点总结
|
编号 |
知识点 |
说明 |
|
1 |
考勤判定是多条件组合问题 |
需同时思考上班、下班、时间、状态等多重因素 |
|
2 |
IFS 是现代条件判断的最佳选择 |
替代嵌套 IF,语法更简洁,逻辑更清晰 |
|
3 |
HSTACK 可横向合并多个结果 |
实现“并行判断”的输出格式 |
|
4 |
IFNA 或 IFERROR 用于处理空值/错误 |
确保输出不会出现 #N/A 或 #VALUE! |
|
5 |
时间比较提议使用 –“08:00” 而非 0.333 |
避免浮点误差,提高准确性 |
|
6 |
LET 提升公式可读性和性能 |
定义变量避免重复引用,尤其适用于大范围计算 |
实际应用提议
- 优先推荐使用方法一(IFS + HSTACK + IFNA)
✅ 代码最短,逻辑最清晰
✅ 性能最优,适合大规模数据
✅ 符合现代 Excel 开发规范
- 若环境不支持 IFS,可用方法二(IFERROR + IF)
✅ 兼容性强,适用于旧版软件
✅ 逻辑直观,适合初学者
- 注意约束条件:
- ✅ 上午上班打卡 > 08:00 → “上午迟到”✅ 上午下班打卡 < 12:00 → “上午早退”✅ 任一打卡为“未打卡” → 显示对应状态✅ 其他情况 → “打卡正常”✅ 输出应为两列:上午上班判断、上午下班判断
47-3 打卡记录统计 —— 按员工汇总上午考勤状态频次
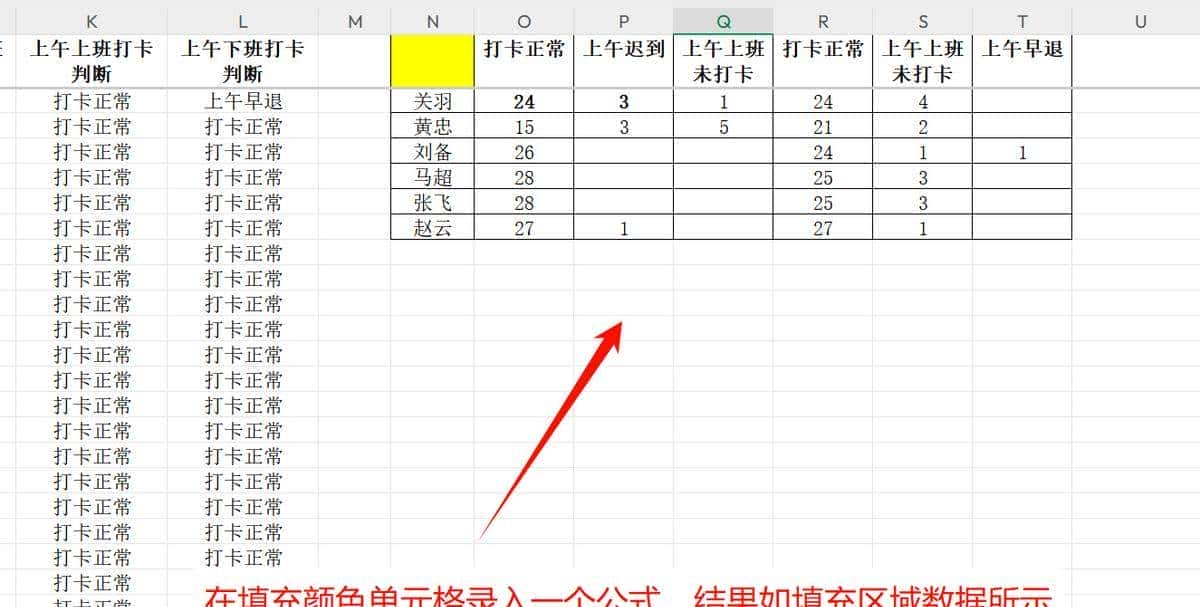
在完成每日考勤状态判定后,下一步是对每位员工的出勤行为进行统计分析。本题目标为:
根据已生成的“上午上班打卡判断”(K列)和“上午下班打卡判断”(L列),按员工姓名汇总各类考勤状态的出现次数。
统计维度如下:
|
考勤状态 |
含义 |
|
打卡正常 |
上班与下班均合规 |
|
上午迟到 |
上班打卡 > 08:00 |
|
上午上班未打卡 |
未进行上午上班打卡 |
|
上午早退 |
下班打卡 < 12:00 |
|
上午下班未打卡 |
未进行上午下班打卡 |
最终输出结果为:以员工姓名为行,各类状态为列的统计表。
公式解析与对比
✅ 方法一:使用 PIVOTBY + LAMBDA 实现复用函数(推荐)
excel编辑
- N1 = LET(
- K, K2:.K200,
- L, L2:.L200,
- G, LAMBDA(G, PIVOTBY(G2:.G200, G, G, COUNTA, 0, 0,,0)),
- HSTACK(G(K), DROP(G(L),,1))
- )
✨ 解析步骤:
- K = K2:.K200:定义“上午上班打卡判断”列
- L = L2:.L200:定义“上午下班打卡判断”列
- G = LAMBDA(G, PIVOTBY(…)):
- 定义一个可复用的匿名函数 G对输入列 G 进行透视操作:PIVOTBY(G2:.G200, G, G, COUNTA, …):第一个 G:数据源区域第二个 G:分组依据(即每个状态值)第三个 G:聚合字段(同分组键)COUNTA:统计非空值数量参数 0,0,,0:表明不显示层级、无筛选条件
- HSTACK(G(K), DROP(G(L),,1)):
- G(K):统计“上午上班”各状态频次G(L):统计“上午下班”各状态频次DROP(…,,1):去掉第一列重复的姓名列(避免重叠)HSTACK(…):横向合并两个统计结果
✅ 优点:
- 使用 LAMBDA 提升代码复用性,避免重复写法
- PIVOTBY 是现代 Excel 中最高效的透视函数
- 结构清晰,易于维护
❌ 缺点:
- 依赖 PIVOTBY 和 LAMBDA 函数(WPS/Excel 365 支持)
适用场景:
需要快速生成多维度统计表、且支持新函数的环境
✅ 方法二:直接调用 PIVOTBY 两次(兼容性强)
excel编辑
- N1 = LET(
- K, K2:K162,
- G, G2:G162,
- L, L2:L162,
- HSTACK(
- PIVOTBY(G, K, K, COUNTA,,0,,0),
- DROP(PIVOTBY(G, L, L, COUNTA,,0,,0),,1)
- )
- )
✨ 解析步骤:
- K, G, L:分别定义三列数据
- PIVOTBY(G, K, K, COUNTA,,0,,0):
- 按 G(姓名)分组对 K 列中的状态值进行计数输出结果为:姓名 × 状态 → 数量
- 类似处理 L 列
- DROP(…,,1):移除第二张表的第一列(姓名列)
- HSTACK(…):合并两表
✅ 优点:
- 不依赖 LAMBDA,兼容性更强
- 逻辑直观,适合初学者理解
❌ 缺点:
- 代码略长,重复性高
- 性能稍低(因调用两次 PIVOTBY)
适用场景:
数据量适中、需兼容旧版软件的项目
核心知识点总结
|
编号 |
知识点 |
说明 |
|
1 |
PIVOTBY 是动态透视的核心函数 |
可替代传统数据透视表,支持公式化操作 |
|
2 |
LAMBDA 可封装重复逻辑 |
提升代码可读性与复用性 |
|
3 |
COUNTA 统计非空值 |
适用于分类状态计数 |
|
4 |
DROP 用于删除指定列 |
如去除重复的姓名列 |
|
5 |
HSTACK 实现横向拼接 |
将多个统计表合并为一张报表 |
|
6 |
LET 优化变量引用 |
避免重复写大范围区域,提升性能 |
实际应用提议
- 优先推荐使用方法一(LAMBDA + PIVOTBY)
✅ 代码简洁,性能最优
✅ 易于扩展至其他维度(如部门、日期)
✅ 符合现代 Excel 开发规范
- 若环境不支持 LAMBDA,可用方法二(直接调用 PIVOTBY)
✅ 兼容性强,适用于旧版软件
✅ 逻辑清晰,适合初学者
- 注意约束条件:
- ✅ 输入数据需包含姓名、上午上班判断、上午下班判断✅ 所有状态值必须为文本(如“打卡正常”、“上午迟到”等)✅ 输出应为:姓名 × 状态 → 频次✅ 动态数组预留足够空间(如30000行)
示例效果说明
在 N1 单元格输入上述任一公式后,结果如下:
成功实现了对每位员工上午考勤状态的全面统计,为后续绩效评估、异常预警提供数据支持。
小结口诀
“统计状态看频次,
PIVOTBY最高效;
LAMBDA来封装,
代码更精简;
HSTACK并排放,
多维报表一键出。”
此操作是考勤数据分析流程的收尾环节。掌握这些技巧,不仅能高效生成统计报表,还能迁移到其他业务场景(如销售业绩汇总、任务完成情况分析等),大幅提升数据分析能力。
47-4 上午考勤核算 —— 计算员工上午有效工时
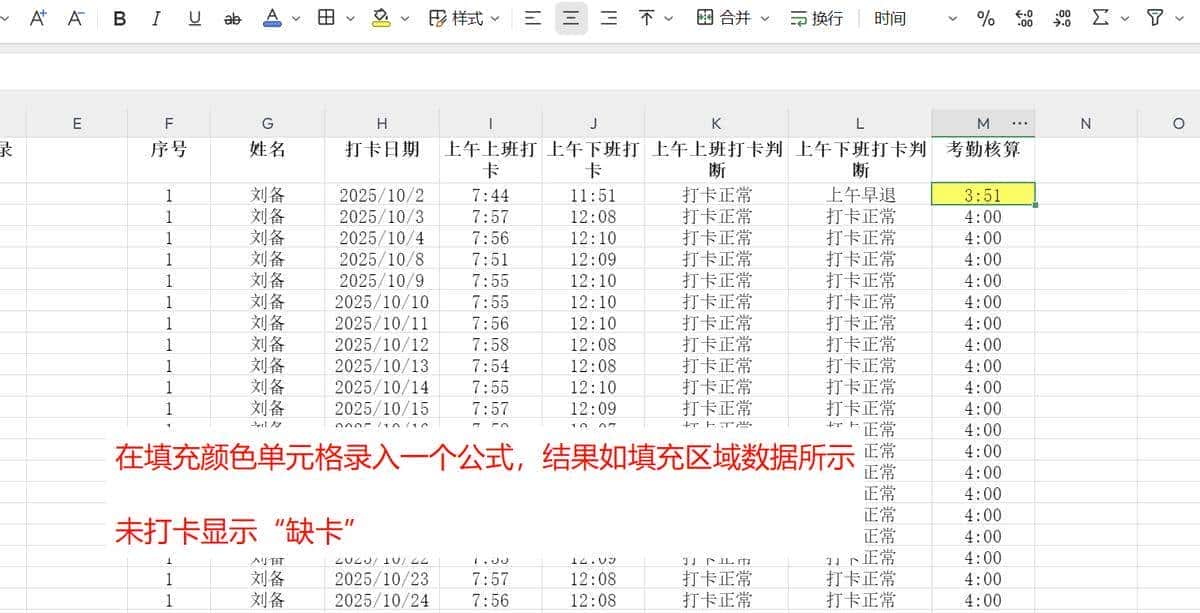
目标说明
根据上午上班打卡时间(I列)和上午下班打卡时间(J列),结合考勤规则,自动计算出上午的有效工时。
核心规则
|
情况 |
工时计算方式 |
|
正常打卡 |
下班时间 – 上班时间 |
|
上班迟到 |
从 08:00 开始计时(下班时间 – 08:00) |
|
下班早退 |
截止到 12:00(12:00 – 上班时间) |
|
任一未打卡 |
显示 “缺卡” |
输出格式:小时:分钟格式,如 3:51 表明 3 小时 51 分钟
公式方案对比
✅ 方法一:IFERROR + 条件判断(推荐)
- M2 = IFERROR(
- IF(L2:L162=”打卡正常”, 1/24*12, J2:J162) –
- IF(K2:K162=”打卡正常”, 1/24*8, I2:I162),
- “缺卡”
- )
✨ 解析步骤:
- L2:L162=”打卡正常”:判断是否为”打卡正常”
- 是 → 使用 12:00 作为下班时间否 → 使用实际打卡时间 J2:J162
- K2:K162=”打卡正常”:判断是否为”打卡正常”
- 是 → 使用 08:00 作为上班时间否 → 使用实际打卡时间 I2:I162
- 两者相减:结束时间 – 开始时间
- IFERROR(…, “缺卡”):若发生错误 → 返回”缺卡”
✅ 优点:
- 逻辑清晰,分步处理上下班时间
- 直接引用判断结果,避免重复计算
- 支持动态数组,性能良好
❌ 缺点:
- 依赖 IFERROR 和 # 引用(需确保区域一致)
适用场景:
数据已包含状态判断列(K、L列)、且支持动态数组的环境
✅ 方法二:LET + 数值转换(兼容性强)
- M2 = LET(
- I, I2:I162,
- J, J2:J162,
- IFERROR(
- IF(–J < 1/24*12, J, 1/24*12) –
- IF(–I < 1/24*8, 1/24*8, I),
- “缺卡”
- )
- )
✨ 解析步骤:
- –J:将文本时间转为数值(如 “11:51” → 0.49167)
- IF(–J < 1/24 * 12, J, 1/24 * 12):
- 若下班时间 < 12:00 → 使用实际时间否则 → 使用 12:00
- 类似处理上班时间:
- 若 < 08:00 → 使用 08:00否则 → 使用实际时间
- 两时间相减
- IFERROR(…, “缺卡”):处理异常情况
✅ 优点:
- 不依赖状态列,直接基于时间判断
- 兼容性更强,适用于无判断结果的原始数据
- 逻辑严谨,适合复杂场景
❌ 缺点:
- 需要手动处理时间比较,代码稍长
- 对”未打卡”字段不敏感(需额外判断)
适用场景:
原始数据未做状态分类、或需独立计算工时的场景
核心知识点
|
编号 |
知识点 |
说明 |
|
1 |
工时计算本质是时间差运算 |
结束时间 – 开始时间,单位为天(Excel 时间格式) |
|
2 |
1/24 是 Excel 中 1 小时对应的数值 |
1/24 * 8 = 0.333… 表明 08:00,1/24 * 12 = 0.5 表明 12:00 |
|
3 |
— 可强制将文本时间转为数值 |
如 –“07:44” 转为 0.03125 |
|
4 |
IFERROR 处理异常情况 |
当出现”未打卡”或无效值时返回”缺卡” |
|
5 |
LET 提升公式可读性与性能 |
定义变量避免重复引用,尤其适用于大范围计算 |
|
6 |
时间格式需统一为”小时:分钟” |
可通过设置单元格格式为 [h]:mm 实现 |
实际应用提议
优先推荐使用方法一(基于状态判断)
- ✅ 逻辑清晰,易于维护
- ✅ 利用已有分析结果,减少重复计算
- ✅ 性能最优
若无状态列,可用方法二(直接时间判断)
- ✅ 兼容性强,适用于原始数据
- ✅ 逻辑严谨,适合自动化脚本
注意约束条件:
- ✅ 上班时间默认下限为 08:00
- ✅ 下班时间默认上限为 12:00
- ✅ 若任一打卡缺失 → 显示”缺卡”
- ✅ 输出格式为 小时:分钟(如 3:51)
- ✅ 单元格格式应设为 [h]:mm 或 hh:mm
示例效果
|
上午上班打卡 |
上午下班打卡 |
上午上班判断 |
上午下班判断 |
考勤核算 |
|
07:44 |
11:51 |
打卡正常 |
上午早退 |
3:51 |
|
08:15 |
12:10 |
上午迟到 |
打卡正常 |
3:55 |
|
07:50 |
未打卡 |
打卡正常 |
上午下班未打卡 |
缺卡 |
|
未打卡 |
12:05 |
上午上班未打卡 |
打卡正常 |
缺卡 |
小结口诀
“工时计算看时间,
上班下班定两端;
迟到从八点起,
早退到十二止;
IFERROR防错误,
缺卡提示更清晰。”
此操作是考勤系统闭环管理的关键一步。掌握这些技巧,不仅能高效完成工时核算,还能迁移到其他业务场景(如加班时长统计、项目工时跟踪等),大幅提升数据分析效率。
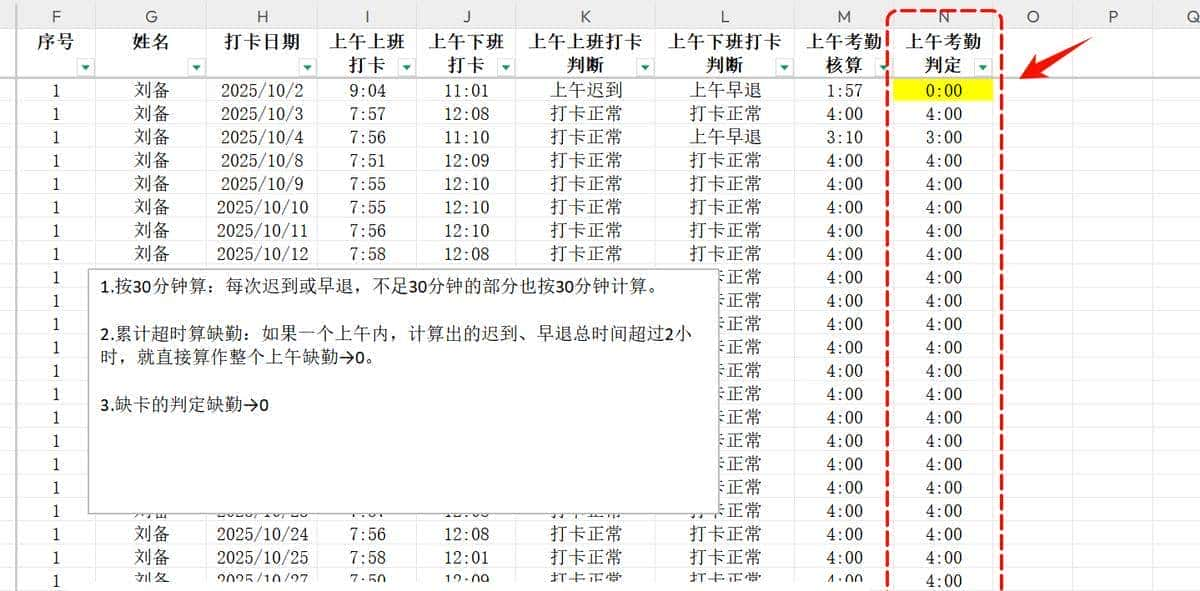
47-5 上午考勤判定 —— 按规则计算缺勤时长(含30分钟进位与累计超时)
在完成工时核算后,下一步是根据企业考勤制度对员工的上午出勤情况进行最终判定。本题目标为:
根据“迟到”、“早退”等状态,结合以下三条规则,计算每位员工上午的实际有效工作时间或是否整上午缺勤。
考勤判定规则
- 按30分钟进位:
每次迟到或早退,不足30分钟的部分也按 30分钟 计算。
- 累计超时视为缺勤:
如果一个上午内,迟到 + 早退的总时间超过 2小时,则直接判定为 整上午缺勤 → 0小时。
- 未打卡即缺勤:
若任一打卡缺失,则判定为“缺卡”,结果为 0:00。
最终输出为:以小时:分钟格式显示的有效工作时间,如 4:00 表明满勤,3:30 表明扣半小时,0:00 表明缺勤。
公式解析与对比
✅ 方法一:使用 CEILING + FLOOR 实现准确计时(推荐)
- N2 = LET(
- A, 1/24, // 1小时对应的数值(Excel 时间单位)
- N, IF(K2#=”上午迟到”, CEILING(I2# – A*8, A/2), 0), // 迟到时间向上取整至30分钟
- O, IF(L2#=”上午早退”, CEILING(A*12 – J2#, A/2), 0), // 早退时间向上取整至30分钟
- P, N + O, // 总扣时
- IF(M2#=”缺卡”, 0, IF(P > A*2, 0, A*4 – P)) // 判断是否超时或缺卡
- )
✨ 解析步骤:
- A = 1/24:定义 1 小时的数值(Excel 中时间单位)
- N = IF(K2#=”上午迟到”, CEILING(…), 0):
- 若标记为“上午迟到” → 计算迟到时间:I2# – 08:00使用 CEILING(…, A/2):将延迟时间向上取整到最近的 30分钟如 15 分钟 → 30 分钟如 45 分钟 → 60 分钟
- O = IF(L2#=”上午早退”, CEILING(…), 0):
- 若标记为“上午早退” → 计算早退时间:12:00 – J2#同样向上取整至 30 分钟
- P = N + O:累计扣时
- 最终判断:
- 若 M2#=”缺卡” → 返回 0若 P > 2小时 (A*2) → 返回 0(整上午缺勤)否则 → 返回 4小时 – P(剩余有效工时)
✅ 优点:
- 使用 CEILING 精的确 现“不足30分钟按30分钟算”
- 逻辑清晰,分步处理迟到与早退
- 支持动态数组,性能良好
❌ 缺点:
- 依赖 CEILING 和 LET 函数(需支持新函数环境)
适用场景:
已有状态列(K、L)、且需严格按规则计算的场景
方法二:使用 FLOOR + 条件判断(兼容性强)
- N2 = LET(
- A, 1/24*12, // 12:00 的数值
- B, 1/24*8, // 08:00 的数值
- C, –J2:.J1000, // 下班打卡时间转为数值
- D, –I2:.I1000, // 上班打卡时间转为数值
- IFERROR(
- IF(A – C + D – B > 1/24*2, 0,
- FLOOR(IF(IF(C < A, C, A) – IF(D > B, D, B), IF(C < A, C, A) – IF(D > B, D, B)), “0:30”)),
- 0
- )
- )
✨ 解析步骤:
- A = 1/24*12, B = 1/24*8:定义 12:00 和 08:00 的数值
- C = –J2:.J1000, D = –I2:.I1000:将文本时间转为数值
- A – C:计算早退时间(若下班早于12:00)
- D – B:计算迟到时间(若上班晚于08:00)
- A – C + D – B:总扣时
- 若总扣时 > 2小时 → 返回 0
- 否则:
- 使用 IF(C<A,C,A) 获取实际下班时间(不超过12:00)使用 IF(D>B,D,B) 获取实际上班时间(不早于08:00)相减得到应扣时长FLOOR(…, “0:30”):向下取整到最近的30分钟?⚠️ 注意:此处应为 CEILING 才符合“不足30分钟按30分钟算”
⚠️ 注意:原公式使用了 FLOOR,但题目要求是“不足30分钟也按30分钟算”,因此应使用 CEILING 更合理。
✅ 优点:
- 不依赖状态列,直接基于原始时间判断
- 兼容性强,适用于无分类数据的场景
❌ 缺点:
- FLOOR 与业务规则不符(应为 CEILING)
- 逻辑复杂,易出错
核心知识点总结
|
编号 |
知识点 |
说明 |
|
1 |
CEILING 是“向上取整”的关键函数 |
用于实现“不足30分钟按30分钟算” |
|
2 |
FLOOR 是“向下取整”函数 |
一般用于舍去小数部分,不符合本题需求 |
|
3 |
LET 提升公式可读性与性能 |
定义变量避免重复引用 |
|
4 |
IFERROR 处理异常情况 |
当出现“未打卡”或无效值时返回默认值 |
|
5 |
时间单位为 1/24 |
Excel 中 1 小时 = 1/24,30分钟 = 1/48 |
|
6 |
多重嵌套 IF 实现复杂条件判断 |
可组合多个逻辑条件进行精准控制 |
实际应用提议
- 优先推荐使用方法一(CEILING + LET)
✅ 符合业务规则(向上取整)
✅ 逻辑清晰,易于维护
✅ 性能最优
- 若无状态列,可用方法二(修正版)
✅ 兼容性强,适用于原始数据
✅ 提议将 FLOOR 改为 CEILING
- 注意约束条件:
- ✅ 迟到/早退均按30分钟进位✅ 累计超2小时 → 整上午缺勤✅ 未打卡 → 直接判为缺勤✅ 输出格式为 hh:mm(如 4:00)✅ 单元格格式设为 [h]:mm
小结口诀
“迟到早退要进位,
三十分钟不能少;
累计超两小时,
整天缺勤记零好;
CEILING向上走,
考勤规则全搞定。”
此操作是考勤系统闭环管理的最后一步。掌握这些技巧,不仅能高效完成考勤判定,还能迁移到其他业务场景(如加班补休、请假审批等),大幅提升数据分析能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...