
这里使用LLM模型作为AzureOpenAI,向量存储作为Pincone与LangChain框架。
1. 绪论
这篇博文深入探讨了创建一个高效的基于文档的问题解答系统所涉及的步骤。通过利用LangChain和Pinecone这两项尖端技术的力量,我们利用了大型语言模型(LLM)的最新进展,包括AzureOpenAI GPT-3和ChatGPT。
LangChain是一个专门为开发语言模型驱动的应用程序而设计的强劲框架,是我们项目的基础。它为我们提供了必要的工具和能力,以创建一个能够根据具体文件准确回答问题的智能系统。
为了提高我们问题回答系统的性能和效率,我们整合了Pinecone,这是一个高效的矢量数据库,以建立高性能的矢量搜索应用而闻名。通过利用它的能力,我们可以显著提高我们系统的搜索和检索过程的速度和准确性。
我们在这个项目中的主要重点是通过完全依靠目标文件中包含的信息来生成准确的和上下文感知的答案。通过将语义搜索的优势与GPT等LLM的卓越能力相结合,我们实现了一个最先进的文档QnA系统。
通过这篇博文,我们旨在引导读者完成建立他们自己的前沿的基于文档的问题回答系统的过程。通过利用人工智能技术的最新进展,我们展示了结合语义搜索和大型语言模型的力量,最终形成一个高度准确和高效的系统,用于回答基于特定文档的问题。
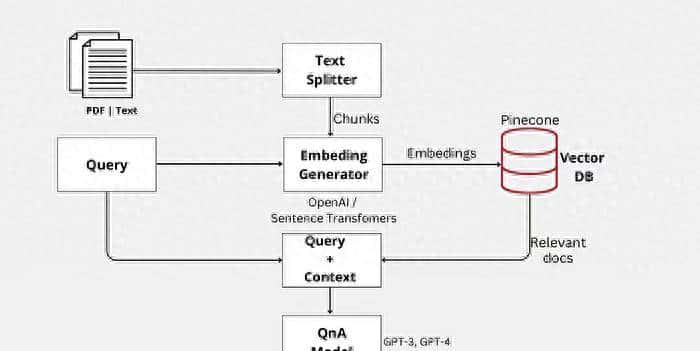
2. 针对具体环境的答案:
语义搜索+GPT QnA可以通过将答案建立在相关文件的具体段落上,从而产生更多针对具体语境和准确的答案。不过,经过微调的GPT模型可能会根据模型中嵌入的一般知识生成答案,而这些答案可能不太准确,或者与问题的上下文无关。
3. LangChain模块
LangChain提供对几个主要模块的支持:
- 模型: LangChain支持的各种模型类型和模型集成。
- 索引: 当与你自己的文本数据相结合时,语言模型往往更加强劲 – 本模块涵盖了这样做的最佳实践。
- 连锁: 链超越了单一的LLM调用,是一系列的调用(无论是对LLM还是不同的工具)。LangChain为链提供了一个标准接口,与其他工具进行了大量的整合,并为常见的应用提供了端到端的链。索引: 当与你自己的文本数据相结合时,语言模型往往更加强劲 – 本模块涵盖了这样做的最佳实践。
4. 让我们深入了解实际的实施情况:
导入图书馆:
import os
import openai
import pinecone
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
from langchain.llms import OpenAI
from langchain.chains.question_answering import load_qa_chain
第一,我们需要使用LangChain中的DirectoryLoader从一个目录中加载文档。在这个例子中,我们假设文件存储在一个名为 “data “的目录中。
directory = '/content/data' #keep multiple files (.txt, .pdf) in data folder.
def load_docs(directory):
loader = DirectoryLoader(directory)
documents = loader.load()
return documents
documents = load_docs(directory)
len(documents)
目前,我们需要将文件分割成更小的块状物进行处理。我们将使用LangChain中的
RecursiveCharacterTextSplitter,它默认情况下会尝试在字符[”
“, ”
“, ” “, “”]上分割。
def split_docs(documents, chunk_size=1000, chunk_overlap=20):
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap)
docs = text_splitter.split_documents(documents)
return docs
docs = split_docs(documents)
print(len(docs))
一旦文件被分割,我们需要使用OpenAI的语言模型来嵌入它们。第一,我们需要安装tiktoken库。
!pip install tiktoken -q
目前,我们可以使用LangChain的OpenAIEmbeddings类来嵌入文档。
embeddings = OpenAIEmbeddings(model_name="ada")
query_result = embeddings.embed_query("Hello world")
len(query_result)
Pinecone是一个高性能的向量数据库。它能对高维向量进行快速、准确的类似性搜索。凭借其用户友善的API、可扩展性和先进的算法,开发者可以轻松处理大型矢量数据,实现实时检索,并建立高效的推荐系统和搜索引擎。
!pip install pinecone-client -q
然后,我们可以初始化Pinecone并创建一个Pinecone索引。
pinecone.init(
api_key="pinecone api key",
environment="env"
)
index_name = "langchain-demo"
index = Pinecone.from_documents(docs, embeddings, index_name=index_name)
我们正在使用Pinecone.from_documents()方法创建一个新的Pinecone向量索引。这个方法需要三个参数:
- docs: 一个使用 RecursiveCharacterTextSplitter 分割成小块的文件列表。这些小块将被编入Pinecone的索引,以方便后来搜索和检索相关文件。
- embeddings: OpenAIEmbeddings类的一个实例,它负责使用OpenAI的语言模型将文本数据转换为嵌入(即数字表明法)。这些嵌入将被存储在Pinecone索引中并用于类似性搜索。
- index_name: 一个代表Pinecone索引名称的字符串。这个名字用于识别Pinecone数据库中的索引,它应该是唯一的,以避免与其他索引冲突。: OpenAIEmbeddings类的一个实例,它负责使用OpenAI的语言模型将文本数据转换为嵌入(即数字表明法)。这些嵌入将被存储在Pinecone索引中并用于类似性搜索。
Pinecone.from_documents()方法处理输入的文档,使用提供的OpenAIEmbeddings实例生成嵌入,并以指定的名称创建一个新的Pinecone索引。产生的索引对象可以进行类似性搜索,并根据用户的查询检索相关的文档。
5. 寻找类似的文件:
目前,我们可以定义一个函数来寻找基于给定查询的类似文件。
def get_similiar_docs(query, k=2, score=False): # we can control k value to get no. of context with respect to question.
if score:
similar_docs = index.similarity_search_with_score(query, k=k)
else:
similar_docs = index.similarity_search(query, k=k)
return similar_docs
6. 使用LangChain和OpenAI LLM进行问题回答:
有了必要的组件,我们目前可以使用LangChain的OpenAI类和一个预建的问题回答链来创建一个问题回答系统。
from langchain.llm import AzureOpenAI
model_name = "text-davinci-003"
llm = AzureOpenAI(model_name=model_name)
chain = load_qa_chain(llm, chain_type="stuff") #we can use map_reduce chain_type also.
def get_answer(query):
similar_docs = get_similiar_docs(query)
print(similar_docs)
answer = chain.run(input_documents=similar_docs, question=query)
return answer
7. 查询和回答的例子:
最后,让我们用一些实例查询来测试我们的问题回答系统。
query = "How is India's economy?"
answer = get_answer(query)
print(answer)
query = "How have relations between India and the US improved?"
answer = get_answer(query)
print(answer)
在这里,我们将获得带有特定查询的上下文,然后我们将查询和上下文作为提示传递给LLM模型以获得响应。
8. 结论:
在这篇博文中,我们展示了利用LangChain和Pinecone构建一个基于文档的问题回答系统的过程。通过利用语义搜索和大型语言模型的能力,这种方法为从大量的文件聚焦提取有价值的信息提供了一个强劲而通用的解决方案。此外,这个系统可以很容易地进行定制,以满足个人需求和特定领域,为用户提供一个高度适应性和个性化的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...