
在日常工作中,你遇到过将一张工作表按必定要求进行拆分的情况?列如财务部门要按分公司拆分报表,人事部门要按科室拆分员工信息,销售部门要按区域拆分销售数据……最近又收到了这样一个问题,就是按“年级”和“班级”两列拆分工作表到一个工作簿中的多个工作表。
如果按照手工常规操作,我们要不断地按年级、班级筛选数据、然后不停地新建工作表、复制粘贴数据、修改工作表名。如果只是新建复制少量的工作表,还能胜任。如果要这样操作许多次,出错的风险和概率就会明显上升。试想一下,如果财务把有错误的表格记入账目,会给企业带来多大的损失……
前期在《Python高效办公:小白也能懂,12行代码6秒拆分6700行数据,精准生成22个工作簿(附代码)》中,分享将工作表拆分到不同工作簿的案例。今天分享一下,如何将一张工作表拆分到一个工作簿的多个工作表。
下面是拆分的完成代码,仅9行代码就可以完成这项任务,即使是再多的数据也不怕:
import pandas as pd
path = r"D:播音.xlsx"
df = pd.read_excel(path,sheet_name="订单信息",header=0)
df_group= df.groupby(["年级","班级"])
with pd.ExcelWriter(r"D:播音_拆分.xlsx") as wb:
for nj_bj,df_cf in df_group:
sht_name = "".join(nj_bj)
df_cf.to_excel(wb,sheet_name=sht_name,index=False)
print(f"共拆分出{len(df_group)}个工作簿")一键运行,结果秒出,一共拆分出20个工作表,并且已经用年级+班级的方式重命名:
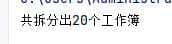

代码解析
- 前3行代码作用是导入所需的模块pandas、设置工作路径、用pandas读取数据。sheet_name=”订单信息” 用于指定工作表,header=0 表明第一行是列标题。如果省略了sheet_name和header,则默认读取第一张工作表,第一行为标题。
- 第4行代码df.groupby([“年级”,”班级”])用于对数据进行分组,如果只有一个字段,直接写入文本即可,如df.groupby(“年级”);如果按多个字段分组,则以列表形式写入。
- 第5行代码作用是创建或打开一个Excel文件的语句,一般用于将多个DataFrame写入到同一个Excel文件的不同工作表中。pd.ExcelWriter是用于写入Excel文件的类,使用with语句能够确保文件正确关闭。
- 第6行代码作用是循环遍历分组后的每一组数据,nj_bj是指分组的键,这里会得到一个由“年级+班级”组成的元组,df_cf是分组后的数据,也就是每一个DataFrame。
- 第7行代码是将分组后的班级和年级连接起来,方便后续作为工作表的名称来使用。
- 第8行代码是分别将分组后的数据写入到指定工作簿的工作表,并用“年级+年级”重命名工作表。
- 第9行代码显示运行结果。
如果你也有类似的任务需要完成,只需修改代码中的文档路径和分组的列名称即可拿来使用。
如果你觉得这篇文章对你有所协助,还请点赞、收藏、转发。你的支持是我最大的动力~~~
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...