
系统在短短半年里出现了明显失速:订单表记录从300万冲到780万,查询延时从原来的200毫秒飙到1.5秒,数据库连接池频繁被耗尽,个别交易直接超时失败。用户量突破500万,订单每月以约80万条的速度在累加,原来的单库架构显然撑不住了。
出问题之后,先做了应急级别的排查:慢查询、索引分析、连接池配置都看过,没发现单一故障点。进一步分析发现,这是典型的数据膨胀导致的性能瓶颈。MySQL这种基于B+树索引的存储结构,当单表行数跨过500万时,索引层级变深,查询成本明显上升;到了1000万行,哪怕再优化索引,扫描代价也难以避免。结论很直接:不得不思考将数据水平切分,分库分表成为现实路径。
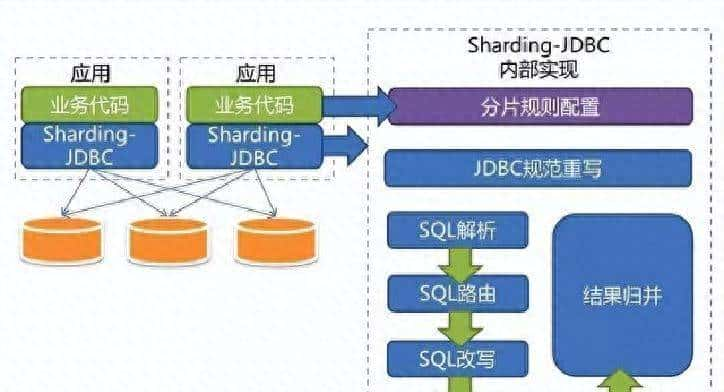
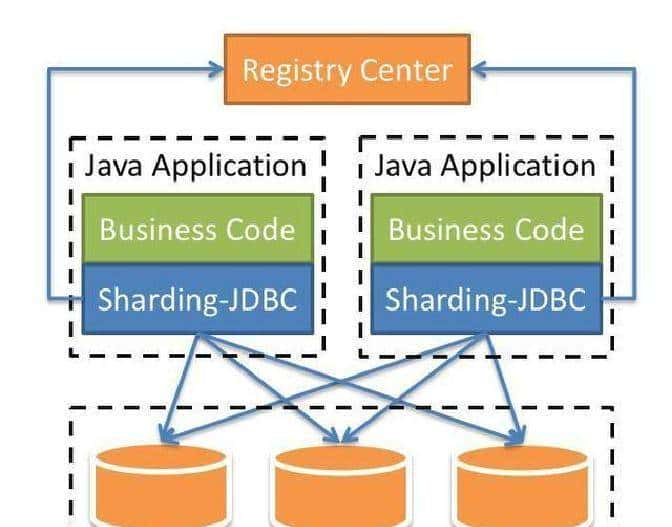
技术选型上,团队倾向于无侵入、低开销的方案。最后选了Sharding-JDBC,主要缘由是它以Jar包方式嵌入应用端,不需要独立部署代理层。好处有两点:一是性能损耗小,实际观测低于7%;二是没有额外代理服务,少了一个单点故障来源。对比一下类似工具:MyCat作为独立中间件,部署成服务,额外开销和运维成本都高,性能损耗大约在20%到30%;Sharding-Proxy也要跑独立进程,性能损耗在15%到25%。另外,语言支持上,Sharding-JDBC只支持Java,适合以Java为主的团队;如果多语言混合,像Sharding-Proxy会更合适。分布式事务方面,Sharding-JDBC支持XA/BASE等方案,可配合业务做一致性控制。

把Sharding-JDBC落地的细节说清楚:项目基于Spring Boot 2.7.18,集成了Sharding-JDBC 5.1.1。按计划把订单表拆为2库4表,并且做了读写分离。代码层面主要改动不大:实体类、Mapper接口、以及一套回归测试用于校验分片路由是否正确。部署时把配置写在应用里,运行时通过中间件路由决定SQL去哪个库哪个表。以一个简单的查询为例:SELECT * FROM t_order WHERE order_id = 12345 AND user_id = 678。中间件收到SQL后来,会先解析路由规则,定位目标物理表,然后把SQL发到对应的数据源去执行,最后把结果汇总返回给应用。架构上分为路由层、执行层和结果聚合层,逻辑清晰,故障面也比较小。
实践中遇到几个典型问题,必须逐条解决。第一,跨库事务的全局一致性问题。场景很常见:创建订单写到A库,扣库存写到B库,如果中间某一步失败,会出现残留数据。解决思路有几种:一是使用分布式事务协议(XA、2PC),风险是性能和复杂度都上来;二是采用最终一致性模式,把操作拆成本地事务+补偿流程;三是用专门的分布式事务框架(像Seata)来做协调。Sharding-JDBC本身支持XA/BASE,但有时更推荐把核心业务拆成弱耦合的步骤,减少跨库同步点。说白了,技术能帮一部分,业务设计更重大。
第二,表设计导致的跨库JOIN。用户表按user_id分片,订单表按order_id分片,查询“某用户的订单列表”会变成跨库关联。能用的策略不少,得根据表大小和查询模式来选:
– 绑定表:把父子表按同一个分片键切分(列如order和order_item都按order_id),关联查询在单个分片内完成,最简单也最快。
– 广播表:小表(字典、配置)走全库复制,查询时无需跨库join,但适用对象必须超级小。
– 冗余字段:在订单里冗余存用户关键信息,读多写少的场景可以接受,写更新成本增加。
– 应用层聚合:把多库查询结果拿回应用侧合并,适合复杂多表但并发不高的场景,工作量和延迟都较大。
第三,数据迁移要避免停机。实际做法是双写迁移:新逻辑同时写老表和新分片表,验证一段时间后异步回填历史数据,最后切换读路径。关键点是保证同步过程中不丢数据,回填要有幂等性检查,切换要有回滚方案。别小看这个步骤,出问题直接影响业务可用。
第四,分页和大偏移问题。原来的分页写法LIMIT 100000, 20在分片环境下会被改写成LIMIT 0, 100020,这会把许多不必要的数据拉到应用层,带宽和IO成本飙升。能做的优化包括:用基于主键的keyset分页(last_id+limit),或者先在每个分片上按条件查出ID,再聚合ID后按ID拉取具体记录,避免大offset在单库上滚动。
第五,分片键选择不当导致全表扫描。列如按order_id分片,但查询条件只有user_id,这种情况下路由无法定位到具体分片,只能广播到所有分片做扫描。应对方法是尽量让常用查询包含分片键,或者通过业务侧路由把查询拆成定向的多次查询并聚合结果。必要时可以通过建立额外索引或冗余字段来减少跨分片扫描。
连接层的调优也不能忽视。连接池配置直接影响吞吐量和稳定性。生产环境中常用的参数参考值如下:maximumPoolSize在20到50之间,按CPU核心数*2再加有效磁盘数来估算;minimumIdle维持在5到15,约为max的30%;connectionTimeout设为3000毫秒,避免长时间阻塞请求;maxLifetime设为1800000毫秒(30分钟),低于数据库的wait_timeout。合适的连接数能避免频繁创建连接和池耗尽的问题。
分片算法的选择也要跟场景匹配。常见有取模(mod)、范围(range)和哈希(hash):
– 取模:分布均匀,查询定位快,但扩容麻烦,需要数据迁移。适合用户ID、订单ID这种固定散列键。
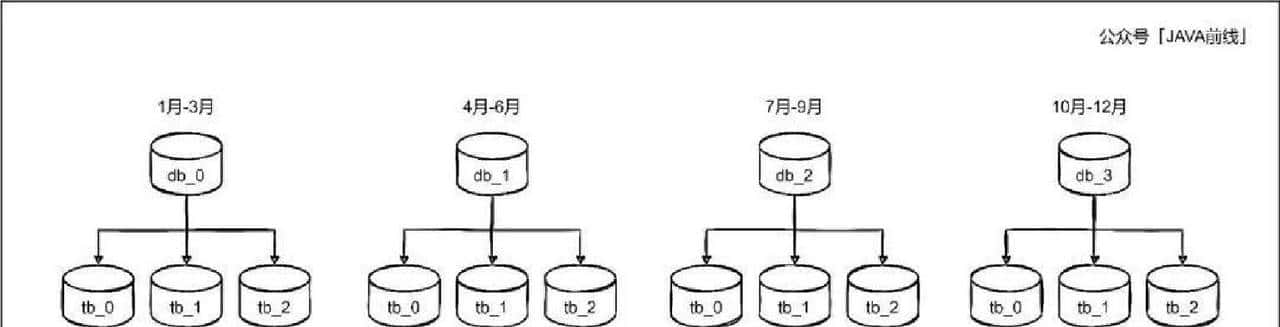
– 范围:按时间或ID范围分片,扩容相对容易,便于做按时间归档,但可能造成数据倾斜。
– 哈希:分布均匀,扩容复杂度中等,适合高并发读写场景。
在百万级到千万级数据测试下,取模分片的查询延迟比范围分片可低15%到20%,但范围分片能更方便做时间窗归档。
缓存配合能带来明显缓解。用三级缓存协同(本地缓存+分布式缓存+DB)能把热点命中率从大约50%提升到接近80%,从而显著降低数据库负载。热点策略要细化到业务维度,过期和一致性策略也要设计好。
在实际落地过程中,Sharding-JDBC的无侵入特性让改造成本下降不少。对Java团队来说,把分片逻辑放到应用里,开发能直接看到路由配置,调试也更方便。它作为Apache项目在持续迭代,分布式事务和数据治理相关的功能还在加强。顺便说一句,技术是工具,业务侧的拆分和约束往往决定最后的成败,这点别忽视。
想了解更多实战细节或者代码示例,可以关注【AI码力】。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...