
结果出来了:把散落在笔记和旧仓库里的示例代码、配套源码和说明文档,整理成了一个能直接跑、结构清晰的示例仓库。说白了,就是花了点时间把零碎的东西捋成一套,目的很直接——别人一看就懂,拿来就能用,不用再踩那些老坑。讲真的,整理完那一刻,感觉省心不少。
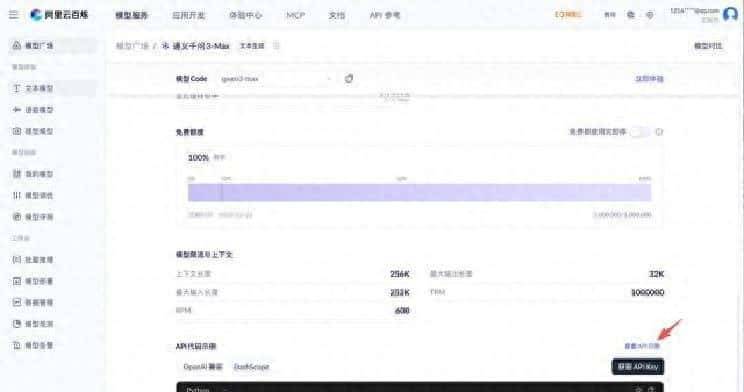
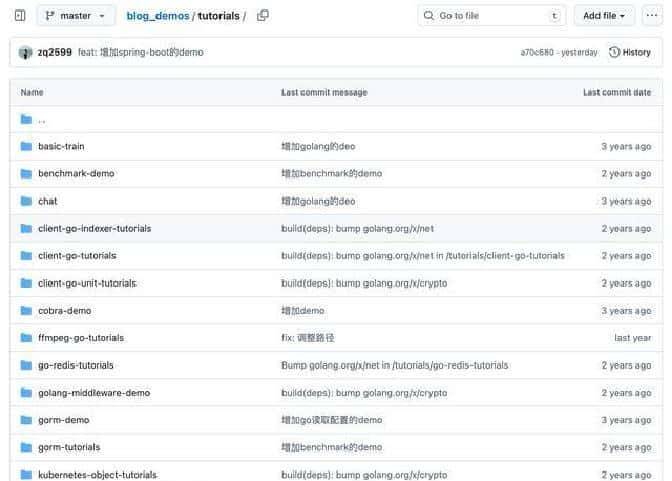
仓库地址直接放这儿,想看代码就去拉:
https://github.com/zq2599/blog_demos。目录和 README 都写了,emm,用起来比较方便。
下面按原来顺序把项目里的主要模块和定位说明一下,照着来找你需要的部分就行。
langchain4j-core
这是整个方案的核心层。把模型、消息、提示模板、输出解析器这些常见要素规范化成一套统一的 API。意思是:你写业务代码只对着这个统一接口走,底层接哪个模型对业务代码透明。可以把它当作数据库访问层的 JDBC:上层代码不关心具体实现。适合那种想把业务逻辑和模型实现拆开的场景。功能点、接口设计和示例都放在 core 里,搞清楚 core,接入别的模块就简单了。
langchain4j-openai / langchain4j-zhipu
这两部分是具体厂商的实现。core 定义了规范,这俩把规范翻译成厂商能理解的请求。换句话说,core 是标准化接口,厂商模块把这套接口映射成对应 API 的请求格式和参数。好处明显:遇到新模型,只要做一个这样的“驱动”实现,就能接入体系。说白了,就像给每家模型写个适配器。
langchain4j-Spring-boot-starter
这是把前面东西快速接到 Spring Boot 项目的组件。做了自动配置、暴露配置属性,项目里引入后,配置一下就能用,少写样板代码。用过 Spring Boot 的人会觉得熟悉,这类 starter 的存在就是为了省去手动 wiring 的麻烦。企业项目里,集成时间能省不少。
langchain4j-easy-rag
这是个轻量级的检索增强生成(RAG)解决方案。目标很明确:用最少的代码把私有文档建索引、检索并把检索结果拼接进提示里,让聊天/问答能利用内部知识库。实现上偏实用,封了常见流程和模板,开发者只需关注业务数据。话说回来,想快速把知识库接进去,这块能帮不少忙。
langchain4j-tools
这块挺有意思。它让模型能直接调用你用 @Service 写的后端方法,也就是把聊天模型的“动作”映射成后端服务调用。开发者把复杂能力以方法暴露出来,模型触发这些方法完成任务。思路像 FeignClient:把远程或复杂调用抽象成接口,调用方只看接口,不用管实现细节。实际用的时候,这能把模型能力和业务系统打通。
langchain4j-memory
负责对话记忆管理。包含窗口式缓存、长期存储和对话状态管理,解决聊天场景下上下文如何保留和检索的问题。设计偏中台化,把会话相关的信息统一管起来,像 Spring-Session 那样把会话细节交给组件处理。对话类产品里,这个模块很关键,别小看它。
下面是几个直接用得上的链接,复制粘贴就行。
项目主页
https://github.com/zq2599/blog_demos
git 仓库地址 (https)
https://github.com/zq2599/blog_demos.git
git 仓库地址 (ssh)
git@github.com:zq2599/blog_demos.git
每个模块在仓库里都有说明和示例代码,按需拉取。想快速上手的话,先看 core 的使用示例,再看对应的厂商实现,最后把 starter 接入你的 Spring Boot 项目即可。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...