

DeepSeekMath‑V2:基于自验证框架,把“大模型做数学”这件事,从“猜答案”推向“审推理”。
为什么大模型会在数学上“翻车”?——从答案正确率到推理可信度
过去两年,大模型在数学推理上的进步几乎是“跳跃式”的:
从几乎做不出初中竞赛题,到在 AIME、HMMT 等定量竞赛上接近甚至“饱和”人类顶级选手表现,这些进步主要来自:
- 大规模高质量数学数据
- RL‑from‑verifiable‑signal(用“答案是否正确”作为奖励)的强化学习
- Chain‑of‑Thought(CoT)显式推理链
但 DeepSeek 在论文中一针见血指出:只追求最终答案正确率,有三个根本问题(DeepSeekMath‑V2: Towards Self‑Verifiable Mathematical Reasoning, 2025):
- 答案对 ≠ 推理对 模型可以通过“试算、枚举、启发式”直接撞到正确答案,而中间链条充满谬误。 在打分体系里,这类解法 和严谨证明拿到同样分数,无法区分“会算题”和“会做数学”。
- 大部分高阶数学任务没有“可机检的最终答案” 定理证明、命题等价、结构分类等任务,关心的是: 在给定公理体系下,推理是否严谨完备? 单一数值答案根本不足以覆盖“推理正确性”的维度。
- 开放问题没有标准答案,传统 RL 信号失效 想让模型在尚无已知解的领域(如复杂组合、拓扑、代数结构)探索,就不能依赖“答案对/错”反馈。 这时,“能否自我验证推理过程” 就变成扩展算力和探索能力的关键。
因此,DeepSeek 把问题转成一个更技术化的目标:
如何训练一个 准确且忠实(faithful) 的 LLM‑based Verifier,来审查数学证明过程本身,并把它接入一个闭环:
生成证明 → 验证证明 → 用验证结果反向提升生成器。
DeepSeekMath‑V2 是什么?——基于自验证的数学推理框架
2.1 模型底座:DeepSeek‑V3.2‑Exp‑Base
DeepSeekMath‑V2 并不是“从零造一个数学模型”,而是:
在通用大模型 DeepSeek‑V3.2‑Exp‑Base 之上,
通过专门的训练管线,把它优化成一个 擅长生成 & 验证数学证明 的专家型模型。
底座模型已经具备:
- 强劲的通用语言建模能力
- 基础的 CoT 推理能力
- 与 DeepSeek 生态(如推理引擎、并行采样策略)的兼容性
数学版的工作重点,放在两个角色上:
- Proof Generator(生成器):负责写证明 / 解题过程
- Verifier(验证器):负责“审稿”,判定这份证明是否严谨、是否存在逻辑漏洞
2.2 自验证核心思路:让模型当自己的裁判
DeepSeekMath‑V2 的关键设计不是“多写几步推理”,而是:
显式构建一个 LLM‑based Verifier,对 LLM 自己写的证明进行自动审查。
Verifier 干的事,可以类比成数学期刊审稿人:
- 输入: 题目描述(Problem Statement) 模型生成的完整或部分证明(Proof)
- 输出: 对证明每个关键步骤的 接受 / 拒绝 判决 错误类型标签(如:跳步、错误推理、使用了未给出的条件等) 一个 整体评分,可作为 RL / 筛数据的 reward signal
在训练与推理阶段,Verifier 着重检查:
- 逻辑自洽性:每一步是否由前一步逻辑推出
- 完备性:有没有“关键一跳不写”的偷懒行为
- 一致性:是否与题目给定条件、公认定理、公理体系一致
- 非法捷径:有没有引入题目没有给出的额外假设
这与传统只看“final answer”的范式完全不同——
DeepSeek 把 reward 从 答案空间 提升到了 推理路径空间。
2.3 扩展验证计算:用更难的题,喂出更强的验证器
一个关键难点是:随着生成器变强,Verifier 也必须变强,否则就会“被骗过去”。
DeepSeek 的做法是引入“扩展验证计算(scaled verification compute)”:
- 自动制造 & 收集高难度证明样本 通过生成器对复杂题、多种变种题型进行多样化采样,得到大量“难判定”的证明草稿。 包含: 正确但风格各异的证明 带微妙漏洞、长链条的错误证明 刻意构造对 Verifier 迷惑性强的 adversarial sample
- 加大 Verifier 计算预算 对这些“hard‑to‑verify proofs”,投入更多计算: 多次思考 / 反思式验证(类似对证明做 CoT+自反思) 多视角重写再判定 得到更精细、更高置信度的标签。
- 用这些高难数据再训练 Verifier 本身 使 Verifier 对“表面上看还行,但有细微 bug 的证明”更敏感。 维持一个“generation–verification gap”: 不管生成器变多强,Verifier 始终有能力抓出它的纰漏。
最终形成一个闭环:
模型出题 / 解题 → Verifier 审查 → 挖掘难例 → 再训 Verifier → 用更强的 Verifier 再训生成器。
这就是 DeepSeek 所说的 “towards self‑verifiable mathematical reasoning” 的技术核心。
成绩单:IMO/CMO/Putnam 高分背后的含金量
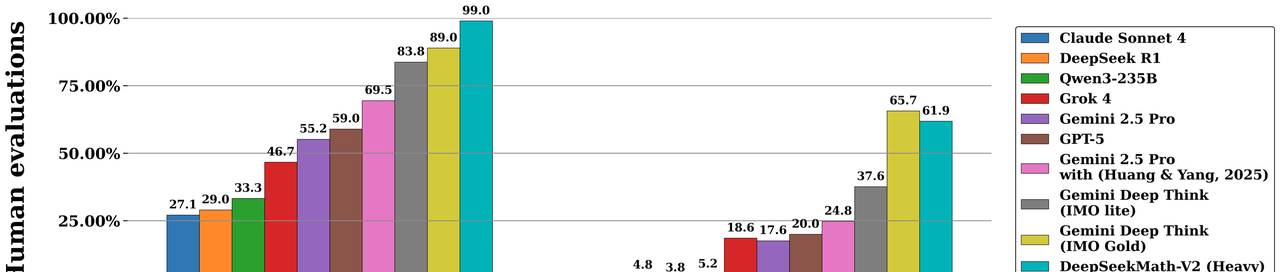
3.1 IMO 2025、CMO 2024、Putnam 2024 是啥水平?
几大 benchmark 的含金量:
- IMO(International Mathematical Olympiad) 面向中学生,但题目难度极高,设计强调深度推理和构造性证明。 IMO‑ProofBench 由 DeepMind 团队构建,是定理证明能力的重大评测集合。
- CMO(China Mathematical Olympiad) 国内顶级中学数学竞赛,用于选拔 IMO 国家队。 题目偏重几何、数论、组合的高难综合证明题。
- Putnam(William Lowell Putnam Mathematical Competition) 北美本科最高难度数学竞赛之一。 题目覆盖高等代数、分析、组合等,需要大学阶段系统训练。
3.2 DeepSeekMath‑V2 的表现意味着什么?
根据官方展示的图表(IMO‑ProofBench & Competitions):
- 在 IMO‑ProofBench 上,DeepSeekMath‑V2 位于当前已公开模型中的领先水平;
- 在 2025 IMO、2024 CMO、2024 Putnam 真题 上, DeepSeekMath‑V2 在扩展推理计算(scaled test‑time compute)配置下取得: IMO 2025:Gold‑level(相当于金牌水平) CMO 2024:Gold‑level Putnam 2024:118/120 接近满分

这些成绩说明两点:
- 模型不仅在“能否得出答案”上接近顶级人类选手,
- 在“能否写出长链条、结构复杂的严谨证明”上,也已经具备相当竞争力。
3.3 自验证机制带来的直接收益
对比传统只看答案的训练,自验证框架带来的实际收益包括:
- 显式降低“过程错误但答案对”的隐性错误率 对竞赛和定理证明来说,这一类错误才是最致命的。
- 对结构复杂题型更稳 如构造题、几何多步推理、组合计数中需要分情况 + 不变量分析的证明。
- 在加大推理算力(多样采样、多轮反思)时更“可控” 有 Verifier 把关,避免“算得越久,越跑偏”的现象。
DeepSeek 的“自我修行”:验证器 + 高难数据是怎么炼成的?
4.1 Verifier:从“打分器”到“数学审稿人”
Verifier 的设计目标,不是简单输出“对/错”,而是:
对一份证明给出 可解释的、步骤级的审查结论,
让这个结论既能用于监督训练,也能用于 RL 的 reward。
典型能力包括:
- 逐步解析证明结构(分步、分段、子结论)
- 对关键推导打标签: “逻辑有效”、“缺失前提”、“推理跳跃”、“与前文矛盾”等
- 输出一个整体评价,如: ACCEPT(证明大体正确,可存在轻微风格问题) REVISE(存在局部漏洞,需要修补) REJECT(存在致命错误)
在训练上,它更接近一个 “learned proof checker + reviewer”,
而不是单一的 scoring head。
4.2 数据流水线:自动制造“难而正确”的训练样本
为了让 Verifier 真正有用,光靠人工标注远远不够。DeepSeek 的做法可以抽象为:
- 大模型自生成证明候选 给定题目分布(如奥赛题、IMO‑ProofBench 题目、竞赛题变体), 生成器多样采样出大量不同风格 / 不同质量的解法与证明。
- 初步过滤 & 标注 使用已有的(可能偏弱的)Verifier 或规则过滤掉明显垃圾样本: 明显不相关答复 严重逻辑断裂 同时保留: 高质量但风格差异较大的正确证明(正样本) 逻辑较长、错误微妙的“陷阱证明”(负样本)
- 扩展验证计算做精细标注 对这批“值得认真看的样本”,给予 Verifier 更大的算力预算: 多轮自反思验证(例如:first-pass check → critique → revised check) 不同 prompt 视角下的交叉验证 最终得到: 高置信度的“正确证明”集 有标签的“错误模式”库
- 再训练 Verifier 把这些难例样本作为核心数据, 让 Verifier 在训练中学会识别 更 subtle 的错误模式,而不是只抓粗糙错误。
这条流水线的重大产出是:一个对难例敏感、可泛化的 Verifier。
♻️ 4.3 闭环逻辑:为什么会“越练越强”?
有了 Verifier 之后,训练 Proof Generator 的过程大致是:
- Generator 多样生成证明 避免只生成 one‑shot、单一路径的解法, 鼓励探索多种证明策略(如代数法、几何法、构造法等)。
- Verifier 审查 & 打分 生成一个 reward 信号,反映: 证明是否完整 错误定位在哪一步 是否存在逻辑黑洞
- 用 Verifier 的判断结果训练 Generator 可结合: RL(例如以 Verifier 打分为 reward) 有监督微调(用经 Verifier 确认为“高质量”的证明作为训练样本)
- Generator 升级后,再触发新一轮“挖难例 → 训 Verifier” 生成器变强 → 产生更难分辨的伪证明 → 再逼迫 Verifier 进化。
这种双向博弈的闭环,使系统整体能力不断抬升——
与人类数学家“做题—被批改—针对性训练—做更难题”的过程高度类似。
这对 AI 数学推理和普通用户有什么意义?
5.1 对 AI 研究与工程侧的意义
从研究视角看,DeepSeekMath‑V2 代表着:
- 从 “final‑answer‑centric RL” 向 “process‑centric verification” 的范式迁移;
- 为 自动定理证明(ATP)与大模型结合 提供了一个可行的工程框架: Verifier 可与形式化系统(Lean/Coq 等)进一步对接 Generator 可负责“草稿证明”,Verifier/形式系统负责“最后严审”
技术启示包括:
- 学会训练 LLM‑based reward model / judge,并能对长文本结构推理做稳定评价;
- 在 open‑ended reasoning 场景下,如何通过“扩展验证计算”弥补缺乏标准答案的问题。
5.2 对教育与学习场景的潜力
从应用角度看,DeepSeekMath‑V2 型模型可以做的,不仅是“给你一个答案”,而是:
- 提供 结构化、可自我审查的完整证明: 学生可以逐步对照,找到自己推理中断裂的地方; 老师可以用它快速生成多种解法,做对比讲解。
- 在出题 & 教学辅助方面: 自动生成带证明的练习题; 用 Verifier 协助筛选题目难度、证明严谨性; 对学生的解题过程做“机器审稿”,给出逻辑级反馈,而不仅仅是“对/错”。
5.3 对安全与可信 AI 的启发
“自验证”并不只适用于数学:
- 代码生成与审计: 生成器写代码,Verifier 对逻辑、边界条件、安全性做 LLM 级初审。
- 金融 / 法律等高风险领域: 让模型先给出一套推理过程,再由专门训练的 Verifier 检查逻辑一致性、合规性。
DeepSeekMath‑V2 证明了一件事:
把“自我批改”纳入训练对象,使得“推理可验证”从理念变成可操作的工程技术。
自验证还需要补的课
DeepSeek 在模型卡和论文摘要中也超级坦诚地指出:
- Verifier 本身也会犯错 甚至可能与 Generator 一起形成“共识性错误”(双双信任一个错误证明)。 这需要更多异构体系(人类、形式系统、他家模型)的交叉验证。
- 对超长证明、极复杂结构的处理仍有限 LLM 上下文、注意力机制对长度、结构的制约仍在; 对某些需要跨多页推理的高等数学证明,目前还远未达标。
- 扩展验证计算成本不低 高质量 Verifier 训练与 run‑time 使用都需要大量算力; 如何在工业应用中平衡效果与成本,是工程上必须面对的问题。
结合当前社区趋势,可以预期的方向包括:
- 与形式化证明系统深度集成 让 Verifier 输出不仅是“自然语言判断”, 而是能映射到 Lean/Coq 等中的形式证明 skeleton,做“硬验证”。
- 多模型交叉审查 不同架构 / 训练路径的 Verifier 相互“挑错”, 降低单一模型在特定偏见上的系统性失误。
- 开放自验证框架与 benchmark 把自验证训练 pipeline 更系统地开放给社区, 形成类似“数学版 SWE‑bench / MATH‑arena”的长期对抗 benchmark。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...