
许多公司最后的结局是:把钱投进了高大上的RAG方案,结果用户量不增反减,运维成本把人累垮了。有人把这当成教训,也有人当成反面教材。实际就是这样,别绕弯子。
事情得倒过来讲。先说为什么会有人把RAG当成救命稻草。问题实则很简单:现实里AI面对两大短板——时效性和专业性。你让一个模型用2023年的语料去回答2025年的问题,这答案就是过时的。就像你问朋友“今天股市咋样”,他回你去年的某只票的故事,能信吗?不能。这就是RAG能解决的第一件事:把最新、相关的内容拉进来,让回答有“今儿”这个维度。第二件事是专业性:当问题需要专业背景或多源信息时,单靠模型训练出来的通识知识常常不够,RAG可以把具体文档、评价、法规等拉进去,给出更贴近实际的答案。列如电商客服,顾客问“这款鞋子实际穿着感觉怎样”,通过检索最新客户评价和测评资料,系统能给出有依据的回复,不会乱编。
不过把“检索”这三字放大并不等于完美方案。许多场景根本不该动检索。打个比方,你去图书馆问“今天天气怎样”,馆员告知你去气象局,这就是盲目检索的荒谬。常见的寒暄、礼貌回应,或者简单FAQ,完全没必要去查资料,查了只会浪费成本,还可能把无关信息拉进来干扰回答。
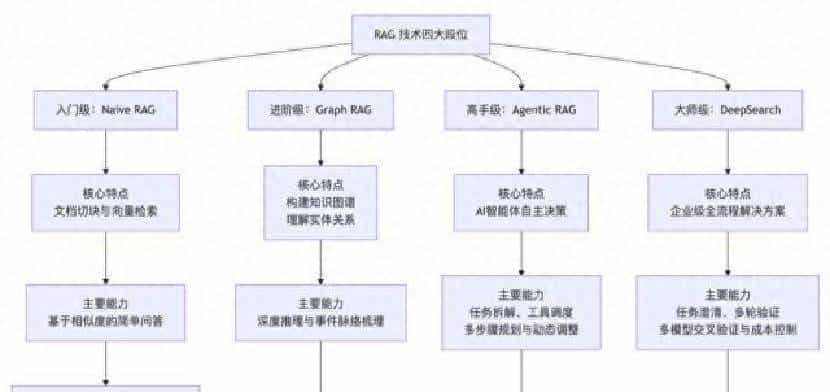
接下来详细讲技术上的层次,从入门到顶级,按能力和成本分四档。先说最简单的那一档:Naive RAG。做法就是把文档切块存好,用户提问就去匹配相关段落。实现容易,门槛低,但问题也明显。最麻烦的叫“找不到北”:用户问“后天呢”,系统没法理解“后天”指具体哪天的上下文。另一种病叫“长文本失忆症”:你把几百页资料放进去,系统往往只注意开头和结尾,中间大段信息像被过滤掉了。就像请人概括一本小说,他只看了头尾就交稿,说这书就是头尾的故事。结果就是信息片面,误导性大。适合场景是简单FAQ、静态知识库——成本低、收益稳,别搞复杂功能。
再往上就是Graph RAG。它不是简单检索,而是把信息组织成节点和关系,构建出知识图谱。这个思路能让系统知道“谁跟谁有关”“某事导致了什么后果”。在处理人物关系、因果链条时优势明显。把小说人物的一生做成时间线和关系网,那Naive RAG给的是碎片,Graph RAG能把事件串起来。但代价高,搭建图谱需要大量人工与规则,后续维护、数据更新也费事。可以想象成雇了个研究生持续整理资料,能力强但花钱多。适合需要复杂推理、跨领域关联的场景,列如法务或医疗这种对逻辑和证据链要求高的领域。
更进一步的是Agentic RAG。这类系统不只是去检索,还会判断何时检索、检索什么、如何把信息整合。它能像一个小团队那样分步工作:先问你预算和偏好,再去查价格、安排路线,最后输出一个旅行计划。也就是说它具备任务分解和工具调度能力。好处是交互更智能,但复杂度明显上升,每一步决策都可能产生额外的计算和调用成本。用户量一大,费用就显著起来。实现上需要精心设计策略和容错机制,不然容易变成“机智但贵得离谱”的东西。
最后一档是DeepSearch,企业级全套方案。它包含任务澄清、多轮验证、成本控制、跨模型校验等流程。面对复杂场景能做到多源比对和结果稳健性检验。问“哪只股票值得买”,它会先弄清你的风险偏好和持仓期限,然后拉取多套数据源做交叉验证,给出一套基于规则的提议。这个系统的确 强,但投入不菲:开发难度、数据接入、合规审查、持续维护,都是长期工程。能承受这套的,多是资金充足、对结果有极高要求的企业。
那么到底怎么选?别被名称吓住。看清业务场景最关键。场景很单一、问题重复、可以把答案写死的,用Naive就够;要是跨领域、需要理清关系链的,思考Graph;需要主动拆解任务、动态调整的,再上Agentic;真要做企业级的决策支持,可思考DeepSearch。还有一点必须注意:成本控制。Agentic很美丽,但每次“智能思考”都要付费。如果用户量大,运营成本可能比你预期高好几倍。我见过不少公司被“先进”技术概念忽悠,结果搞了个看起来高端但没用的系统。技术是为业务服务,不是为了显摆。
另一点是实施策略。别想着一口吃成胖子。先把基础做稳,Naive做好的话,已经能带来很大的改善。把检索、索引、向量表明、匹配策略打磨成熟,再逐步把图谱或智能调度加进去。技术每天都在变,今天看似复杂的方案,明天可能有更省事的替代品。选型像选鞋,合脚比贵更重大——思考数据量、用户规模、预算和团队能力,量力而行。
在判断是否该检索时,可以设个简单规则:答案是否需要最新信息或证据链?如果是,呼叫检索;不是,就直接回答。这样既控制成本,也能保持回答的准确性。我个人觉得,把复杂度放在真正能带来价值的地方,是常识但常常被忽视的事。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...