
Deep Cogito 发布了 Cogito v2.1 671B,CEO 在社交平台上直接宣称这是“由美国公司制造的最好的开源大语言模型”。

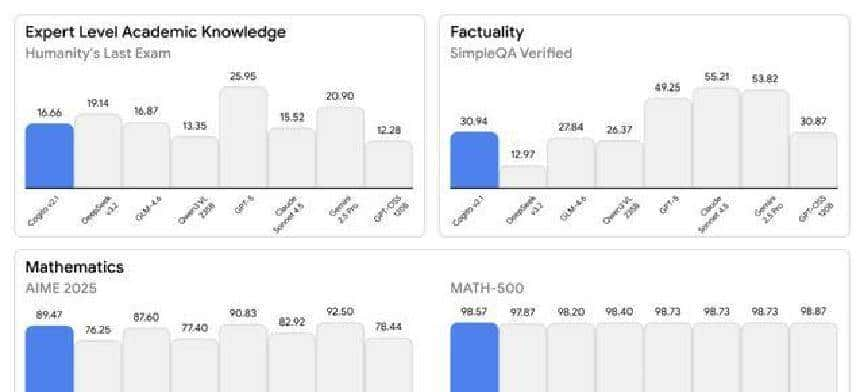
他还直接把一堆基准测尝试秀出来:GPQA Diamond 表现接近 GPT-5,MMLU 的成绩甚至把 Claude Sonnet 4.5 挤到后面,数学和代码相关的测试也把 Llama 系列甩在身后。光看图表,许多人第一反应是:这回真有看头,好像是一次美丽的反击。
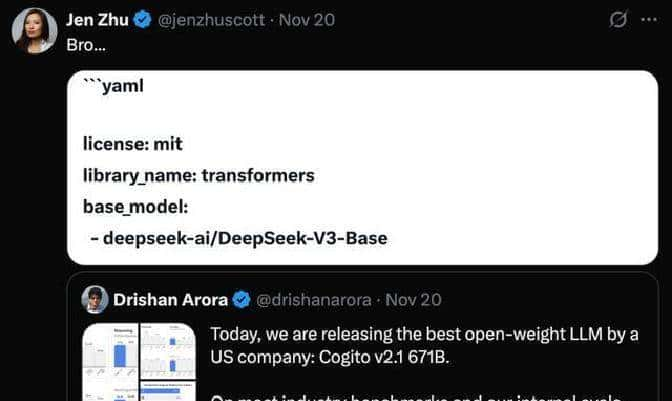
不过热闹没多久,细节就被人扒出来了。有人发现“671B”这个数字正好对上了 DeepSeek-V3 的参数规模;更关键的是,HuggingFace 上的模型配置里出现了一行:base_model:
deepseek-ai/DeepSeek-V3-Base。截图被传疯了,社区里开始讨论,背景比图表还精彩。
和之前那些死撑到被抓包才认错的例子不同,这次公司没有硬扯。Deep Cogito 直接承认:他们是基于 DeepSeek-V3-Base 做的分叉(fork),而且给出了自己的解释:目前预训练越来越像“卖电”的生意,大家都能买得到;真正稀缺的是怎么把一个基础模型“再训练”到前沿水平。换句话说,他们把别人的底座借来,用自己的方法把引擎重新调了一遍。
创始人 Drishan Arora 在公开说明里把这事儿说得更直白:在美国,能做出有竞争力的开源前沿模型的实验室寥寥,Meta 是例外,其他选择很少。所以选 DeepSeek 作为起点,是一个“显而易见”的路径。听着有点像拿邻居的车底盘做改装,自己去调悬挂、换发动机,然后对外说这是自家出品。
技术上,Deep Cogito 并没有从头跑一个 671B 的预训练。核心工作放在“后训练”(post-training)上,他们自己给这套流程起名叫“前沿后训练栈”。主要手段包括强化学习、一个叫做迭代蒸馏放大(IDA)的流程,以及所谓的“过程监督”(Process Supervision)。官方提到,他们用了数百个 GPU 节点来做大规模的分布式强化学习,目标之一是让模型在推理时走更短的“路径”,搜索更高效。通俗点说,就是不靠更大的参数堆,而是靠更机智的训练方式让模型回答问题更快、更精简。
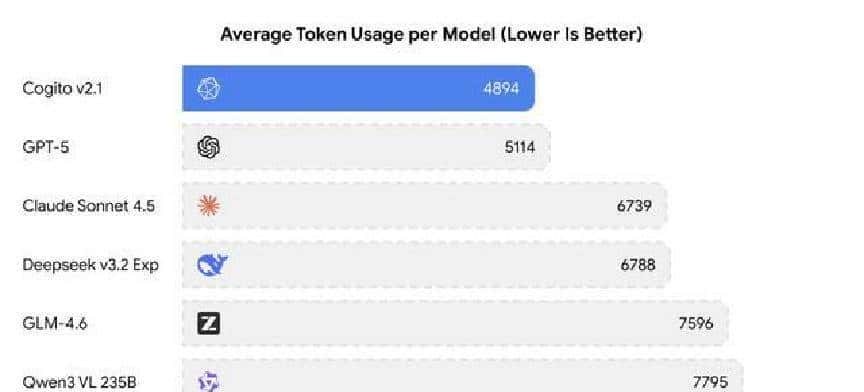
公司把一些关键数据也摆出来了,拿来证明“少用 token 同样能得好结果”。举个例子,在处理复杂逻辑题时,Cogito v2.1 平均耗费大约 4,894 个 Token,而 Google 的 Gemini 2.5 Pro 在同类任务上平均要用到 9,178 个 Token。数学基准 MATH-500 上,Cogito v2.1 得分 98.57%,略高于 DeepSeek v3.2 的 97.87%。在代码修复测试 SWE-Bench Verified 上,也给出了不错的通过率。这些数字被用来支持他们的论点:优化训练流程,可以用更少的计算资源换来更好的效果。
把时间线往前推一点,今年十月的时候,硅谷有两家火热的 AI 编程工具公司 Cursor 和 Windsurf 刚刚放出标榜“自研”的模型,社区当时还在庆祝。可过不了多久,有网友发现那些模型在推理时会冒出中文,甚至在越狱提问下承认自己源自中国的智谱 AI。那阵子大家的反应有点尴尬——像是借了隔壁家的工具,不好意思大声宣扬。
这回 Deep Cogito 的处理方式不大一样。他们既不遮掩底座是 DeepSeek,也不回避用美国身份去包装成果。技术文档里明确写了 base_model 字样,benchmark 数据也公开在页面上。关键在宣传口径上:把“用的是 DeepSeek 的底座、后训练在美国完成”这件事放在“由美国公司制造”的大标题下推销,听上去面子和里子都有点混合的味儿。有人觉得这是一种务实的工程选择;也有人觉得这是表面“美国制造”的一种表演。
围绕这个事儿,讨论主要聚焦在两点。一是把开源模型拿来优化再包装成“自家制造”,会不会误导公众去误判模型来源和贡献?二是后训练阶段如果被引导去加入特定的偏向,会不会偏离开源社区原本的共享精神?这些担忧在社交平台上有争论,但公司提交的技术报告里并没有直接证据显示他们在后训练中刻意灌输某种意识形态。换句话说,许多争论还停留在价值判断层面,而不是确凿的实际层面。
再说成本问题。把一个 671B 的模型从头预训练,动辄要投入数千万到上亿美元,这是公认的现实。用现成的高质量开源模型当起点,再花钱去做后训练,能把预算压下来,产品也能更快上线。对初创公司来说,这条路很吸引人:省钱、省时间,还能把精力放在差异化的后处理上。把技术稿里的表和图拿出来分析,许多团队选择这条路径并不意外,算得上是一种务实之举。
圈内的情绪挺微妙。有些人觉得这是一种机智的工程路线,是资源有限情况下的合理选择。部分人则不太喜爱这种“底座借来、牌子亮自己的”的做法,觉得有点像穿了别人的外套去拍照,现实里是穿得好看,背后却不是自己的手艺。硅谷对新对手的态度里,既有不甘也有不得不承认的现实:技术和话语权的博弈里,谁的名字写得更响亮,谁就更有话语权;同时,谁能把成果快速推向应用层面,谁就能吸引更多注意力。
证据方面并不复杂可查。HuggingFace 上那行配置“base_model:
deepseek-ai/DeepSeek-V3-Base”还能找到,Drishan 在 X(前 Twitter)上的宣言也有存档,Deep Cogito 的研究页面上列了他们声称的技术细节和 benchmark。换句话说,想要核验这些信息的人并不需要靠传闻,原始资料摆在那儿,大家可以自己去看。
讲到这儿,有一点和大家分享的感觉:技术圈的这些事儿,表面上是算法和 benchmark,底下实则是资源、话语权和市场节奏在拉扯。有人用“工程师的机智劲儿”去优化现有路线,也有人坚持“从零开始才算真本事”。两种观点都有道理,关键是要把真实信息摆清楚,让使用者、客户和社区都能看清楚这台机器到底是谁做的、哪儿来、怎么训练上去的。
这事里没有简单的对与错,更多是现实选择的权衡。你要是想深挖,去看 HuggingFace 的配置和 Deep Cogito 的研究页,数据和配置文件都没被擦掉,相关声明也有记录。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...