需要解决的问题是这样的:
有一名为“24年12月-25年6月.zip”内有若干个格式一样的pdf文档,每份pdf文档内为若干个表格,记录着当天采购蔬菜的种类、单价、数量、供货单位、日期等,样式如下:

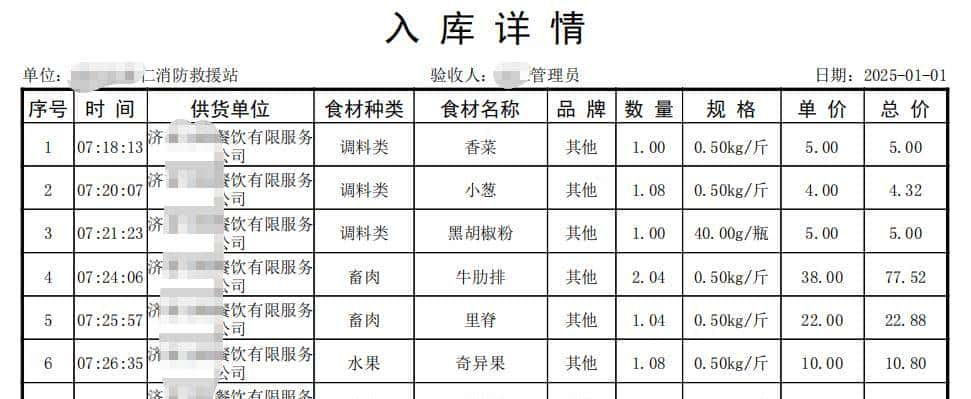
需求是把所有的pdf里的表格提取出来,按“食材名称”分类汇总到单独的工作表,每个表里还要自动生成“单价”和“日期”的拆线图,方便查看价格波动。
这是一个典型的问题——重复性高、工作量大、容易出错。如果你也遇到过类似的场景:需要从一堆pdf里挖数据、还要分类整理,并进行可视化分析,那么这篇python高效办公攻略就是你的救星!!!
核心任务拆解:
1、解压筛选文件。从zip压缩包内找出所有的pdf文件,排除其他格式文件。
2、提取表格内容。精准读取筛选到的pdf文件中的表格内容。
3、数据整理分析。补全缺失的信息,如日期没有在表格范围需要抠出。供货单位为空的数据行需要过滤等。
4、分类汇总保存。按“食材名称”分组,每种蔬菜单独保存到工作表。
5、插入动态图表。为每个工作表单独添加“单价”和“日期”为数据的折线图,带数据标签,这样能直观展示变化趋势。
解决过程:
解决方案:
使用zipfile筛选文件,pdfplumber进行表格内容提取,pandas进行数据处理,openpyxl创建动态图表。
第一步、导入所需要的模块
import pdfplumber
from zipfile import ZipFile
from openpyxl import load_workbook
from openpyxl.chart import LineChart, Reference
from openpyxl.chart.label import DataLabelList
import pandas as pd
import time第二步、初始化
start_time = time.time() # 记录开始时间,最后算总耗时
path = r"E:24年12月-25年6月.zip" # 压缩包路径
df_list = [] # 存所有提取到的数据第三步、读取数据
with ZipFile(path, 'r', metadata_encoding='gbk') as zip: # 避免中文文件名乱码
for file in zip.namelist(): # 遍历压缩包里所有文件
if file.endswith(".pdf"): # 只处理PDF
with zip.open(file) as pdf: # 从压缩包里打开PDF文件
with pdfplumber.open(pdf) as p: # 用pdfplumber解析PDF
for page in p.pages: # 遍历每一页
pdf_table = page.extract_table() # 提取当前页的表格
if pdf_table: # 如果这页有表格
# 转成DataFrame,第一行当列名(表头)
df = pd.DataFrame(pdf_table[1:], columns=pdf_table[0])
# 从PDF文本中抠日期
df["日期"] = page.extract_text()[35:45]
# 过滤掉“供货单位”为空的脏数据
df.dropna(subset=["供货单位"], inplace=True)
df_list.append(df) # 加入总列表第四步、数据清洗整理
dfs = pd.concat(df_list) # 合并所有PDF的数据
dfs["单 价"] = dfs["单 价"].apply(lambda x: float(x)) # 单价转数字
dfs['日期'] = pd.to_datetime(dfs['日期']) # 日期转标准格式
dfs.sort_values("日期", inplace=True) # 按日期排序
df_group = dfs.groupby(by="食材名称") # 按“食材名称”分组第五步、分组数据保存数据到工作簿
out_path = r"E:24年12月-25年6月.xlsx"
with pd.ExcelWriter(out_path) as w:
for name, df in df_group: # 遍历每个蔬菜分组
df.to_excel(w, sheet_name=name, index=False) # 写入单独工作表第六步、动态生成图表
wb = load_workbook(out_path) # 重新加载刚生成的Excel
for ws in wb.worksheets: # 遍历每个工作表
if ws.max_row > 2: # 只处理有数据的表(至少3行:表头+1行数据)
c1 = LineChart() # 创建折线图对象
# 获取表头(第一行),找到“单价”和“日期”列的位置
headers = [cell.value for cell in next(ws.iter_rows(min_row=1, max_row=1))]
price_col = headers.index("单 价") + 1
date_col = headers.index("日期") + 1
data = Reference(ws, min_col=price_col, max_col=price_col,
min_row=2, max_row=ws.max_row) # 从第2行开始(跳过表头)
riqi = Reference(ws, min_col=date_col, max_col=date_col,
min_row=2, max_row=ws.max_row)
# 生成图表
c1.add_data(data, titles_from_data=True) # 单价
c1.set_categories(riqi) # X轴为日期
c1.legend = None # 不显示图例(由于只有一组数据)
c1.title = "价格变化趋势" # 图表标题
c1.style = 24 # 预设样式(蓝色折线+圆点)
# 坐标轴优化:显示数值标签,日期格式化
c1.y_axis.delete = False # Y轴可见
c1.x_axis.delete = False # X轴可见
c1.x_axis.number_format = 'YYYY-MM-DD' # 日期显示为“2024-01-01”格式
# 数据标签:只显示单价数值(不显示日期类别名)
if c1.series:
series = c1.series[0]
series.name = None
series.dLbls = DataLabelList()
series.dLbls.showVal = True # 显示数值
series.dLbls.showCatName = False # 不显示类别名(即不显示日期)
series.dLbls.showSerName = False
series.dLbls.showSeriesName = False # 不显示系列名称
series.dLbls.showLegendKey = False # 不显示图例标识
series.dLbls.showPercent = False # 不显示百分比
series.dLbls.showBubbleSize = False # 不显示气泡大小
# 把图表插入工作表数据下方2行的位置
row_chart = ws.max_row + 2
ws.add_chart(c1, f"A{row_chart}")第七步、保存工作簿,显示运行结果
# 保存Excel
wb.save(r"E:24年12月-25年6月_图表.xlsx")
end_time = time.time()
print(f"共处理{len(dfs)}条数据
{len(df_group)}种蔬菜
用时{end_time-start_time:.2f}秒")运行结果:
运行这段代码,原本需要手动操作数个小时的工作,目前只需要66秒就能完成,最终生成包含所有蔬菜的数据文件,每种蔬菜都有独立的工作表和数据趋势图。


需要注意的是,这段代码使用ZipFile不用手动解压压缩包就可以直接读取PDF内容,这样能够避免文件乱放;其中metadata_encoding='gbk'可以防止中文文件名乱码问题。
日期可以通过page.extract_text()[35:45]从pdf的文本中抠取,如果日期位置并不固定使用正则表达式匹配更稳键。可参考下面的代码:
text = page.extract_text()
date_match = re.search(r'(d{4}[-年]d{1,2}[-月]d{1,2}[日]?)', text)
if date_match:
df["日期"] = date_match.group(1)面对此类繁琐操作,办公自动化无疑是提高效率、保证数据准确性的利器,你只需几步,就能告别手动操作的烦恼,让数据处理变得轻松高效。如果你也被类似问题所困扰,不妨试试这段代码,信任它会给你带来意想不到的便利!
最后,别忘了点赞、转发这篇文章,让你身边的同事和朋友一起提高工作效率~~~
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...