
编者按:为应对边缘侧大模型推理中现有动态随机存取存储器(dynamic random access memory, DRAM)近存计算架构算力受限、异构资源协同低效、场景适配能力不足的关键问题,北京大学教授孙广宇团队创新性地提出基于混合键合工艺的H2-LLM通用架构模板和“以数据为中心”的跨层级数据流抽象,通过三维堆叠突破算力瓶颈、可重构计算单元动态调度算子,显著提升了边缘场景的算力利用率与时延性能;其设计的空间探索框架进一步实现面向终端设备、边缘服务器等场景的自动化寻优,为端侧大模型推理芯片的架构设计提供了新思路。

在边缘端平台部署的大语言模型
近年来,大语言模型(large language models, LLMs)因其在管理和执行各种复杂任务方面的强劲能力,具备在边缘端平台大规模部署的潜力,如智能家居设备、家用服务器和智能座舱等。如图1所示,个人聊天助手可为用户的问题提供即时回复;智能家居设备或智能座舱中的虚拟助手可接收用户指令,并与多个应用接口或固件进行交互;酒店环境中的接待机器人可获取顾客的请求并提供适当的引导。此外,由于数据隐私问题,LLMs也可以部署在私有边缘服务器上,用于创意团队内部的协作。
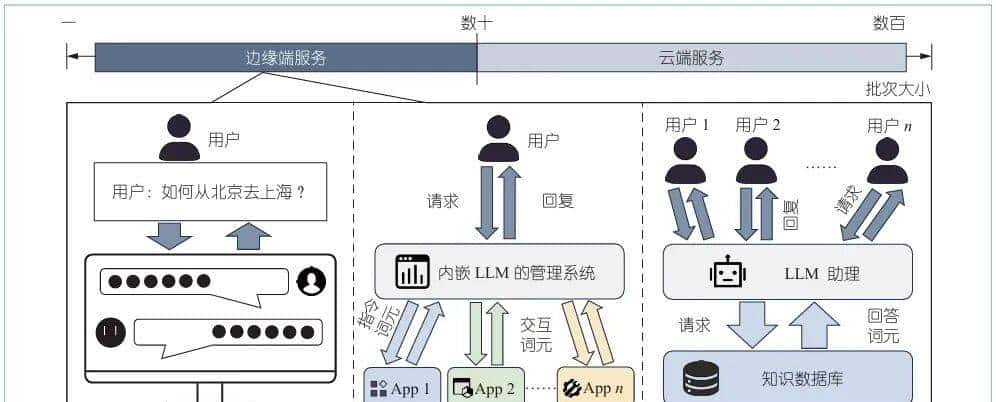
图1 边缘LLM服务器
LLMs的推理具有两个关键阶段,在预填充阶段模型并行处理大量提示词,体现出计算密集性质;而解码阶段则逐词生成,体现出访存密集性质。边缘端LLM推理进一步展现出两大主要特征:第一,由于个性化特性和对低延迟交互的需求,边缘端LLM服务一般一次处理少量请求,即低批次;其次,个性化LLM推理应用在不同使用场景下表现出不同的负载分布,即随场景不同,LLM推理的两个阶段的负载不同。因此,兼顾预填充和解码两个阶段的高效处理对于提升用户体验至关重大。
支持近存处理的异构加速器
为了高效处理LLMs推理中的预填充和解码阶段,工业界和学术界各自提出了支持近存处理(near-memory processing,NMP)的异构加速器。在已有的加速器设计中,除了传统的聚焦式处理器之外,处理引擎(processing engine,PE)也被部署到内存通道中。通过驱动这些通道内的PE并行执行,它们可以利用动态随机存取存储器(dynamic random access memory, DRAM)的存储体级并行性,从而为LLMs推理中的访存密集型算子提供充足的带宽。
片内近存处理加速器的局限性
现有支持近存处理的异构LLM加速器一般将NMP处理引擎与DRAM阵列放置在同一片内存芯片内(本文称为“片内NMP”)。这些片内NMP的算力–带宽比很低,一般为1~2。如此低下的计算能力阻碍了片内NMP架构加速低批次LLM推理。一方面,虽然片内NMP架构能为单批次的全连接算子带来显著的加速效果,但其低计算能力严重限制了批次大小(batch size, BS)增加时的推理性能。思考到解码阶段中低批次(而非单批次)的全连接算子对聚焦式处理器而言依旧有内存瓶颈,现有的异构片内NMP设计只能为这些算子提供较低的有效计算能力。另一方面,虽然多头注意力算子在片内NMP架构上也能实现显著加速,但随着分组查询注意力和多查询注意力算法的采用,注意力算子的计算强度也随之增加,因此面临着与低批次全连接算子类似的问题。
为了阐明这一局限性,本研究采用LLaMA3 8B模型中的算子,在8个三星LPDDR5-PIM通道上进行了屋顶线分析。对于全连接算子,将批次大小从1调整到16;对于注意力算子,使键值(key-value, KV)对头数在1~32变化。如图2所示,虽然当批次大小小于8或KV对头数大于4时,片内NMP能够实现加速,但其优势因有限的计算能力而逐渐减弱。当批次大小大于等于8或KV对头数小于等于4时,片内NMP无法提供性能提升,而此时聚焦式处理器仍处于内存瓶颈状态,同样无法提供充分加速。这样就导致了系统的资源利用率低。因此,有必要增强NMP中PE的计算能力,以更好地缓解低批次LLM推理中的内存瓶颈问题。

图2 片内NMP的屋顶线分析
混合键合技术带来的机遇
片内NMP的低计算能力源于其采用的DRAM工艺:第一,与一样技术节点的互补金属氧化物半导体(complementary metal-oxide-semiconductor, CMOS)工艺相比,DRAM工艺的晶体管的速度为其1/3,逻辑密度低至其1/10;其次,DRAM芯片一般配备更少的金属层,导致布线密度低于逻辑芯片;再者,为避免过高的存储密度损失,可用于片内NMP中PE的面积预算极为有限,难以容纳更多的PE。
近期,混合键合(hybrid bonding,HB)作为一种新一代封装技术崭露头角。如图3所示,它将DRAM芯片垂直堆叠在逻辑芯片之上,并通过铜−铜直接键合连接。这种方式下,HB凭借其极高的输入/输出(input/output, I/O)并行度提供巨大的带宽。此外,与2.5D集成技术相比,HB的低寄生电容提升了其能效,使其更适用于边缘端加速器设计。更重大的是,与片内NMP相比,PE可以定制在逻辑芯片上,从而能够提升计算能力。可以采用较不先进的逻辑工艺来满足边缘端加速器的成本和良率要求。

图3 混合键合封装工艺图
尽管HB技术展现出诱人的特性,但其集成开销给适用于边缘端低批次LLM推理的加速器设计带来了挑战。HB技术需要大量的内存控制器来驱动其数量庞大的I/O引脚,这挤占了本可用于计算逻辑的可用面积。减少I/O引脚数量虽然能为计算逻辑腾出更多面积,但由此导致的带宽下降会限制计算利用率,阻碍加速器性能提升。
现有架构数据流设计的局限性
除了HB-NMP架构设计面临的挑战外,现有的支持NMP的异构LLM加速器的数据流设计在边缘端低批次LLM推理场景下依旧存在局限性。大多数现有方案将固定的算子子集映射到NMP的PE上执行。这种固定算子映射在大批次云推理中可能性能良好,由于不同算子的计算强度差异显著。不过,在低批次推理中,它们无法充分利用NMP的加速能力,也未能有效利用算法中诸如并行Transformer变体提供的并行性。
H2-LLM的硬件架构
架构总览
如图4(a)所示,异构混合键合的低批次大语言模型(heterogeneous hybrid-bonding-based low-batch LLM, H2-LLM)的架构包含一个聚焦式处理器和一个支持NMP的存储系统。聚焦式处理器是一个类xPU,如图形处理器(graphics processing unit, GPU)、张量处理器(tensor Processing unit, TPU)等的高性能加速器,负责执行计算密集型算子,它还负责按照数据流调度整个LLM推理过程;支持NMP的存储系统包含多个存储通道,这些通道既可以是带有单个存储芯片的常规DRAM通道,也可以是基于混合键合技术的NMP通道,其存储芯片堆叠在一个逻辑芯片之上。

图4 H2-LLM架构总览
每个HB-NMP通道的存储芯片如图4(b)所示,其中的DRAM存储体可在两种模式下访问:一是常规模式,当HB-NMP通道不进行计算时,聚焦式处理器可以通过外部接口访问每个DRAM存储体;二是NMP模式,当HB-NMP通道执行近存计算时,所有DRAM存储体可以通过各自独立的混合键合控制器被NMP处理单元并行访问。限制一次只能激活一种模式,以避免DRAM存储体的行缓冲冲突。对于每个常规通道,其DRAM存储体不包含HB接口,仅通过外部存储接口(类似于HB-NMP通道的常规模式)服务于聚焦式处理器的存储访问。
图4(b)的下部描绘了HB-NMP通道的逻辑芯片架构。NMP控制器通过外部接口接收来自聚焦式处理器的命令,并驱动NMP处理单元执行计算或存储访问。每个NMP处理单元与一个DRAM存储体配对,可通过PE的HB控制器访问该存储体。这种方式使得NMP的PE能够并行执行,从而提供丰富的NMP带宽。一个输入全局缓冲区在所有计算单元之间共享,以避免将输入张量复制到每个DRAM存储体。
HB-NMP的处理单元设计如图4(c)所示。每个计算单元包含多个浮点运算单元,用于在解码阶段执行低批次通用矩阵乘法算子的乘加运算。权重和输出缓冲区分布在每个计算单元中,使它们能够计算不同的输出分块。计算单元根据来自NMP控制器的指令,由控制器驱动浮点运算单元进行计算或驱动HB控制器进行存储访问。
NMP算子执行流与命令接口
H2-LLM采用卸载式三阶段执行:聚焦式处理器分发输入至HB-NMP通道,所有NMP处理单元并行计算,聚焦式处理器收集合并结果。针对通用矩阵乘法算子,通过解析模型优化通道间工作负载划分,并基于传输开销最小化,求解出权重张量维度的最优分块因子。通道内执行时,输入、输出张量分散存储于DRAM存储体,采用输出固定的数据流策略,处理单元依次加载输入分块与权重分块执行乘加运算,累加完成后写回结果。批处理的通用矩阵乘法则拆分为子任务分配到各内存通道。
配合这种三阶段执行流,H2-LLM通过4类命令驱动HB-NMP通道:模式切换命令,作为内存屏障隔离聚焦式处理器访问,当执行起始指令时携带分块参数;NMP计算命令,以粗粒度控制整个通道执行一个权重分块的计算,NMP控制器将其解包为细粒度指令;输入全局缓冲区搬移命令,驱动HB I/O将输入分块从DRAM传输至全局缓冲区;本地缓冲区搬移命令,粗粒度控制PE本地权重、输出缓冲区与DRAM存储体间的数据传输,通过指令调度可与计算重叠执行。
H2-LLM的数据流
H2-LLM提出以数据为中心的数据流抽象,包含算子−通道绑定和算子执行映射两个阶段。这种数据流抽象并不局限于本工作的架构设计。它可以推广到所有基于NMP的异构大语言模型加速器中。本研究同样将下述数据流表明引入设计空间探索框架中,以搜索最优数据流。
算子−通道绑定的过程如图5所示。第一进行内存访问组切分,将Transformer层的算子集拆解为由内存访问组构成的有序依赖链,确保每个内存访问组内部算子无外部依赖,实现层间串行、层内并行。随后,执行粗粒度绑定,在每个内存访问组内提取弱连通集合形成内存划分组。在这一步,通道资源被抽象为集合,通过组−通道映射为每个内存划分组分配互斥通道子集。此过程遵循两大核心约束:通道互斥性约束确保不同内存划分组无通道重叠,通道利用率约束则强制所有通道被占用。最后,进行细粒度绑定,在内存划分组内部,按算子依赖关系分层,为每层独立算子进一步分配具体通道。

图5 算子−通道绑定过程示例
基于通道绑定结果,算子执行映射分阶段实施差异化策略。在预填充阶段,所有算子均由聚焦式处理器通过常规通道执行,充分发挥其算力密集特性对长序列并行处理的优势。而在解码阶段则采用异构执行策略:对于纯常规通道绑定的算子由聚焦式处理器执行。纯NMP通道绑定的算子由NMP的PE执行。对于混合通道绑定的算子,支持算子分裂——对于通用矩阵乘法算子,沿输出特征维度进行拆分,子任务分别分配给聚焦式处理器和NMP的PE;对于注意力算子,则将其子运算如查询(query, Q)、键(key, K)、值(value, V)投影解耦后动态分配至不同计算模块。
在Transformer层执行这一层次,系统采取分级流水:预填充阶段所有算子由聚焦式处理器串行执行;解码阶段按内存访问组顺序推进,每个内存访问组内的内存划分组并行执行。内存划分时组内部按算子依赖层级串行,层级内算子则并行执行。
H2-LLM的设计空间探索框架
图6给出了H2-LLM的设计空间探索(design space exploration, DSE)框架。它接受3个输入:工作负载信息,包含LLM的模型定义以及特定场景信息(例如,预期的批次大小、提示词长度、解码长度等);架构参数,包含一系列候选架构的描述,包括HB-NMP的通道数量、PE算力和NMP带宽的权衡配置以及全局、权重、输出缓冲区的容量。如果只有一个架构候选,框架可用于为该指定架构找出最优数据流;设计空间探索设置,包含设计空间探索算法的迭代轮数、优化目标等参数。
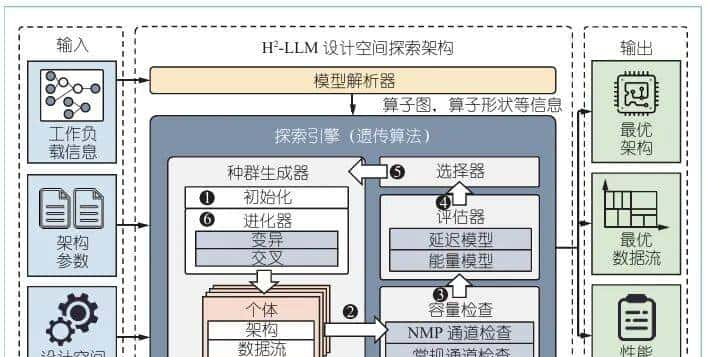
图6 H2-LLM的设计空间探索框架
接收这些输入后,框架第一使用模型解析器来提取Transformer层的算子图以及每个算子的张量形状。然后,这些信息连同架构参数和设计空间探索设置一起被发送到探索引擎。探索引擎将在给定场景下搜索最优的架构−数据流协同设计。完成DSE后,将报告最优设计及其性能评估结果。
探索引擎采用遗传算法来找出最优设计。探索引擎从设计空间中采样一批参数组合个体完成初始化,随后进行合法化处理,并评估其中性能最优的K个。然后,通过对这K个最优个体应用遗传操作符,即重采样、变异(改变一部分设计参数)、交叉(组合无冲突的两个个体中的设计参数)进化出新种群,并启动新一轮迭代。经过若干轮重复后,探索引擎终止并报告最优设计。
架构与数据流的评估实验
本研究选择OPT 6.7B、LLaMA3 8B、PaLM 8B模型进行评估。这些模型具有不同的Transformer算法架构,并分别采用多头注意力、分组查询注意力和多查询注意力机制。所有模型均使用FP16数据类型。为评估边缘端低批次LLM推理在不同场景下的性能,将批次大小配置为1、4、16,并根据开源数据集Human-Eval (HE)、ShareGPT(SG)、LongBench (LB)、 LooGLE (LG)选取测试的输入与解码的词元数量。
H2-LLM的聚焦式处理器配置为类似于谷歌TPU的处理器,包含合理的矩阵算力、向量算力和缓存容量配比。为测量面积成本,使用Chisel语言实现浮点运算单元,并采用40 nm工艺进行综合,以获得合理的架构参数配置。对于硬件性能评估,通过扩展Ramulator2来模拟NMP PE的计算,并采用支持评估注意力算子融合的Tileflow性能模型评估聚焦式处理器算子的性能,将结果注入模拟器以进行端到端评估。对于能耗评估,采用公开的数据来评估系统能耗。
图7给出了H2-LLM在4个开源数据集上不同批次大小的端到端延迟和能效与3种基线架构(仅聚焦式处理器、片内NMP、算力增强的片内NMP)的对比,对比中所有架构统一使用以数据为中心的数据流表明。结果显示,在端到端延迟上H2-LLM方法显著优于传统方案。相比表现最好的基线架构(算力增强的片内NMP),其在解码密集型任务(HE/SG)上加速3.81倍(几何平均值),在预填充密集型任务(LB/LG)上加速1.94倍,整体平均加速2.71倍。能效方面,H2-LLM比能效表现相对较好的两种NMP基线架构分别提升1.48和1.54倍。
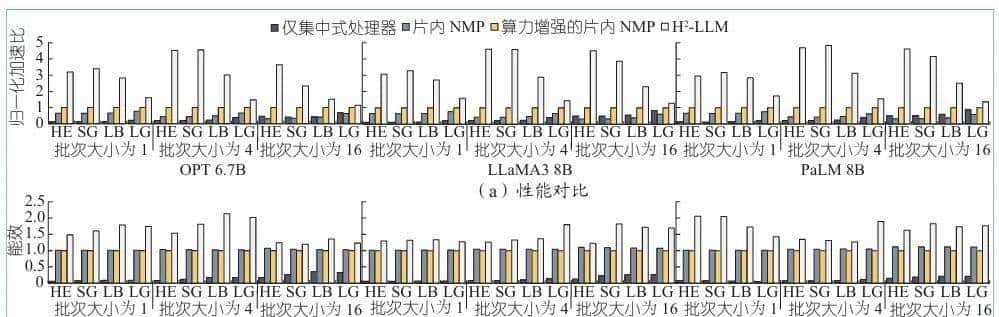
图7 端到端性能与能效对比实验
图8给出了H2-LLM经设计空间探索的数据流设计和4种现有方案(固定使用NMP处理注意力算子的数据流Attn-NMP;使用NMP处理注意力算子,并切分全连接算子分配给NMP和聚焦式处理器的数据流Attn-NMP-Split;使用NMP处理全连接算子的数据流FC-NMP;以计算为中心表明的数据流CC-NMP)的性能对比,所有数据流表明采用一样的H2-LLM架构。H2-LLM通过优化算子映射与算子分裂,比基线数据流方案中较好的FC-NMP和CC-NMP分别加速1.37和1.11倍,端到端性能更优。

图8 与已有数据流的对比实验
结束语
随着大语言模型在边缘计算场景的广泛应用,低批次推理中预填充与解码阶段的动态负载特征对硬件架构提出了严峻挑战。不过,现有片内近存处理方案因DRAM工艺限制,难以兼顾计算能力与带宽需求。为此,本研究提出H2-LLM异构加速架构:通过创新的异构架构设计对混合键合的计算能力与带宽进行权衡,满足场景对硬件性能的需求;同时提出以数据为中心的数据流抽象方法,支持算子分裂与异构执行策略,充分释放低批次并行潜力。与现有片内近存处理架构和数据流实现相比,H2-LLM在性能和能效上均实现了显著提升,为边缘端的高效模型推理提供了新范式。
李聪
北京大学博士研究生。主要研究方向为面向数据密集型应用的软硬件协同优化、机器学习系统。
leesou@pku.edu.cn

尹奕涵
北京大学博士研究生。主要研究方向为机器学习系统。
yyhsess2021@stu.pku.edu.cn

孙广宇
CCF专业会员。北京大学长聘教授。主要研究方向为领域定制体系架构的设计与自动化,包括高能效计算架构、新型存储架构、DTCO/ STCO。
gsun@pku.edu.cn

本文发表于2025年第7期《计算》。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...