
交叉熵
交叉熵是信息论中的一个重大致念,主要用于度量两个概率分布间的差异性。是分类问题中常常使用的一种损失函数。
一般使用交叉熵作为损失函数时,在模型的输出层总会接一个softmax函数(用来获得结果分布)。
交叉熵公式:

用来衡量真实概率分布 和预测标签分布
和预测标签分布 之间的差异;
之间的差异;
要了解交叉熵就需要先了解下述概念:
- 信息量
信息熵:“信息是用来消除随机不确定性的东西”,也就是说衡量信息量的大小就是看这个信息消除不确定性的程度。
信息量的大小与信息发生的概率成反比。概率越大,信息量越小。概率越小,信息量越大。 例如:”2018年中国队成功进入世界杯“,从直觉上来看,这句话具有很大的信息量。由于中国队进入世界杯的不确定性因素很大,发生的概率很小;
设某一事件发生的概率为P(x),其信息量表明为:

- 信息熵
信息熵也被称为熵,用来表明所有信息量的期望;
期望是试验中每次可能结果的概率乘以其结果的总和。
所以信息量的熵可表明为:(这里的X XX是一个离散型随机变量)

- 相对熵(KL散度)
如果对于同一个随机变量 有两个单独的概率分布
有两个单独的概率分布  和
和 ,则我们可以使用KL散度来衡量这两个概率分布之间的差异。
,则我们可以使用KL散度来衡量这两个概率分布之间的差异。
直接上公式

KL散度越小,表明 和的分布更加接近。
列如在一个三分类任务中(例如,猫狗马分类器),  分别代表猫,狗,马。
分别代表猫,狗,马。
例如一张猫的图片真实分布 和
和 ,计算KL散度:
,计算KL散度:
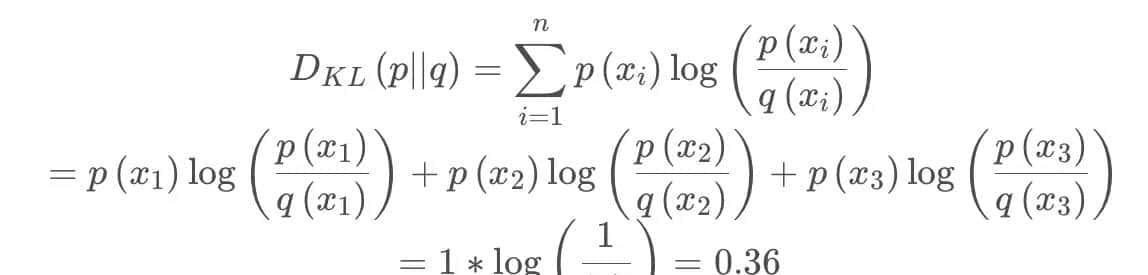
-
交叉熵
将KL散度公式拆开:
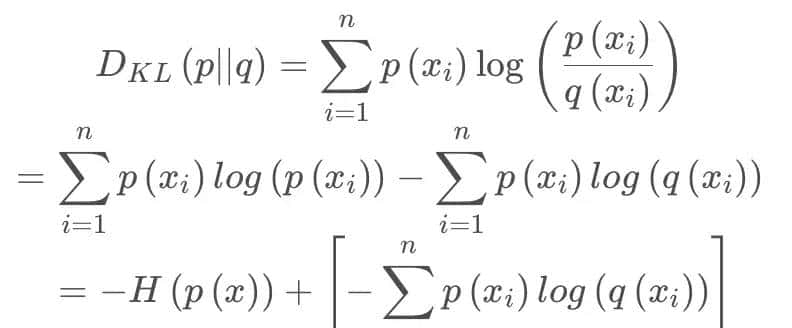
前者  表明信息熵,后者即为交叉熵,
表明信息熵,后者即为交叉熵,KL散度 = 交叉熵 - 信息熵
交叉熵公式为:
交叉熵等于KL散度加上一个常量(信息熵),且公式相比KL散度更加容易计算,所以在机器学习中常常使用交叉熵损失函数来计算loss就行了。
Focal loss损失函数
Focal Loss的引入主要是为了解决**难易样本数量不平衡****(注意,有区别于正负样本数量不平衡)的问题,实际可以使用的范围超级广泛。
本文的作者认为,易分样本(即,置信度高的样本)对模型的提升效果超级小,模型应该主要关注与那些难分样本。一个简单的思想:把高置信度(p)样本的损失再降低一些不就好了吗!
focal loss函数公式:

其中, 为类别权重,用来权衡正负样本不均衡问题;
为类别权重,用来权衡正负样本不均衡问题; 表明难分样本权重,用来衡量难分样本和易分样本;
表明难分样本权重,用来衡量难分样本和易分样本;
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...