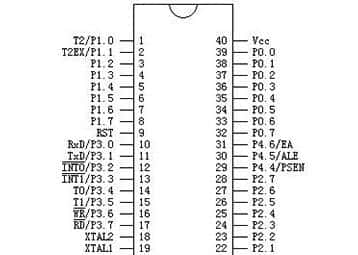
import os
import json
import pandas as pd
import openpyxl
import glob
from pathlib import Path
def read_config(config_path):
"""
读取配置文件
Args:
config_path (str): 配置文件路径
Returns:
dict: 配置字典
"""
try:
with open(config_path, 'r', encoding='utf-8') as f:
config = json.load(f)
print(f"成功读取配置文件: {config_path}")
return config
except Exception as e:
print(f"读取配置文件失败: {e}")
return None
def get_file_info_recursive(directory, extension):
"""
递归统计指定目录及其所有子目录中指定扩展名的文件
Args:
directory (str): 目录路径
extension (str): 文件扩展名
Returns:
tuple: (是否存在文件, 文件总大小(GB)/文件数量, 文件列表)
"""
file_list = []
# 使用os.walk递归遍历所有子目录
for root, dirs, files in os.walk(directory):
for file in files:
if file.endswith(extension):
file_path = os.path.join(root, file)
file_list.append(file_path)
has_files = len(file_list) > 0
if extension == '.bag':
# 对于bag文件,计算总大小
total_size = 0
for file_path in file_list:
try:
total_size += os.path.getsize(file_path)
except OSError:
print(f"无法获取文件大小: {file_path}")
# 转换为GB并保留2位小数
total_size_gb = round(total_size / (1024 ** 3), 2) if has_files else 0
return has_files, total_size_gb, file_list
else:
# 对于其他文件类型,返回数量
return has_files, len(file_list), file_list
def get_detailed_file_info(folder_path, file_types, size_unit='MB'):
"""
获取详细文件信息(用于泊车部分)
Args:
folder_path (str): 文件夹路径
file_types (list): 文件类型列表,如 ['.bag', '.blf']
size_unit (str): 大小单位,'GB' 或 'MB'
Returns:
dict: 包含文件数量、大小列表和格式化字符串的信息
"""
result = {
'exists': False,
'count': 0,
'sizes': [],
'formatted_str': '无'
}
try:
all_files = []
# 收集所有匹配的文件
for file_type in file_types:
pattern = os.path.join(folder_path, f"*{file_type}")
files = glob.glob(pattern, recursive=False)
# 如果不区分大小写的匹配
if not files:
pattern = os.path.join(folder_path, f"*{file_type.lower()}")
files = glob.glob(pattern, recursive=False)
if not files:
pattern = os.path.join(folder_path, f"*{file_type.upper()}")
files = glob.glob(pattern, recursive=False)
all_files.extend(files)
if not all_files:
return result
result['exists'] = True
result['count'] = len(all_files)
print("----所有文件名称为----", all_files)
# 计算每个文件的大小
for file in all_files:
try:
path = Path(file)
file_size = path.stat().st_size
# file_size = os.path.getsize(file)
if size_unit == 'GB':
converted_size = round(file_size / (1024 ** 3), 2)
else: # MB
converted_size = round(file_size / (1024 ** 2), 2)
result['sizes'].append(converted_size)
except Exception as e:
print(f"获取文件大小失败 {file}: {e}")
print("====失败原因====", e)
result['sizes'].append(0)
# 生成格式化字符串
if result['sizes']:
sizes_str = "和".join([str(size) for size in result['sizes']])
result['formatted_str'] = f"数量:{result['count']} 分别为:{sizes_str}"
return result
except Exception as e:
print(f"获取详细文件信息失败 {folder_path}: {e}")
return result
def normalize_path(path):
"""
将路径统一转换为使用反斜杠
Args:
path (str): 原始路径
Returns:
str: 使用反斜杠的路径
"""
return path.replace('/', '\')
def process_drive_data(config, output_dir):
"""
处理行车数据
Args:
config (dict): 配置字典
output_dir (str): 输出目录
Returns:
bool: 处理是否成功
"""
try:
drive_config = config.get('drive_list', {})
date = drive_config.get('date', '')
ros = drive_config.get('ros', '')
route_path = drive_config.get('route_path', '')
car_dict = drive_config.get('car_dict', {})
if not all([date, ros, route_path, car_dict]):
print("行车配置信息不完整")
return False
# 创建Excel写入器
excel_path = os.path.join(output_dir, f"行车_{date}.xlsx")
with pd.ExcelWriter(excel_path, engine='openpyxl') as writer:
for car_type, car_numbers in car_dict.items():
for car_number in car_numbers:
# 创建sheet名称:车型_车号
sheet_name = f"{car_type}_{car_number}"
print(f"处理行车数据: {sheet_name}")
# 构建基础路径
base_path = os.path.join(route_path, car_type, str(car_number), date, ros)
# 检查路径是否存在
if not os.path.exists(base_path):
print(f"路径不存在: {base_path}")
# 创建空DataFrame
empty_df = pd.DataFrame(columns=['ROS_BAG路径', '是否有bag文件', 'bag文件大小(GB)',
'是否有asc文件', 'asc文件数量',
'是否有avi文件', 'avi文件数量'])
empty_df.to_excel(writer, sheet_name=sheet_name, index=False)
continue
# 存储结果的列表
results = []
# 遍历base_path下的所有子文件夹
for subfolder in os.listdir(base_path):
subfolder_path = os.path.join(base_path, subfolder)
# 确保是文件夹
if not os.path.isdir(subfolder_path):
continue
print(f" 处理子文件夹: {subfolder}")
# 统计各类文件信息 - 使用递归统计
has_bag, bag_size, bag_files = get_file_info_recursive(subfolder_path, '.bag')
has_asc, asc_count, asc_files = get_file_info_recursive(subfolder_path, '.asc')
has_avi, avi_count, avi_files = get_file_info_recursive(subfolder_path, '.avi')
# 统一使用反斜杠路径
normalized_path = normalize_path(subfolder_path)
# 添加到结果列表,ROS_BAG路径放在第一位
results.append({
'ROS_BAG路径': normalized_path,
'是否有bag文件': '是' if has_bag else '否',
'bag文件大小(GB)': bag_size if has_bag else 0,
'是否有asc文件': '是' if has_asc else '否',
'asc文件数量': asc_count if has_asc else 0,
'是否有avi文件': '是' if has_avi else '否',
'avi文件数量': avi_count if has_avi else 0
})
# 如果没有找到任何子文件夹,创建空DataFrame
if not results:
normalized_base_path = normalize_path(base_path)
results.append({
'ROS_BAG路径': normalized_base_path,
'是否有bag文件': '否',
'bag文件大小(GB)': 0,
'是否有asc文件': '否',
'asc文件数量': 0,
'是否有avi文件': '否',
'avi文件数量': 0
})
# 转换为DataFrame并写入Excel
df = pd.DataFrame(results)
df.to_excel(writer, sheet_name=sheet_name, index=False)
print(f"行车数据Excel文件已生成: {excel_path}")
return True
except Exception as e:
print(f"处理行车数据失败: {e}")
return False
def process_park_data(config, output_dir):
"""
处理泊车数据
Args:
config (dict): 配置字典
output_dir (str): 输出目录
Returns:
bool: 处理是否成功
"""
try:
park_config = config.get('park_list', {})
date = park_config.get('date', '')
route_path = park_config.get('route_path', '')
car_dict = park_config.get('car_dict', {})
if not all([date, route_path, car_dict]):
print("泊车配置信息不完整")
return False
# 创建Excel写入器
excel_path = os.path.join(output_dir, f"泊车_{date}.xlsx")
with pd.ExcelWriter(excel_path, engine='openpyxl') as writer:
for car_type, car_numbers in car_dict.items():
for car_number in car_numbers:
# 创建sheet名称:车型_车号
sheet_name = f"{car_type}_{car_number}"
print(f"处理泊车数据: {sheet_name}")
# 构建基础路径
base_path = os.path.join(route_path, car_type, str(car_number), date)
# 检查路径是否存在
if not os.path.exists(base_path):
print(f"路径不存在: {base_path}")
# 创建空DataFrame
empty_df = pd.DataFrame(columns=['ROS_BAG路径', 'bag文件数量和大小(GB)',
'blf文件数量和大小(MB)',
'mkv和mp4文件数量和大小(MB)'])
empty_df.to_excel(writer, sheet_name=sheet_name, index=False)
continue
# 存储结果的列表
results = []
# 遍历base_path下的所有子文件夹
for subfolder in os.listdir(base_path):
subfolder_path = os.path.join(base_path, subfolder)
# 确保是文件夹
if not os.path.isdir(subfolder_path):
continue
print(f" 处理子文件夹: {subfolder}")
# 统计各类文件信息(使用详细统计函数)
bag_info = get_detailed_file_info(subfolder_path, ['.bag'], 'GB')
blf_info = get_detailed_file_info(subfolder_path, ['.blf'], 'MB')
video_info = get_detailed_file_info(subfolder_path, ['.mkv', '.mp4'], 'MB')
# 统一使用反斜杠路径
normalized_path = normalize_path(subfolder_path)
# 添加到结果列表,ROS_BAG路径放在第一位
results.append({
'ROS_BAG路径': normalized_path,
'bag文件数量和大小(GB)': bag_info['formatted_str'],
'blf文件数量和大小(MB)': blf_info['formatted_str'],
'mkv和mp4文件数量和大小(MB)': video_info['formatted_str']
})
# 如果没有找到任何子文件夹,创建空DataFrame
if not results:
normalized_base_path = normalize_path(base_path)
results.append({
'ROS_BAG路径': normalized_base_path,
'bag文件数量和大小(GB)': '无',
'blf文件数量和大小(MB)': '无',
'mkv和mp4文件数量和大小(MB)': '无'
})
# 转换为DataFrame并写入Excel
df = pd.DataFrame(results)
df.to_excel(writer, sheet_name=sheet_name, index=False)
print("----------结果----------", results)
print(f"泊车数据Excel文件已生成: {excel_path}")
return True
except Exception as e:
print(f"处理泊车数据失败: {e}")
return False
def main():
"""
主函数
"""
# 配置文件路径
config_path = "file_config_0924.json"
# 输出目录
output_dir = "./output"
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
# 读取配置文件
config = read_config(config_path)
if not config:
return
# 处理行车数据
print("开始处理行车数据...")
drive_success = process_drive_data(config, output_dir)
# 处理泊车数据
print("开始处理泊车数据...")
park_success = process_park_data(config, output_dir)
# 输出结果
if drive_success and park_success:
print("
处理完成!两个Excel文件已生成在以下目录:")
print(f"输出目录: {output_dir}")
else:
print("
处理过程中出现错误,请检查上述日志信息。")
if __name__ == "__main__":
main()
配置文件:config.json
```bash
{
"drive_list": {
"date": "20251107",
"ros": "ROS&BLF",
"route_path": "//intelligent.sto.prod.geely.svc/ISD_file01/1B_Disk_TestTeam_Biange/J6M",
"car_dict": {
"E245-A1": [315, 319],
"FS11-A5": [611, 394],
"FX12-A2": [624],
"KX11-A5": [526, 487],
"P145-A1": [565],
"P181": [382, 497, 498],
"P162": [407, 856],
"P182": [621, 769, 752],
"SS21": [517]
}
},
"park_list": {
"date": "20251107",
"route_path": "//intelligent.sto.prod.geely.svc/ISD_file01/1B_Disk_TestTeam_Biange/J6M",
"car_dict": {
"E245-A1": [311, 314],
"FS11-A5": [137],
"FX12-A2": [691],
"KX11-A5": [534],
"P145-A1": [687],
"P181": [371, 379]
}
}
}
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...