
RAG架构中的嵌入模型

如上图:嵌入模型
嵌入向量模型(Embedding Model)
是一种将单词、句子乃至整个文档表明为高维空间中稠密向量的方法。嵌入的目的在于捕捉文本的语义含义,使得含义相近的词或短语在该向量空间中彼此接近。
嵌入向量是机器学习中的一个核心概念,尤其在自然语言处理领域,但其应用也广泛延伸至其他领域。本质上,嵌入是一种将离散型分类数据转化为连续向量。将复杂且难以直接处理的对象(如单词、图像或文本)转换为机器学习模型能够更有效理解和处理的形式。
嵌入向量之间通过类似度与距离的概念进行比较。下图网格展示了对嵌入向量的一项对比分析:
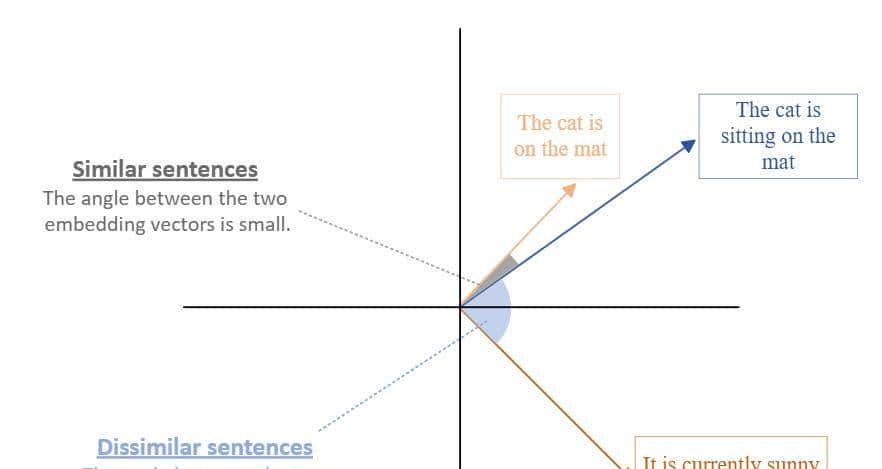
在 RAG解决方案中,一般采用与文本块(chunks)一样的嵌入模型对用户查询进行嵌入化处理。随后,在向量数据库中搜索相关向量,以返回语义相关性最强的文本块。这些相关文本块的原始文本将作为基础数据传递至大语言模型(LLM)。
嵌入模型的重大性
所选择的嵌入模型会显著影响向量搜索)结果的相关性。必须考量嵌入模型的词汇表。每个嵌入模型都使用特定的词汇表进行训练。例如,BERT模型的词汇表规模约为30,000个单词。
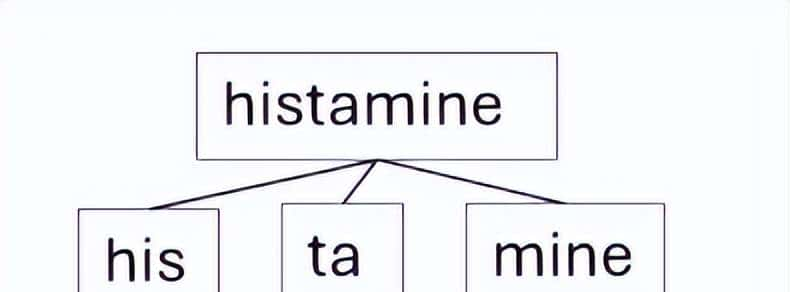
嵌入模型的词汇表至关重大,由于它会以独特方式处理未登录词。即使某个单词不在模型的词汇表中,它仍会为其计算一个向量。为实现这一点,许多模型会将单词拆解为子词。这些模型要么将子词视为独立词元处理,要么聚合各子词的向量以生成一个单一的嵌入向量。
例如,单词 “histamine”(组胺)可能不在某个嵌入模型的词汇表中。该词具有特定的语义含义,指代一种人体释放的、引发过敏症状的化学物质。由于该嵌入模型不包含 “histamine”,它可能会将该词拆解为词汇表中存在的子词,例如 “his”、”ta” 和 “mine”。
选择嵌入模型
为您的应用场景确定合适的嵌入模型。在选择嵌入模型时,需考量其词汇表与您数据词汇之间的匹配度。
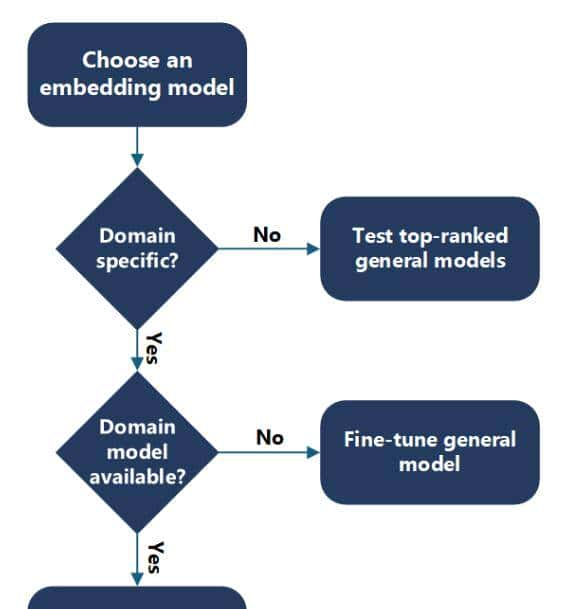
第一,确定您是否拥有领域特定内容。 例如,您的文档是否针对某一具体应用场景、您的组织或某个行业?
判断领域特定性的一个有效方法是:检查您内容中的实体和关键词能否在互联网上找到。如果能找到,那么一个通用嵌入模型很可能也能识别它们。
通用或非领域特定内容
选择通用嵌入模型时,提议从 Hugging Face 排行榜着手。获取最新的嵌入模型排名。评估这些模型在您数据上的表现,并优先尝试排名靠前的模型)。
领域特定内容
对于领域特定内容,需确定是否有可用的领域特定模型。例如,若您的数据属于生物医学领域,则可思考使用 BioGPT 模型。该语言模型已在海量生物医学文献上进行了预训练,适用于生物医学文本挖掘与文本生成。如有可用的领域特定模型,请评估其在您数据上的表现。
若无可用的领域特定模型,或其性能不佳,则可在您的领域特定词汇上对通用嵌入模型进行微调
评估嵌入模型
评估嵌入模型时,可通过可视化嵌入向量并评估问题向量与文本块向量之间的距离来实现。
嵌入向量可视化
您可使用诸如 t-SNE等算法库,将文本块向量与问题向量绘制在二维平面上。随后,可判读文本块向量彼此之间、及其与问题向量之间的距离远近。
下图展示了已绘制的文本块向量:彼此邻近的两个箭头代表两个文本块向量,另一箭头则代表问题向量。此可视化方法有助于理解问题向量与文本块向量之间的距离关系。
计算嵌入距离
可采用程序化方法评估嵌入模型在您的问题和文本块上的效能。具体而言,计算问题向量与文本块向量之间的距离。可选用欧氏距离或曼哈顿距离进行计算。
嵌入经济学
选择嵌入模型时,必须权衡性能 与成本 。大型嵌入模型 一般在基准测试数据集上表现更优。不过,性能的提升伴随着成本的增加:大型向量在向量数据库中占用更多存储空间,并且在比较嵌入向量时需要消耗更多的计算资源和时间。小型嵌入模型在一样基准测试上性能一般较低,但其在向量数据库中所需存储空间更少,比较嵌入向量所需的计算量和时间也更少。
设计系统时,需综合考量嵌入在存储、计算和性能需求三方面的成本。还必须通过实验验证模型的实际性能。需注意的是,公开可用的基准测试结果(主要基于学术数据集,可能无法直接反映您业务数据和应用场景的情况。最终,可根据具体需求,优先选择高性能模型,或在成本与性能之间寻求平衡,即接受足够良好的性能以换取更低的成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。



收藏了,感谢分享