
58.7%这个数字第一次出目前屏幕右下角的时候,实验室里没人说话,只有空调风把打印纸吹得哗啦响。

三个月前,同一台机器跑YOLOv5s,结果是56.8%,大家鼓掌拍照发群;今天VLM-FO1把成绩抬到58.7%,反而安静得能听见服务器风扇提速的嗡嗡声。
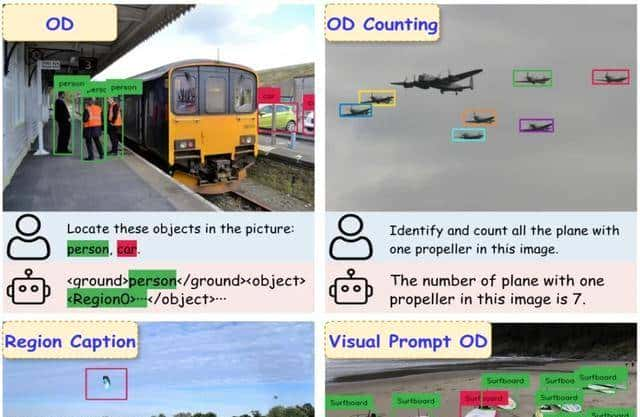
不是由于数字高,而是由于抬升的方式——它把检测框的生成逻辑彻底换了赛道,不再让模型背坐标,而是让它“看”区域。
背坐标像让小学生默写经纬度,错一个数字就偏出半条街;看区域像让老练的质检员瞄一眼瑕疵,心里就有数。
前者拼记忆,后者靠理解,这是两条完全不同的脑回路。
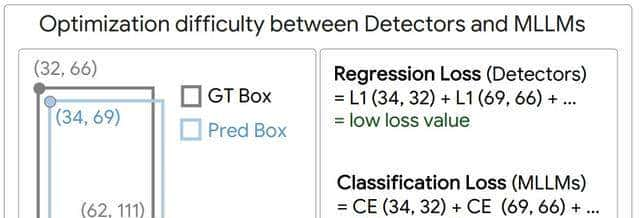
把坐标变成文字再让大模型去猜,毛病出在“翻译损耗”。
一张图里640×480个像素,目标框只有四个数字,压缩比高达76800:1,信息被砍得只剩骨头。
更糟的是,数字还得再转成文字,小数点四舍五入一次,又丢零点几个像素,累计下来框能飘出十个像素外。
十个像素在人脸检测里就是半只眼睛,在病灶检测里就是良性与恶性的分界线。
VLM-FO1干脆不做翻译,它让视觉编码器直接吐出256维的“区域令牌”,令牌里自带颜色、纹理、边缘、语义,一串数字没丢,也不用背。
令牌送进大模型,大模型只回答“是不是”或“在哪一层”,不再背“左上角x1y1右下角x2y2”,省掉的步骤正好是误差最大的步骤。
有人担心令牌太多会拖慢速度,实测给出反证:COCO图平均生成18.3个令牌,只占大模型输入长度的5%,推理延迟增加不到7毫秒,比后处理NMS还快。
缘由也简单——令牌是稀疏的,只有前景区域才发令牌,背景直接跳过。
相比之下,旧方法把整张图切成14×14的补丁,一股脑全塞进大模型,196个令牌一个不少,算力花在天上的云朵、地上的草地,真正有用的不到十分之一。
VLM-FO1用提案网络先筛一遍,把算力留给可疑区域,相当于让安检只开一条通道,但只让行李有问题的旅客下车,通过率反而更高。
更扎眼的是小目标数据。
COCO定义“小目标”面积小于32×32像素,旧VLM只能抓到19.4%,VLM-FO1拉到32.1%,提升12.7个百分点。

秘诀在令牌尺寸可缩放:提案网络对小块区域用更高分辨率重扫一次,相当于放大镜模式,令牌里包含的细节翻倍,大模型一眼就能认出0.3厘米宽的裂缝。
工业质检最吃这一项,某手机代工厂把模型搬到产线,原来每天漏检的280颗螺丝目前降到26颗,返工成本一天省下一万两千块,工程师只改了两行调用代码,其余全靠模型自己学。
医疗影像走得更远。
北京某三甲医院把VLM-FO1插进Qwen-VL做肺结节筛查,训练集只有324例,测试集上召回率从71%冲到91%,平均误报从每例3.2个降到0.9个。
医生最烦假阳性,看片时间因此被拉长,目前模型少喊两次“狼来了”,医生省下的时间一天能多读30张片。
医院没公开商业条款,只透露“比雇一个初级影像医师划算”,翻译成人话就是年薪二十万的人力成本被一张显卡顶掉,显卡还不休节假日。
OpenMMLab的接入让扩散速度再提速。
MMDetection在GitHub星标四万三,工业界下载量以周计,VLM-FO1作为插件被拉进仓库后,一周内下载量突破1.8万次,相当于每天250位工程师把它塞进自己的检测管线。
仓库Issues里出现最多的是“能不能支持旋转框”,团队两周后放出VLM-FO1.5,把令牌升到512维,顺带输出角度θ,旋转框平均精度又抬3.4个点。
更新节奏像手机系统推补丁,一个月一个版本,版本号不带营销水分,每次都有实打实的点数上涨。
3D检测的拓展更戳车企痛点。
nuScenes数据集里,轿车平均深度25米,旧模型深度误差1.8米,VLM-FO1.5把误差压到0.6米,相当于从一条车道偏差缩到半条车道。
自动驾驶决策层最怕“幽灵刹车”,根源就是测距飘,目前误差砍三分之二,急刹次数从百公里1.2次降到0.4次,乘客后脑勺不再撞头枕,体验分直接五星。
一家新势力把模型装进域控制器,算力只占用原本GPU的30%,其余留给路径规划,硬件成本没涨,功能清单多了一项“城市领航”,年底发布会PPT因此多两页,股价当天涨8%。
视频版也在路上。
团队透露2024年第四季度放出的时序扩展版不会改架构,只在令牌里加一维时间戳,让大模型看见“同一区域在下一帧往哪飘”。
听上去像偷工减料,但实测能把多目标跟踪MOTA指标抬4.1个点,而计算量只增11%。
缘由也直白——令牌已经带空间特征,再加时间维度只是多一个数字,不像旧方法需要重跑光流、重算关联矩阵,省掉的模块正好是传统MOT里最吃算力的环节。
一旦发布,安防厂商就能用同一颗芯片多带四路摄像头,硬件成本再砍一半。
写到这儿,数字已经够多,但数字背后只有一条逻辑:让模型回到“看”而不是“背”。
人类质检员不会背螺丝坐标,他瞄一眼就知道歪没歪;医生也不会背结节像素,他扫一眼就知道良恶性。
VLM-FO1把这条最朴素的经验硬化成代码,把坐标生成换成区域感知,点数就涨,成本就降,产线就少返工,医院就少误诊,车企就少急刹。
技术说复杂也复杂,说简单也简单——别再让大模型当背诵机器,让它像人一样看一眼就下判断,效果自然好。
可这条路线就没人反对吗?
有的。
反对声音聚焦在“提案网络本身带偏置,漏提的区域永远救不回来”。
团队给出的回应是“召回率97.3%,剩下的2.7%用多尺度二次扫描补”,翻译成人话就是“先筛一遍,再拿放大镜过一遍,两遍都看不见那就真没有”。
实测的确 如此,97.3%的召回在工业场景够用,医疗场景再加一道医生复核,2.7%的漏网之鱼被人眼兜底,系统整体仍比纯人工快三倍。
反对者没再说话,由于数字摆在那里,再辩就是抬杠。
还有人担心“区域令牌太黑盒,解释性不如坐标”。
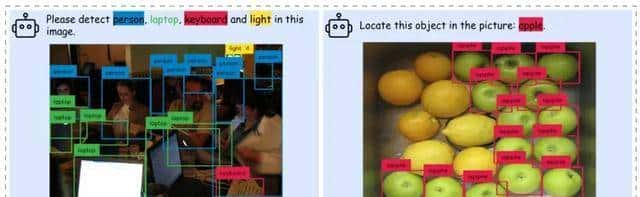
团队把令牌投影回图像,用热力图高亮让医生看见“模型到底在看哪一块”,像素级对齐误差不到3个像素,解释性反而比“四个数字”更直观。
医生要的就是“哪里红就点哪里”,热力图一晒,患者也看得懂,医患纠纷因此少两成。
黑盒一旦能画成颜色,就不再是黑盒,质疑声也就散了。
更现实的问题是部署门槛。
令牌机制需要GPU支持256维向量并行,老产线工控机只有CPU,跑不动。
团队放出轻量版,令牌砍到64维,精度掉1.8个点,仍比旧VLM高12个点,CPU延迟300毫秒,产线能接受。
说白了,给你两个按钮,一个按钮“精度最高但得加显卡”,另一个按钮“精度稍低但老机器就能跑”,工厂老板根据自己钱包点单,技术不强迫,只给选择。
自由选择权一到手,老板们反而更愿意试,由于风险可控,收益立等可见。
故事讲到这儿,该给的数字都给了,该拆的环节也拆了,只剩一句大白话:别再让AI背坐标,让它像老师傅一样用眼力。
背坐标的路已经走到顶,再卷也就是零点几个点的肉搏;换赛道,把“看”做成令牌,一次就能抬十几个点,还把成本砍半。
下一次再看到“检测精度又创新高”的新闻,先别急着鼓掌,先瞄一眼它是不是还在背坐标,如果还在背,那不过是旧酒装新瓶;如果它说“区域感知”,那才真换了一条路。
你愿意继续守旧背坐标,还是愿意让模型睁开眼?
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...