
数据分析是大模型的一个重点应用方向,但怎么使用大模型进行数据分析,以及怎么才能让大模型完整强劲的可靠的数据分析;毕竟如果数据分析的结果不可靠,那将毫无意义。
使用大模型做数据分析的本质,是让大模型扮演一个数据分析员的角色,它会编写SQL,脚本代码等,具备基本的数据分析员的能力。
怎么让大模型更好地进行数据分析
怎么让大模型更好地进行分析?
我们都知道与大模型的交互都是通过提示词实现的,因此这个问题可以换个问法,怎么让大模型更好的编写数据分析代码(包括SQL,shell,python等脚本代码)?并且可以根据执行结果进行下一步的处理。
我们先以SQL为例,从一个实际案例出来,让模型对一张表进行数据分析。
既然大模型做数据分析就是要写好提示词,那什么样的提示词才算是一个好的数据分析师的提示词呢?
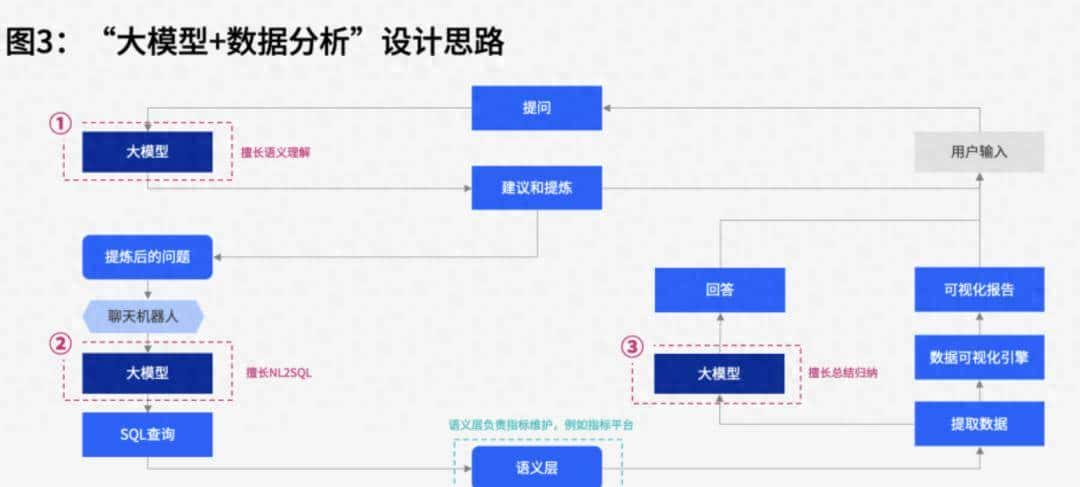
第一除了要指定模型的角色和基础功能之外,还要告知模型我们的要求,列如说需要做什么,不能做什么,有什么规则,需要输出什么样的格式等。
如下是一个简单的数据分析师提示词,其中dialect是我们需要传入的参数,用来告知模型,我们使用的是什么数据,如mysql,pgsql,oracle等,这样模型才能更好理解我们的需求。
你是一个专门与SQL数据库交互的智能代理。
根据用户输入的问题,生成符合{dialect}语法的正确查询语句。
注意事项:
- 只能使用表结构描述中可见的列名
- 确保不查询不存在的列
- 注意列所属的表
- 严格按照表字段备注的含义理解每个参数的作用
- 理解用户问题,并根据表字段的含义,生成SQL语句但其中还有很重大的一步,就是把数据库信息告知模型,而这些我们可以通过获取数据库元数据的方式得到。
如下查询数据表元数据,如果需要查多张表,也可以把table_name的条件给去掉。
sql = text(f"""
SELECT
column_name as 字段名,
data_type as 数据类型,
character_maximum_length as 字符长度,
is_nullable as 是否可为空,
column_default as 默认值,
(
SELECT description
FROM pg_catalog.pg_description
WHERE pg_description.objsubid = information_schema.columns.ordinal_position
AND pg_description.objoid = (
SELECT oid
FROM pg_catalog.pg_class
WHERE relname = information_schema.columns.table_name
AND relnamespace = (
SELECT oid
FROM pg_catalog.pg_namespace
WHERE nspname = information_schema.columns.table_schema
)
)
) as 字段注释
FROM information_schema.columns
WHERE table_schema = 'public'
AND table_name = '{table_name}'
ORDER BY ordinal_position;
"""
)在查询到表结构之后,我们需要解析出表中的字段,类型等属性。
result = await db_session.execute(sql, {"table_name": table_name, "schema": schema})
columns = result.fetchall()
if not columns:
return "No tables found in the database."
output_lines = []
comment_suffix = f"
Table comment: *表备注*"
# --- Schema Table ---
output_lines.append(f"### Table name: `{table_name}`{comment_suffix}
")
output_lines.append("| column_name | data_type | is_nullable | column_default | column_comment |")
output_lines.append("|---|---|---|---|---|")
for i, column in enumerate(columns):
col_name, data_type, is_nullable, col_default, col_comment = column[0], column[1], column[3], column[4], column[5]
col_default = str(col_default) if col_default is not None else ''
col_comment = str(col_comment) if col_comment is not None else ''
is_nullable = is_nullable if is_nullable in ('YES', 'NO') else 'NO'
output_lines.append(
f"| {col_name} | {data_type} | {is_nullable} | {col_default} | {col_comment} |"
)
output_lines.append("")当然,作者这里使用的是pgsql数据库,读者可以根据自己的数据库类型进行适当的调整。
但还有一个关键的步骤是,我们可以从数据表中随机查询一些示例数据出来,列如三到五条,并拼接到数据表结构后面,这样就可以让模型更好地理解我们的表结构和表数据。
如下所示:
quoted_cols = [f'{c[0]}' for c in columns]
sample_sql = text(f'SELECT {", ".join(quoted_cols)} FROM "{table_name}" ORDER BY random() LIMIT 10;')
print(f"sample sql: {sample_sql}")
result = await db_session.execute(sample_sql)
sample_rows = result.fetchall()这样,大模型就可以很好的根据我们的需求生成相应的SQL语句;但从安全性的角度思考,我们最好是对生成的SQL进行基本的安全验证,如drop database;drop table name,delete等语句,否则可能会造成严重的生成事故。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...