部署前:了解你的硬件需求
硬件是大模型运行的基石。根据你的预算和目标,大致可以分为以下几档:
入门体验档:
想跑通7B(70亿参数)左右的模型。你需要一块至少4GB显存的NVIDIA GPU(如GTX 1060 6GB),16GB内存和足够的固态硬盘空间。如果显存不足,可以选择更小参数的模型或使用CPU推理。
流畅运行档:
希望7B-13B模型运行流畅,或尝试更大的模型。建议配备8GB以上显存的GPU(如RTX 3060/4060),32GB内存。
专业/企业档:
部署70B或更大参数模型。这通常需要多张企业级GPU(如NVIDIA A100/H100)或顶级消费卡(如RTX 4090/5090),配合64GB以上的内存和高性能NVMe SSD。
注:如果你的显卡是AMD或Intel的,需要确认所选工具是否支持(如Ollama对AMD支持较好),并可能需要安装ROCm等替代驱动。
核心步骤
一、安装Ollama
访问Ollama官网,根据你的操作系统(Windows/macOS/Linux)下载安装包并安装。

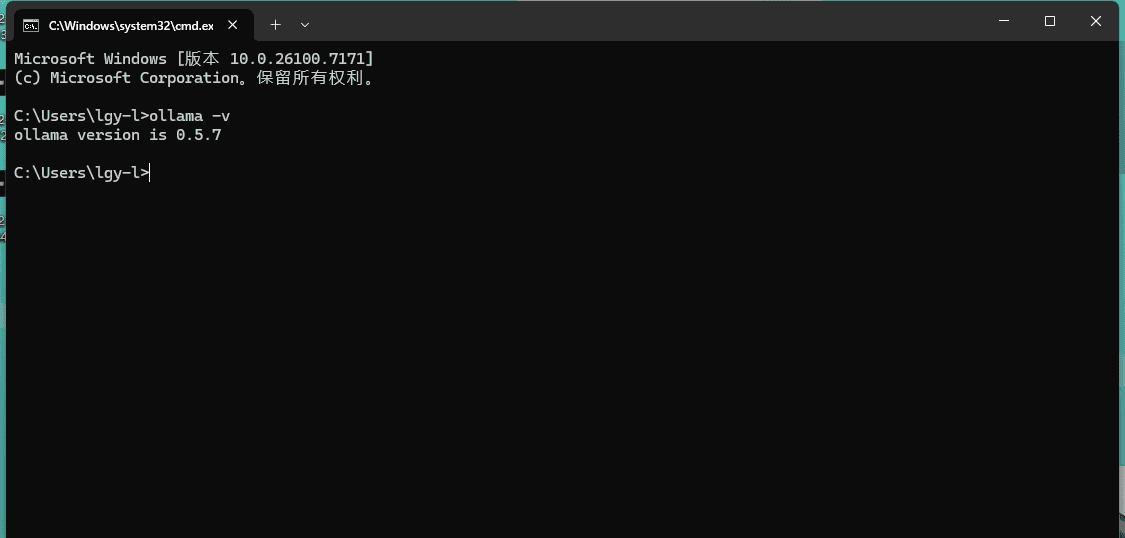
打开终端(或命令提示符),输入 ollama –version,显示版本号即安装成功。
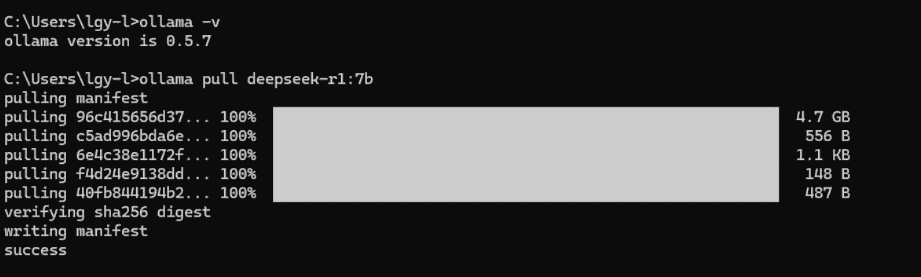
二、下载模型
Ollama内置了模型库。以部署一个7B参数的DeepSeek模型为例,在终端输入:
ollama pull deepseek-r1:7b
这会自动下载模型。你也可以在Ollama官方模型库查找其他模型,如 llama3.1:8b、qwen2.5:7b 等。
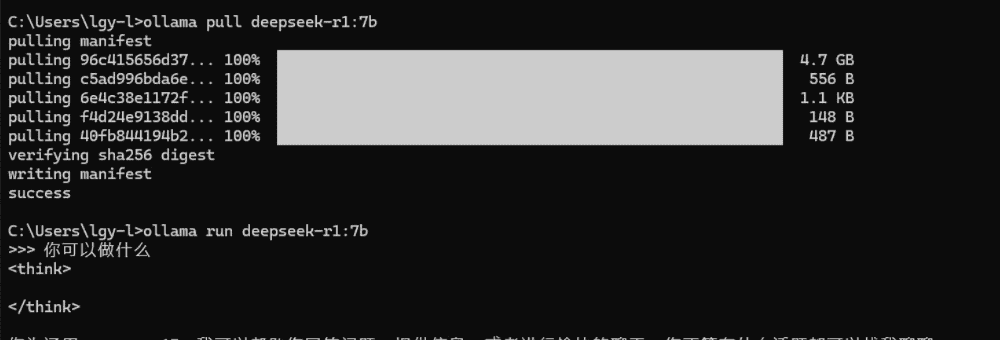
三、运行与测试
模型下载完成后,输入以下命令即可开始交互式对话:
ollama run deepseek-r1:7b
你会看到 >>> 提示符,直接输入问题,模型就会生成回答。
四、进阶使用(可选)
使用图形界面:可以安装 Chatbox 或 Open WebUI 等开源图形界面,连接本地的Ollama服务,获得类似ChatGPT的体验。
作为API服务:Ollama在启动后,默认会在 http://localhost:11434 提供兼容OpenAI的API接口,方便你用自己的程序调用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...