
那家公司最终没继续折腾那些花里胡哨的RAG系统,把钱和精力收回去,先把最基础的检索做稳了。把复杂的智能体项目先放一边,人手去把文档切块、标注时间戳、提升检索精度,客服系统能查到最新评价就行了。
事情是这样的。前几年他们听到“智能+知识检索”多厉害,就上了项目,直接投了一个完整的企业级方案。先是搭DeepSearch,接着又想把Agentic能力接进去,最后还试着做知识图谱。系统上线后表面风光,后台运行成本却把人吓到了。每天模型调用次数暴增,数据源要不停更新,预算跟不上,研发人手也跟不上。客户量一多,运营费用像滚雪球似的,几个月下来,业务线开始抱怨成本高、响应慢、并且有时答案还差劲。
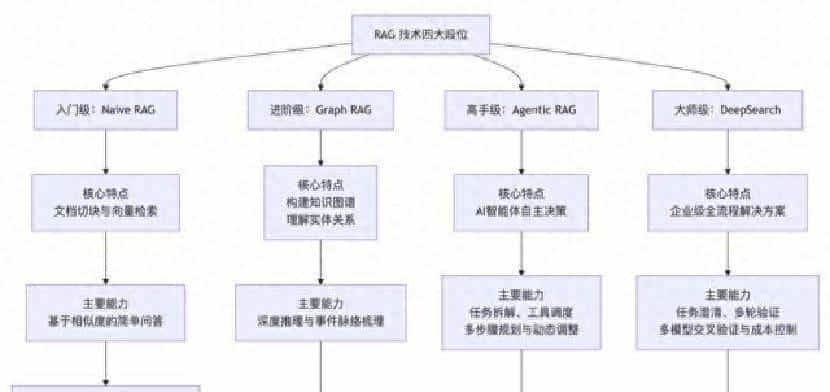
在尝试更高级的方案之前,他们先用了Naive RAG:把文档按块存,用户提问时检索相关段落。当时觉得这最省事,逻辑也简单。但问题马上出现。用户问“后天的活动安排是什么”,系统检索到几个相关段落,却没办法判断“后天”指哪一天,结果给出错位的信息。还有个更让人头疼的问题,长文本根本没法被好好利用。把一本几百页的手册丢进去,模型只看了开头和结尾,中间重大细节被忽略,回答就不完整。这两类问题,被团队戏称为“找不到北”和“长文本失忆症”。
看着Naive RAG的局限,公司决定上更复杂的方案。他们试着做知识图谱,想让系统理解“谁和谁有关联”“哪件事导致了哪种结果”。把零散信息结构化后,系统能把人物关系、事件前因后果串起来,像讲一个人的成长路线图一样把事务连成线。好处明显:跨文档的推理更靠谱了。但付出的代价也不小。知识图谱构建耗时长、需要专人维护,每更新一次数据都像翻修房子,工程量大得惊人,成本也翻倍。对小公司来说,这招有点奢侈。
接下来则是Agentic RAG的试验。这个层级的系统能自主判断什么时候要检索、检索哪些资源,甚至能把复杂问题拆解成多步任务再去完成。举个例子:有人问“去日本旅游要多少钱”,系统不会直接给一个数字,而是先问预算和偏好,然后分步去查机票、住宿、餐饮,最后整合成一套计划。这个体验挺像有个人助手,能主动跟进、反复确认。但它的复杂度和运维成本也高,逻辑设计、调度工具、出错处理都需要大量工程工作。更重大的是,每一次智能判断都要消耗算力和API费用,用户量大了,运营成本会成倍增长。
再往上就是DeepSearch级别,企业级的“全套武装”。这类系统不仅能检索,还包含任务澄清、多轮验证、成本控制等流程。对像金融、医疗这种对专业性和时效性要求极高的场景有价值。系统上线后,能先问清用户的风险偏好、期限之类,再调用多源数据、多模型验证结果。但开发和维护门槛高得吓人,不是一般公司能承受的。有人为了追求这个级别,花了大量预算,最后发现并没有明显提升业务转化。
从大背景看,RAG真正要解决的两个问题是时效性和专业性。数据旧了、知识断档,AI给出的答案就像拿去年股票行情去回答今天的投资,毫无意义。举电商客服的例子:如果顾客问“你们的这款鞋目前咋样”,理想的RAG系统应该能调取最新用户评价、退货率、库存信息,给出一个有据可依的回答,而不是凭训练时的陈旧数据乱讲。另一方面,不是所有问题都需要检索。像“你好”“谢谢”这种打招呼类的短句,盲目触发检索只会浪费资源,有点像跑去图书馆查今天天气。
基于这些经验,他们开始重新梳理技术选型策略。先评估场景复杂度与预算,再决定层级。如果业务场景属于简单的FAQ,Naive RAG可以满足需求,不必上太复杂的系统;要是问题跨领域、需要多跳推理,知识图谱或更高级的方案才有意义。Agentic看起来机智,但如果用户量很大,成本会把人逼疯。许多企业都被“高端技术”这个光环忽悠,最后跑了一圈发现不实用——技术应该帮业务解决问题,而不是用来秀肌肉。
在实际操作上,他们做了几件事:把数据打上时间戳,建立更新流程;优化文档检索的召回与排序策略,让检索结果更贴近用户意图;对常见短语、问候类输入做路由,不去触发昂贵的检索调用;把复杂任务拆成阶段性目标,先用简单方案验证价值,再思考升级。有人把技术选型比作选鞋:不是贵就好,合脚才重大。把基础做到位,后续再看有没有必要上高级功能。
到这个阶段,他们已经不再追求一夜之间把全部能力堆起来,而是把注意力放在能直接改善客户体验的地方。团队开始把更多时间放在检索质量、数据新鲜度和成本控制上,而不是去做那些听起来很牛但短期内看不到回报的模型整合。最终的操作路径也很明确:小步快跑,先稳住基本盘。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...