
3. 大型语言模型
本节回顾大型语言模型,简要描述它们的架构、训练目标、流程、数据集和微调细节。
3.1. 预训练LLM:
在此,我们提供了对各种著名的预训练LLM的总结,这些LLM具有重大发现,改变了NLP领域的研究和发展方向。这些LLM显著提高了NLU和NLG领域的性能,并被广泛地用于下游任务的微调。此外,我们还在表1和表2中确定了预训练LLM的关键发现和见解,这些发现和见解提高了它们的性能。
3.1.1. 通用目的
3.1.1. 通用
T5 [10]:如图7所示,一种编码器-解码器模型,采用统一的文本到文本训练方法来解决所有NLP问题。T5将层归一化置于传统Transformer模型[64]的残差路径之外。它使用掩码语言建模作为预训练目标,其中跨度(连续的token)被替换为单个掩码,而不是每个token单独的掩码。这种类型的掩码加快了训练速度,由于它产生了更短的序列。在预训练之后,该模型使用适配器层[106]针对下游任务进行微调。
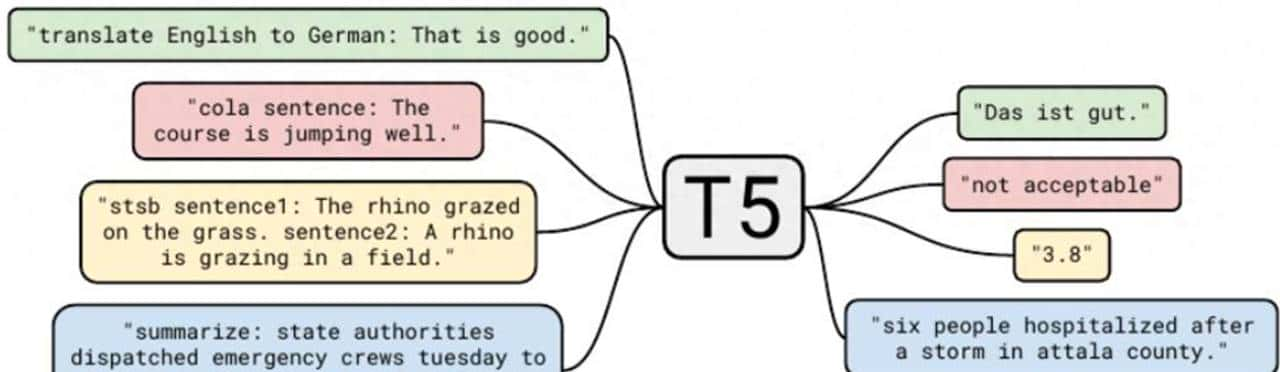
图7
GPT-3 [6]:GPT-3 的架构与 GPT2 [5] 一样,但在 Transformer 层中具有类似于 Sparse Transformer [67] 的密集和稀疏注意力。它表明,大型模型可以使用更大的批量大小和更低的学习率进行训练,以在训练期间确定批量大小,GPT-3 使用梯度噪声尺度,如 [107] 中所述。总的来说,GPT-3 将模型参数增加到 1750 亿,表明大型语言模型的性能随着规模的扩大而提高,并且与微调模型具有竞争力。
mT5 [11]:一个在包含101种语言的mC4数据集上训练的多语言T5模型[10]。该数据集提取自公共的Common Crawl抓取数据。该模型使用更大的词汇量(250,000)来覆盖多种语言。为了避免对某种语言的过拟合或欠拟合,mT5采用了一种数据抽样程序来选择来自所有语言的样本。该论文提议在使用英语数据对任务进行微调时,使用少量预训练数据集,包括所有语言。这使得模型能够生成正确的非英语输出。
PanGu-α [108]: 一种自回归模型,在标准 Transformer 层的末尾有一个查询层(如图 8 所示),用于预测下一个 token。它的结构与 Transformer 层类似,但在注意力机制中为下一个位置添加了一个额外的嵌入,如公式 3 所示。


图8
CPM-2 [12]: 高性价比的预训练语言模型 (CPM-2) 在 WuDaoCorpus [109] 数据集上预训练了双语(英语和中文)11B 和 198B 的混合专家 (MoE) 模型。token 化过程删除了 sentencepiece tokenizer 中的“_”空格 token。这些模型通过知识继承进行训练,第一阶段仅使用中文,然后添加英语和中文数据。这个训练好的模型被多次复制,以初始化 198B MoE 模型。此外,为了将该模型用于下游任务,CPM-2 尝试了完全微调和提示微调,如 [40] 中所述,其中仅通过在各种位置(前、中、后)插入提示来更新与提示相关的参数。CPM-2 还提出了 INFMOE,这是一种内存高效的框架,采用一种策略来动态地将参数卸载到 CPU,以便在 100B 规模上进行推理。它将数据移动与推理计算重叠,以缩短推理时间。
ERNIE 3.0 [110]: ERNIE 3.0 从多任务学习中汲取灵感,构建了一个使用 TransformerXL [111] 作为主干的模块化架构。通用表明模块由所有任务共享,作为特定任务表明模块的基本构建块,所有模块共同训练,用于自然语言理解、自然语言生成和知识提取。这个大型语言模型主要关注中文。它声称在用于大型语言模型训练的最大的中文文本语料库上进行训练,并在 54 个中文自然语言处理任务中取得了最先进的成果。
Jurassic-1 [112]:一对自回归语言模型,包括一个70亿参数的J1-Large模型和一个1780亿参数的J1-Jumbo模型。Jurassic-1的训练词汇表包含词片段、完整单词和多词表达,没有任何词界,其中可能的词汇外实例被解释为Unicode字节。与GPT-3对应模型相比,Jurassic-1模型应用了更平衡的深度-宽度自注意力架构[113]和一个改善的分词器,以便基于更广泛的资源进行更快的预测,在零样本学习任务中实现了相当的性能,并且在少样本学习任务中实现了卓越的性能,由于它能够将更多示例作为提示输入。
HyperCLOVA [114]:一种采用 GPT-3 架构的韩语语言模型。Yuan 1.0 [115]:使用从互联网收集的 5TB 高质量中文语料库进行训练。开发了一个基于 Spark 的海量数据过滤系统 (MDFS),通过粗略和精细的过滤技术来处理原始数据。为了加速 Yuan 1.0 的训练,以节省能源消耗和碳排放,架构和训练中融入了各种提高分布式训练性能的因素:例如,增加隐藏状态大小可以提高流水线和张量并行性能,更大的微批次可以提高流水线并行性能,更大的全局批次大小可以提高数据并行性能。在实践中,Yuan 1.0 模型在文本分类、Winograd Schema、自然语言推理和阅读理解任务中表现良好。
Gopher [116]:Gopher 模型系列的大小从 44M 到 280B 参数不等,旨在研究规模对 LLM 性能的影响。280B 模型在 81% 的评估任务上击败了 GPT-3 [6]、Jurrasic-1 [112]、MT-NLG [117] 等模型。
ERNIE 3.0 TITAN [35]:ERNIE 3.0 Titan 通过训练一个参数数量是后者 26 倍的更大模型来扩展 ERNIE 3.0。这个更大的模型在 68 个 NLP 任务中优于其他最先进的模型。LLM 生成的文本包含不正确的实际。为了控制生成文本的实际一致性,ERNIE 3.0 Titan 在其多任务学习设置中添加了另一项任务,即可信和可控生成。
GPT-NeoX-20B [118]:一个自回归模型,在很大程度上遵循 GPT-3,但在架构设计上有一些偏差,它在未进行任何数据去重的情况下,于 Pile 数据集上进行训练。GPTNeoX 在 Transformer 块中具有并行注意力和前馈层(如公式 4 所示),这使得吞吐量提高了 15%。它使用旋转位置嵌入 [66],并按照 [119] 中的方法,仅将其应用于 25% 的嵌入向量维度。这减少了计算量,而没有降低性能。与使用密集层和稀疏层的 GPT-3 相比,GPT-NeoX-20B 仅使用密集层。这种规模下的超参数调整超级困难;因此,该模型从方法 [6] 中选择超参数,并在 13B 和 175B 模型之间插值得到 20B 模型的值。
该模型训练在使用张量并行和流水线并行的 GPU 之间进行分配。它在预训练步骤中引入了额外的自监督对抗和可控语言建模损失,这使得 ERNIE 3.0 Titan 在他们手动选择的实际问答任务集评估中击败了其他 LLM。

OPT [14]:它是GPT-3的克隆版本,旨在开源一个能够复现GPT-3性能的模型。OPT的训练采用了动态损失缩放 [120],并且每当观察到损失发散时,会从具有较低学习率的早期检查点重新启动。总体而言,OPT-175B模型的性能与GPT3-175B模型相当。BLOOM [13]:一个在ROOTS语料库上训练的因果解码器模型,旨在开源一个LLM。
BLOOM的架构如图9所示,其差异包括ALiBi位置嵌入,以及bitsandbytes1库提议的在嵌入层之后添加的额外的归一化层。这些改变稳定了训练,并提高了下游性能。
GLaM [91]:通用语言模型(GLaM)代表了一系列使用稀疏激活的仅解码器混合专家(MoE)结构 [121, 90] 的语言模型。研究方法:为了获得更多的模型容量同时减少计算量,专家们被稀疏激活,其中只有最好的两个专家被用来处理每个输入token。最大的GLaM模型,GLaM(64B/64E),比GPT-3 [6] 大约大7倍,而每个输入token只激活部分参数。与GPT-3相比,最大的GLaM(64B/64E)模型取得了更好的总体效果,同时仅消耗GPT-3三分之一的训练能量。
MT-NLG [117]: 一个基于GPT2架构的530B因果解码器,其模型参数约为GPT-3的三倍。MT-NLG在从各种公共数据聚焦收集的经过过滤的高质量数据上进行训练,并在单个批次中混合各种类型的数据集,这在多个评估中击败了GPT-3。
Chinchilla [96]:一个因果解码器,与 Gopher [116] 在一样的数据集上训练,但数据抽样分布略有不同(从 MassiveText 中抽样)。模型架构与 Gopher 使用的架构类似,但使用 AdamW 优化器取代 Adam。Chinchilla 确定了模型大小应该随着训练 tokens 每翻倍而翻倍的关系。训练了 400 多个语言模型,参数范围从 7000 万到超过 160 亿,tokens 范围从 50 亿到 5000 亿,以获得在给定预算下计算最佳训练的估计值。作者训练了一个 70B 模型,其计算预算与 Gopher (280B) 一样,但数据量是其 4 倍。经过微调后,它在各种下游任务上优于 Gopher [116]、GPT-3 [6] 等。
AlexaTM [122]:一种编码器-解码器模型,其中编码器权重和解码器嵌入使用预训练的编码器进行初始化,以加快训练速度。编码器在最初的10万步保持冻结状态,之后解冻以进行端到端训练。该模型在去噪和因果语言建模(CLM)目标的组合上进行训练,在开头连接一个[CLM]令牌以进行模式切换。在训练期间,CLM任务应用了20%的时间,这提高了上下文学习性能。
PaLM [15]:一个具有并行注意力和前馈层的因果解码器,类似于公式 4,将训练速度提高了 15 倍。对传统 Transformer 模型的其他更改包括 SwiGLU 激活函数、RoPE 嵌入、在解码期间节省计算成本的多查询注意力以及共享的输入-输出嵌入。在训练期间,观察到损失尖峰,为了解决这个问题,模型训练从提前 100 步的检查点重新开始,跳过了尖峰周围的 200-500 个批次。此外,发现该模型在 540B 模型规模下记忆了大约 2.4% 的训练数据,而较小模型的这一数字较低。
PaLM-2 [123]: PaLM 的一个较小的多语言变体,在更高质量的数据集上进行了更大迭代的训练。PaLM2 显示出比 PaLM 显著的改善,同时由于其较小的尺寸而降低了训练和推理成本。为了减少毒性和记忆,它在预训练数据的一小部分中附加了特殊标记,这表明减少了有害响应的生成。
U-PaLM [124]:此方法使用 UL2(也称为 UL2Restore)目标 [125] 训练 PaLM,计算量额外增加 0.1%。使用一样的数据集,它在各种 NLP 任务上显著优于基线,包括零样本、少样本、常识推理、CoT 等。使用 UL2R 进行训练涉及将因果解码器 PaLM 转换为非因果解码器 PaLM,并采用 50% 的顺序去噪、25% 的常规去噪和 25% 的极端去噪损失函数。
UL2 [125]:一种使用混合降噪器(MoD)目标训练的编码器-解码器架构。降噪器包括1) R-降噪器:一种常规的跨度掩码;2) S-降噪器:它破坏一个大型序列的连续token;以及3) X-降噪器:它随机破坏大量的token。在预训练期间,UL2包含来自R、S、X的降噪器token,以表明一种降噪设置。这有助于提高下游任务的微调性能,这些任务将任务绑定到上游训练模式之一。这种MoD风格的训练在许多基准测试中优于T5模型。
GLM-130B [33]:GLM-130B 是一个双语(英语和中文)模型,它使用类似于 GLM [126] 的自回归掩码填充预训练目标进行训练。与单向的 GPT-3 相比,这种训练方式使模型成为双向的。与 GLM 相比,GLM-130B 的训练包括少量多任务指令预训练数据(占总数据的 5%)以及自监督掩码填充。为了稳定训练,它应用了嵌入层梯度收缩。
LLaMA [127, 21]: 一系列仅解码器语言模型,参数规模从 7B 到 70B 不等。LLaMA 模型系列因其参数效率和指令调优而在社区中最负盛名。
LLaMA-1 [127]: 通过不存储和计算掩码注意力权重以及键/查询分数来实现高效的因果注意力 [128]。 另一项优化是减少反向传播中重新计算的激活数量,如 [129] 中所述。
LLaMA-2 [21]:这项工作更侧重于微调一个更安全、更好的LLaMA-2-Chat模型,用于对话生成。预训练模型拥有多40%的训练数据,具有更大的上下文长度和分组查询注意力机制。
LLaMA-3/3.1 [130]:与LLaMA-2相比,该模型集合在七倍大的数据集上进行训练,上下文长度是其两倍,性能优于之前的变体和其他模型。
PanGu-Σ [92]:一个自回归模型,其参数从PanGu-α复制而来,并通过随机路由专家(RRE)扩展到万亿规模,其架构图如图10所示。RRE类似于MoE架构,区别在于第二层,其中token被随机路由到域中的专家,而不是使用可学习的门控方法。该模型具有在所有域中密集激活和共享的底层,而顶层则根据域进行稀疏激活。这种训练方式允许提取特定于任务的模型,并减少了在持续学习情况下的灾难性遗忘效应。
PanGu-Σ [92]:一个自回归模型,其参数从PanGu-α复制而来,并通过随机路由专家(RRE)扩展到万亿规模,其架构图如图10所示。RRE类似于MoE架构,区别在于第二层,其中token被随机路由到域中的专家,而不是使用可学习的门控方法。该模型具有在所有域中密集激活和共享的底层,而顶层则根据域进行稀疏激活。这种训练方式允许提取特定于任务的模型,并减少了在持续学习情况下的灾难性遗忘效应。

图 10:此示例展示了 PanGu-P 架构,如图所示,该图像来源于 [92]。
Mixtral8x22b [131]:一种混合专家(MoE)模型,具有八个不同的专家,将每个token路由到每一层的两个专家,并将输出以累加方式组合。
Snowflake Arctic [132]:Arctic LLM是密集架构和混合专家(MoE)架构的混合体。MoE(128×3.66B MLP专家)与仅激活两个专家的密集transformer(10B)并行。与其他MoE LLM [131, 133] 相比,该模型具有许多专家,以增加模型容量并提供在多种专家中进行选择以实现多样化配置的机会。该模型具有480B个参数,并且在正向传递期间仅激活17B个参数,从而显着减少了计算量。
Grok [133, 134]: Grok是由XAI发布的LLM系列,包括Grok-1和Grok-1.5。
Grok-1 [133]: Grok-1是一个拥有3140亿参数的语言MoE模型(八个专家),其中每个token激活两个专家。
Grok-1.5 [134]: Grok-1.5 是一个多模态 LLM,具有更长的上下文长度和改善的性能。
Gemini [135, 136]: Gemini 以多模态能力和显著的语言建模性能改善取代了 Bard (基于 PaLM)。
Gemini-1 [135]: 首个在 MMLU 基准测试中实现人类水平能力的自回归模型。
Gemini-1.5 [136]: 一种基于 Gemini-1 的发现构建的具有 MoE 架构的多模态 LLM。该模型具有 200 万的上下文窗口,并且可以推理高达 1000 万 tokens 的信息。此前从未实现过如此大的上下文窗口,并且已被证明对性能提升具有巨大影响。
Nemotron-4 340B [137]:一个仅解码器模型,已在98%的合成数据和仅2%的手动标注数据上进行了对齐。大量使用合成数据可显著提高模型性能。该论文提议在模型预训练的后期引入包含先前见过的数据的较小子集的对齐数据,从而实现从预训练阶段到最终训练阶段的平滑过渡。为了训练更好的指令遵循模型,较弱的模型被迭代训练成较强的模型。由较弱的指令调整模型生成的合成数据用于训练一个基础模型,该模型随后经过监督微调,性能优于较弱的模型。
DeepSeek [138]: DeepSeek 详细研究了LLM的缩放定律,以确定最佳的非嵌入模型大小和训练数据。实验针对8个预算范围进行,范围从1e17到3e20训练FLOPs。每个计算预算都针对十种不同的模型/数据规模进行了测试。批量大小和学习率也针对给定的计算预算进行了拟合,发现批量大小应随着计算预算的增加而增加,同时降低学习率。以下是最佳批量大小 (B)、学习率 (η)、模型大小 (M) 和数据 (D) 的公式:

DeepSeek-v2 [139]:一种MoE模型,引入了多头潜在注意力(MLA)以降低推理成本,通过将键-值(KV)缓存压缩成一个潜在向量。MLA实现了比多头注意力(MHA)更好的性能,以及其他高效的注意力机制,如分组查询注意力(GQA)、多查询注意力(MQA)等。由于MLA,与DeepSeek [138]相比,DeepSeek-v2实现了快5.76倍的推理吞吐量。
3.1.2. 编码
CodeGen [140]: CodeGen 具有与 PaLM [15] 类似的架构,即并行注意力机制、MLP 层和 RoPE 嵌入。该模型按顺序在自然语言和编程语言数据上进行训练(先在第一个数据集上训练,然后在第二个数据集上训练,依此类推),使用的数据集如下:1) PILE,2) BIGQUERY,以及 3) BIGPYTHON。CodeGen 提出了一种用于合成代码的多步方法。其目的是简化长序列的生成,其中先前的提示和生成的代码作为输入,下一个提示用于生成下一个代码序列。CodeGen 开源了一个多轮编程基准 (MTPB),用于评估多步程序合成。
Codex [141]: 这个LLM是在公共Python Github存储库的子集上训练的,目的是从文档字符串生成代码。计算机编程是一个迭代过程,程序在满足需求之前常常被调试和更新。类似地,Codex通过对给定描述重复采样来生成100个版本的程序,从而为77.5%的通过单元测试的问题生成可用的解决方案。其强劲的版本为Github Copilot2提供支持。
AlphaCode [142]:一系列大型语言模型,参数量从3亿到410亿不等,专为竞赛级别的代码生成任务而设计。它使用多查询注意力机制 [143] 来降低内存和缓存成本。由于竞争性编程问题高度需要深入的推理和对复杂自然语言算法的理解,AlphaCode 模型在过滤后的 GitHub 代码(使用流行语言编写)上进行预训练,然后在名为 CodeContests 的新竞争性编程数据集上进行微调。CodeContests 数据集主要包含从 Codeforces 平台3 收集的问题、解决方案和测试用例。预训练采用标准的语言建模目标,而 GOLD [144] 与退火 [145] 作为在 CodeContests 数据上进行微调的训练目标。为了评估 AlphaCode 的性能,在 Codeforces 平台上举办了模拟编程竞赛:总体而言,AlphaCode 在 5000 多名竞争者中排名前 54.3%,其 Codeforces 评分位于最近参与用户的 top 28% 之内。
CodeT5+ [34]:CodeT5+ 基于 CodeT5 [146],具有浅层编码器和深层解码器,经过多阶段训练,最初是单模态数据(代码),后来是双模态数据(文本-代码对)。每个训练阶段都有不同的训练目标,并根据任务激活不同的模型块:编码器、解码器或两者。单模态预训练包括跨度去噪和 CLM 目标,而双模态预训练目标包含对比学习、匹配和文本-代码对的 CLM。CodeT5+ 添加带有文本的特殊 token 以启用任务模式,例如,[CLS ] 用于对比损失,[Match] 用于文本-代码匹配等。
StarCoder [147]: 一个采用 SantaCoder 架构的仅解码器模型,利用 Flash 注意力将上下文长度扩展到 8k。StarCoder 训练一个编码器来过滤训练数据中的姓名、电子邮件和其他个人数据。其微调变体在 HumanEval 和 MBPP 基准测试中优于 PaLM、LLaMA 和 LAMDA。
3.1.3. 科学知识
Galactica [148]: 一个大型的、经过整理的人类科学知识语料库,包含4800万篇论文、教科书、讲义、数百万种化合物和蛋白质、科学网站、百科全书等,使用metaseq库3进行训练,该库构建于PyTorch和fairscale [149]之上。该模型使用< work >标记包装推理数据集,以便为模型提供逐步推理的上下文,这已被证明可以提高在推理任务上的性能。
3.1.4. 对话
LaMDA [150]: 一个仅解码器模型,在公共对话数据、公共对话语料和公共网络文档上进行预训练,其中超过90%的预训练数据为英语。LaMDA的训练目标是生成具有高质量、安全性和依据性的回复。为了实现这一目标,采用了判别式和生成式微调技术,以增强模型的安全性和质量方面。因此,LaMDA模型可以用作执行各种任务的通用语言模型。
3.1.5. 金融
BloombergGPT [151]: 一种非因果解码器模型,使用金融(来自彭博档案的“FINPILE”)和通用数据集进行训练。该模型的架构与BLOOM [13]和OPT [14]类似。它使用[113]中的方法将500亿个参数分配给模型的不同块。为了有效训练,BloombergGPT将文档与< |endo f text| >打包在一起以使用最大序列长度,使用从1024到2048的预热批次大小,并在训练期间手动多次降低学习率。
Xuan Yuan 2.0 [152]: 一种中文金融聊天模型,具有BLOOM [13]的架构,在通用、金融、通用指令和金融机构数据集的组合上进行训练。Xuan Yuan 2.0结合了预训练和微调阶段,以避免灾难性遗忘。
表1:预训练大型语言模型的值得注意的发现和见解



表2:指令调优大型语言模型研究的主要见解和发现。

3.2. 微调的LLMs:
预训练的LLMs对于未见过的任务具有出色的泛化能力。不过,由于它们一般以预测下一个token为目标进行训练,LLMs在遵循用户意图方面的能力有限,并且容易产生不道德、有害或不准确的响应[20]。为了有效利用它们,LLMs会被微调以遵循指令[16, 17, 97]并生成安全响应[20],这也导致了零样本、少样本和跨任务泛化的提升[97, 16, 18],计算增量极小,例如,PaLM 540B总预训练的0.2%[16]。
在本节中,我们将回顾各种微调的LLM以及用于有效微调的策略。
3.2.1. 使用手动创建的数据集进行指令调优
文献中提出了许多具有不同设计选择的手工制作的指令调优数据集,用于指令调优大型语言模型。微调后的大型语言模型的性能取决于多种因素,例如数据集、指令多样性、提示模板、模型大小和训练目标。鉴于此,文献中出现了使用手动创建的数据集进行微调的各种模型。
模型T0 [17] 和 mT0(多语言)[154] 采用模板将现有数据集转换为提示数据集。它们在推广到零样本和保留任务方面表现出改善。Tk-Instruct [18] 使用上下文指令对 T5 模型进行了微调,以研究在测试时给出上下文指令时对未见任务的泛化能力。该模型优于 Instruct-GPT,尽管尺寸较小,即 11B 参数,而 GPT-3 为 175B。
增加任务和提示设置:通过扩展任务集合和提示风格,零样本和少样本性能得到显著提升。OPT-IML [97] 和 Flan [16] 分别整理了更大的 2k 和 1.8k 任务数据集。虽然仅增加任务规模并不足够,但 OPT-IML 和 Flan 在其数据聚焦添加了更多的提示设置,包括零样本、少样本和 CoT。在此基础上,CoT Collection [101] 在 188 万个 CoT 样本上进一步微调 Flan-T5。另一种方法 [102] 使用符号任务,任务来源包括 T0、Flan 等。
3.2.2. 使用大型语言模型生成数据集进行指令调优:
生成指令调优数据集需要仔细编写指令和输入-输出对,这些一般由人工编写,规模较小且多样性不足。为了克服这个问题,Self-instruct [19] 提出了一种方法,提示现有的大型语言模型来生成指令调优数据集。Selfinstruct 的性能优于在人工创建的数据集 SUPER-NATURALINSTRUCTIONS(一个包含 1600 多个任务的数据集)[18] 上训练的模型,提升了 33%。它从一个包含 175 个任务、1 条指令和每个任务 1 个样本的种子开始,并使用以下方法迭代生成新的指令(52k)和实例(82k 输入-输出对):
GPT-3 [6]。与此相反,Dynosaur [155] 使用 Huggingface 上数据集的元数据来提示大型语言模型生成多个任务指令调优数据集。
LLaMA调优:文献中有多种模型使用GPT-3 [6]或GPT-4 [157]生成的数据集对LLaMA [156]进行指令调优。其中,Alpaca [158]、Vicuna [159]和LLaMA-GPT-4 [160]是一些通用的微调模型,Alpaca使用来自textdavinci-003的52k个样本进行训练,Vicuna使用来自ShareGPT.com的70k个样本进行训练,而LLaMA-GPT-4则通过GPT4重新创建Alpaca指令。Goat [161]通过从ChatGPT生成数据,对LLaMA进行算术任务的微调(100万个样本),并且优于GPT-4、PaLM、BLOOM、OPT等,将其成功归功于LLaMA对数字的一致标记化。HuaTuo [162]是一个医学知识模型,使用生成的8k指令的QA数据集进行微调。
复杂指令:Evol-Instruct [163, 164] 提示大型语言模型将给定的指令转换为更复杂的集合。这些指令通过以复杂的措辞重写指令和创建新指令来迭代演变。通过这种自动指令生成方式,WizardLM [163](在 25 万条指令上微调 LLaMA)的性能优于 Vicuna 和 Alpaca,而 WizardCoder [164](微调 StarCoder)则击败了 Claude-Plus、Bard 等模型。
3.2.3. 与人类偏好对齐
将人类偏好融入大型语言模型在减轻不良行为和确保准确输出方面具有显著优势。对齐方面的初步工作,如InstructGPT [20],使用三步法对齐GPT-3:指令调优、奖励建模以及使用强化学习(RL)进行微调。第一,在演示数据上对GPT-3进行监督式微调,然后查询该模型以生成响应,人类标注员根据人类价值观对这些响应进行排序,并在排序后的数据上训练奖励模型。最后,使用近端策略优化(PPO)在奖励模型生成的响应数据上训练GPT-3。LLaMA 2-Chat [21] 通过将奖励建模分为有用性和安全性奖励,并在PPO之外使用拒绝采样来改善对齐。LLaMA 2-Chat的最初四个版本使用拒绝采样进行微调,然后在拒绝采样的基础上使用PPO进行微调。
与支持性证据对齐:这种对齐方式允许模型生成带有证据和实际的回复,减少幻觉,并更有效地协助人类,从而提高对模型输出的信任度。与 RLHF 训练方式类似,训练一个奖励模型来对生成的回复进行排序,这些回复包含对问题的回答中的网络引用,然后用于训练模型,如 GopherCite [165]、WebGPT [166] 和 Sparrow [167]。Sparrow [167] 中的排序模型分为两个分支,偏好奖励和规则奖励,其中人类注释者对抗性地探测模型以打破规则。这两个奖励共同对回复进行排序,以便使用 RL 进行训练。
直接与SFT对齐:RLHF流程中的PPO复杂、内存密集且不稳定,需要多个模型,包括奖励模型、价值模型、策略模型和参考模型。通过在监督式微调(SFT)流程中进行最小的更改,如[168, 169, 170]中所述,可以避免这种复杂的对齐流程,并且性能优于或可与PPO相媲美。直接偏好优化(DPO)[168]直接在人类偏好的响应上训练模型,以最大化偏好响应相对于非偏好响应的可能性,并具有每个样本的重大性权重。奖励排序微调RAFT [169]通过奖励模型对排序后的响应进行模型微调。偏好排序优化(PRO)[171]和RRHF [170]惩罚模型,使其根据人类偏好和监督损失对响应进行排序。另一方面,后见之明链(CoH)[172]以语言而非奖励的形式向模型提供反馈,以学习好与坏的响应。
与合成反馈对齐:使大型语言模型与人类反馈对齐既缓慢又昂贵。文献表明,可以使用一种半自动化过程来对齐大型语言模型,即提示大型语言模型对查询生成有协助、诚实和符合道德的响应,并使用新创建的数据集进行微调。Constitutional AI [173] 在 RLHF 中用 AI 取代人类反馈,称之为来自 AI 反馈的强化学习(RLAIF)。AlpacaFarm [174] 设计提示,使用大型语言模型 API 模仿人类反馈。与 Constitutional AI 相反,AlpacaFarm 在反馈中注入噪声,以复制人类的错误。Self-Align [98] 使用 ICL 示例提示大型语言模型,指示大型语言模型响应应包含哪些内容才能被认为是实用和符合道德的。稍后,使用新数据集对同一大型语言模型进行微调。
与提示对齐:大型语言模型可以通过提示进行引导,以生成所需的响应,而无需训练 [175, 176]。[176] 中的自我纠正提示将指令和思维链 (CoT) 与问题连接起来,引导模型按照一种策略回答其指令,以确保在实际回答之前的道德安全性。这种策略被证明可以显著减少生成响应中的危害。
红队/越狱/对抗性攻击:大型语言模型通过对抗性探测表现出有害行为、幻觉、泄露个人信息和其他缺点。即使这些模型为了安全而进行了对齐,它们也容易生成有害响应 [177, 178]。红队是一种解决非法输出的常用方法,其中提示大型语言模型生成有害输出 [178, 179]。
通过红队测试收集的数据集用于对模型进行安全方面的微调。虽然红队测试主要依赖于人工标注员,但另一项工作 [180] 使用红队大型语言模型来寻找提示,这些提示会导致其他大型语言模型产生有害的输出。
3.2.4. 继续预训练:
虽然微调可以提高模型的性能,但会导致对先前学习信息的灾难性遗忘。在每次迭代中,将微调数据与一些随机选择的预训练样本连接起来,可以避免网络遗忘[181, 152]。这在调整LLM以适应微调数据量小且需要保持原始容量的情况下也很有效。基于提示的持续预训练(PCP)[182]使用与任务相关的文本和指令来训练模型,然后最终对模型进行指令调整,以用于下游任务。
3.2.5. 样本效率。
虽然微调数据一般比预训练数据小许多倍,但它依旧必须足够大才能获得可接受的性能 [16, 97, 18],并且需要成比例的计算资源。研究使用较少数据对性能的影响,现有文献 [183, 184] 发现,在较少数据上训练的模型可以胜过在更多数据上训练的模型。在 [183] 中,发现总下游数据的 25% 足以获得最先进的性能。与完整数据调整相比,选择基于核心集的总指令调整数据的 0.5% 可以将模型性能提高 2% [184]。对齐的少即是多 (LIMA) [185] 仅使用 1000 个精心创建的演示来微调模型,并且已经实现了与 GPT-4 相当的性能。
3.3. 增加上下文窗口:
由于昂贵的注意力机制和高内存需求,LLM 的训练受到有限的上下文窗口的限制。在一个有限序列长度上训练的模型在推理时无法推广到未见过的长度 [186, 49]。或者,具有 ALiBi [65] 位置编码的 LLM 可以执行零样本长度外推。不过,ALiBi 的表达能力较弱 [66],并且在多个基准测试上的性能较差 [46],而且许多 LLM 使用 RoPE 位置嵌入,该嵌入无法执行零样本外推。更大的上下文长度具有诸多优点,例如更好地理解更长的文档、在上下文学习中获得更多样本、执行更大的推理过程等等。在微调期间扩展上下文长度是缓慢、低效且计算成本高昂的 [49]。因此,研究人员采用了下面讨论的各种上下文窗口外推技术。
位置插值:研究[49]表明,相较于外推,在预训练上下文窗口内对位置编码进行插值更为有效。该研究表明,仅需1000步微调即可在更大上下文窗口下获得更优结果,且性能不逊于原始上下文尺寸。Giraffe[46]在RoPE中采用幂次缩放,而YaRN[47]则提出了NTK感知插值法。
高效注意力机制:密集全局注意力是训练大上下文窗口LLM的主要瓶颈。采用局部注意力、稀疏注意力、扩张注意力等高效变体可显著降低计算成本。LongT5[48]提出瞬态全局注意力(TGlobal),通过窗口化令牌平均实现局部与全局令牌的注意力分配。该模型用TGlobal注意力替换T5[10]的注意力机制,在4098序列长度上预训练,并在更大窗口尺寸(最高达16k)上进行微调,显著提升了长输入任务的性能。这证明了TGlobal注意力仅通过微调即可实现外推能力。COLT5[187]采用双分支架构:轻量级分支与重量级分支分别配备轻量级/重量级注意力机制及前馈层。所有令牌经轻量级分支处理后,仅重大令牌被路由至重量级分支。LongNet [188] 用扩张注意力替代标准注意力,将序列长度扩展至10亿个标记。LongLoRA [189] 提出移位短注意力机制,在微调阶段用于降低密集注意力计算成本。但该模型在推理阶段仍采用密集注意力,其性能与全注意力微调相当。
无需训练即可实现外推:LM-Infinite[186]与并行上下文窗口(PCW)[190]证明利用预训练大型语言模型可实现长度外推。LM-Infinite提出在原始上下文窗口边界内应用Λ形注意力机制。同样,PCW将更大输入拆分为预训练上下文长度的片段,并对每个片段应用一样的位置编码。
3.4. 增强型大型语言模型
大型语言模型能够从与输入数据拼接的示例中学习,这种技术被称为上下文增强、上下文学习(ICL)或少样本提示。通过少样本提示,模型展现出对未见任务的卓越泛化能力,使其能够回答超出训练阶段习得能力的查询[6, 55]。这些新兴能力使得模型无需耗费资源进行微调即可实现适应性提升。此外,LLM普遍存在产生不准确、不安全或实际错误响应的幻觉现象,而增强上下文数据可有效规避此问题。虽然用户可在查询中提供上下文样本[54, 32],但本文特指通过程序化方式访问外部存储的方法,将其称为增强型LLM。
现有文献提出了多种外部记忆设计方案以增强劲型语言模型(LLMs),包括长期记忆[191, 192, 193, 194]、短期记忆[195]、符号化记忆[196]和非符号化记忆[197, 198]。记忆可通过文档、向量或数据库等不同格式进行维护。部分系统通过维护中间记忆表明来跨迭代保留信息[194, 192],另一些则从数据聚焦提取关键信息并存储于记忆中以供调用[199]。记忆读写操作可选择性地与LLM协同进行[192, 200, 194, 201],在[195]中更作为反馈信号发挥作用。下文将探讨不同类型的增强型LLM。
3.4.1. 检索增强型大型语言模型
大型语言模型可能存在记忆有限和信息过时的问题,导致回答不准确。通过从外部实时存储中检索相关信息,LLM能够借助参考资料准确作答并利用更丰富的数据。研究表明,经过检索增强的小型模型性能可媲美大型模型:例如[25]中110亿参数模型可与540亿参数的PaLM抗衡,[193]中75亿参数模型则可匹敌280亿参数的Gopher。检索增强型语言模型(RALM)包含两大核心组件(如图12所示):1)检索器;2)语言模型。在RALM中,检索器对驱动LLM响应至关重大——错误信息可能导致模型产生错误行为。为此,研究者开发了多种方法以检索准确信息,并将其与查询融合以提升性能。
零样本检索增强:此类增强方法保持原始大型语言模型(LLM)架构和权重不变,采用BM25[202]、最近邻算法或Bert[7]等冻结的预训练模型作为检索器。检索到的信息作为输入提供给模型以生成响应,研究表明相较于无检索功能的LLM,该方法能显著提升性能[198, 203]。某些场景下需多次检索迭代才能完成任务。首次迭代生成的输出将被传递至检索器以获取类似文档。前瞻性主动检索(FLARE)[197]先生成响应,若响应包含低置信度词元则通过检索相关文档修正输出。类似地,RepoCoder[204]通过递归检索代码片段实现代码补全功能。
基于检索增强的训练:为降低检索增强生成(RAG)的失败率,研究人员采用检索增强管道对检索器和大型语言模型进行训练或微调。下文将根据各研究对管道中不同训练流程的侧重点进行梳理。
训练LLM:检索增强型Transformer(RETRO)[193]研究表明,采用RAG管道预训练的小型LLM表现优于大型LLM(如未采用RAG训练的GPT-3)。RETRO使用MassiveText数据聚焦的2万亿词元子集作为数据库。检索管道将输入查询分割为子集,为每个子集从数据库检索相关片段,并与输入的中间表明共同编码以生成令牌。该模型采用跨片段注意力机制,通过自回归方式关注先前片段。一项针对RETRO的研究[205]表明,未采用RAG预训练但使用RAG进行微调的模型,其性能提升幅度不及采用RAG预训练的模型。
训练检索器:大型语言模型生成的响应质量高度依赖于上下文示例。因此,[206, 207, 208, 209]通过训练检索器在保持语言模型冻结状态下检索准确的少样本示例。在[206, 208]中,检索到的样本经过排序构建基准数据集,用于通过对比学习训练检索器。[207]中通过训练RoBERTa模型实现ICL样本检索的下游任务。REPLUG[209]则利用冻结式LLM生成的输出作为监督信号训练检索器。
检索器与LLM协同训练:在[25, 210, 211]中通过同步训练检索器与模型获得进一步提升。此时错误会反向传播至检索器,实现语言模型与检索器的同步更新。虽然掩码语言建模(MLM)是常见的预训练目标[25,211],但检索预训练变换器(RPT)[210]采用文档片段预测作为长文本建模的预训练目标。
编码上下文增强:随着序列长度和样本数量的增长,将检索到的文档与查询串联变得不可行。通过交叉注意力机制对上下文进行编码并将其与解码器融合(解码器内融合),可在不显著增加计算成本的前提下增强更多样本[212, 193, 210, 25]。
网络增强:本地存储的内存虽独立于LLM,但信息有限。而互联网蕴含海量且持续更新的信息资源。相较于本地存储,多种方法通过网络搜索检索与查询相关的上下文信息,并将其传递给LLM[213, 214, 166]。

图12:检索增强型大型语言模型的流程图。检索器提取与输入类似的上下文,并以简单语言或通过解码器融合(FiD)编码的形式将其传递给大型语言模型。根据任务需求,检索与生成过程可能重复多次。
3.4.2 工具增强型大语言模型(Tool Augmented LLMs)
虽然 RAG 依赖检索器向 LLM 提供上下文以回答查询,但工具增强型 LLM 则利用 LLM 的推理能力,通过将任务分解为子任务、选择必要的工具并采取行动来迭代式地规划任务的完成过程 [215, 216, 217, 27]。图 13 展示了工具增强型 LLM 的通用流程,其中图 13 中的不同模块会在循环中被选择,直到任务完成。
零样本工具增强(Zero-Shot Tool Augmentation)
LLM 的上下文学习能力和推理能力使其能够在无需训练的情况下与工具交互。Automatic Reasoning and Tool-use(ART)[217] 构建了一个包含推理步骤和调用外部工具示例的任务库。它检索类似任务的示例并将其作为上下文提供给 LLM 进行推理。除此之外,[218] 显示仅凭工具文档就足以教会 LLM 使用工具,而不需要示范数据。RestGPT [219] 通过将 LLM 与 RESTful API 集成,将任务分解为规划和 API 选择步骤。API 选择器通过理解 API 文档来选择适合任务的 API,并规划执行流程。ToolkenGPT [220] 将工具作为“token”处理,通过将工具嵌入与其他 token 嵌入拼接。在推理过程中,LLM 会生成表明工具调用的“工具 token”,暂停文本生成,并在工具执行结果返回后重新开始生成。
基于训练的工具增强(Training with Tool Augmentation)
LLM 可以通过训练来学习与多样化工具交互,从而增强规划能力,弥补零样本工具增强的局限性 [221, 27, 222, 223]。Gorilla [221] 使用来自 API 文档的检索信息对 LLaMA 进行指令微调。它在 self-instruct [19] 数据生成流程中使用 GPT-4,并为其提供从 API 文档中检索的上下文示例。Tool Augmented Language Model(TALM)[27] 采用自博弈(self-play)方法对 T5 [10] 进行工具使用微调,它反复完成工具操作任务,并将生成的数据加入训练聚焦。ToolLLM [223] 从 RapidAPI 收集了 16k 个 API,并从中抽样生成由 ChatGPT 编写的指令微调数据集,包含单工具与多工具场景。为了构建高质量数据集,ToolLLM 提出了基于深度优先搜索的决策树(DFSDT)方法,以生成覆盖多样化推理与规划的真实标注。
多模态工具增强(Multimodal Tool Augmentation)
LLM 的组合式推理能力使其能够在多模态环境下操控工具 [215, 216, 224]。按照图 13 所示流程,LLM 一般以如下顺序生成响应:规划(Plan) → 工具选择(Tool selection) → 执行(Execute) → 检查(Inspect) → 生成(Generate)。在此框架中,工具库包含丰富的模态类型,包括文本、图像等。许多多模态工具增强系统采用多模态大模型 [31, 225, 224, 216],而其他系统则使用单模态 LLM,并为其生成使用多模态工具解决多模态查询的计划 [226]。

图 13:工具增强型 LLM 的基本流程示意图。
在给定输入和可用工具集合的情况下,模型会生成完成任务的计划。工具增强型 LLM 会根据任务需求,迭代式地调用不同的模块,例如检索器、工具执行、读写内存、反馈等。
3.5 LLM 驱动的智能体(LLMs-Powered Agents)
AI 智能体是能够自主规划、决策并执行行动以实现复杂目标的自主实体。早期的 AI 智能体大多基于规则,设计用于狭窄任务且能力有限,例如 Clippy [227] 和 Deep Blue [228]。与此不同,LLM 能够应对动态场景的能力,使其能够被应用于多样化的任务,其中包括由 LLM 驱动的智能体 [224, 216],在这些系统中 LLM 充当智能体的“大脑”。LLM 已被用于网页智能体 [166, 167]、代码智能体 [229]、工具智能体 [27, 223]、具身智能体(embodied agents)[26] 以及对话式智能体 [195],并且一般不需要或只需要极少的微调。下面我们总结基于 LLM 的自主智能体研究,更多细节可参考 [230, 231]。
LLM 引导自主智能体
LLM 是自主智能体的认知控制器。它们能够生成计划、对任务进行推理、利用记忆完成任务,并根据来自环境的反馈调整计划。随着 LLM 能力增强,各类方法通过微调、改善提示策略或引入不同模块来提升智能体性能。以下简要讨论自主智能体中使用的模块和策略。
规划与推理(Planning and Reasoning)
完成复杂任务需要类人逻辑思考、规划步骤以及对当前与未来进行推理。
提示工程方法,如 chain-of-thought [103]、tree-of-thoughts [105] 和 self-consistency [104],是智能体的核心能力,它们诱使 LLM 对其行动进行推理,并在不同路径中选择最佳方案。在给定任务描述和动作序列的情况下,LLM 即便不经过微调,也能准确生成行动计划 [232]。Reasoning via Planning(RAP)[233] 使用一个重新设计的 LLM 作为世界模型,用于推理未来结果并探索替代路径以完成任务。Retroformer [234] 则使用一个“回顾型 LLM”向主 LLM 提供任务提示,提升其规划与推理能力。
反馈(Feedback)
在开环系统中,LLM 会生成计划并假设智能体能够按计划成功执行。不过在现实场景中失败与不确定性是常态。为确保任务能够正确完成,许多方法在闭环结构中使用 LLM:环境执行结果作为反馈传回 LLM,使其重新评估并更新计划 [235, 236, 237, 195]。另一类研究将 LLM 用作奖励模型,以训练强化学习(RL)策略,替代人工奖励 [238]。
记忆(Memory)
LLM 可以从提示中的上下文学习。除了内部记忆外,不少系统还使用外部记忆保存历史响应。Reflexion [195] 构建了情节记忆(episodic memory),将过去的响应作为反馈用于提升未来决策;Retroformer [234] 则通过短期记忆(保存最近响应)和长期记忆(保存失败总结)提升输出质量,失败总结会被加入提示作为反思。
多智能体系统(Multi-Agents Systems)
LLM 能够扮演用户设定的角色,并表现为特定领域的专家。在多智能体系统中,每个 LLM 被分配独特角色,以模拟人类行为,并与其他智能体协作完成复杂任务 [229, 239]。
LLM 在物理环境中的应用
LLM 擅长遵循指令,但在物理环境中执行任务需要适配,由于它们缺乏真实世界知识,可能对物理场景给出不合理的预测或指令 [240, 26]。
SayCan [240] 使 LLM 了解可执行的低层操作,其中 LLM(Say)负责构建高层计划,而训练得到的可供性函数(Can)评估计划在现实中的可执行性。SayCan 使用 RL 训练语言条件可供性模型。PaLM-E 则通过训练多模态 LLM,使其直接从传感器输入中处理信息,从而解决具身任务。
操控(Manipulation)
在机器人操控领域 [236, 241],LLM 提升了机器人的灵巧性与适应性,擅长执行物体识别、抓取和协作等任务。LLM 会分析视觉与空间信息以确定与物体交互的最佳方式。
导航(Navigation)
LLM 提升了机器人在复杂环境中导航的精度与适应性 [242, 243, 244, 245]。LLM 能生成可行路径与轨迹,并充分思考环境的复杂细节 [246]。这项能力在仓储、运输、医疗设施和家庭等需要准确且动态可调导航的场景中具有重大价值。
3.6 高效 LLM(Efficient LLMs)
在生产环境部署 LLM 成本高昂。如何在保持性能的前提下降低运行成本,是极具吸引力的研究方向。本节总结了提升 LLM 效率的相关方法。
3.6.1 参数高效微调(Parameter Efficient Fine-Tuning, PEFT)
对具有数十亿或数百亿参数的 LLM 进行微调(例如 GPT-3(175B)、BLOOM(176B)、MT-NLG(540B)等)在计算上极为昂贵且耗时。为避免对整个模型进行完整微调,大量参数高效微调(PEFT)技术 [40, 247, 41, 38, 39] 被提出,以在更低成本下获得可接受的微调效果。
与完整微调 [248] 相比,PEFT 方法在低资源场景表现更优,在中等资源场景表现相当,而在高资源充足的情况下则不及完整微调。图 14 展示了不同 PEFT 技术的概览。
Adapter 微调(Adapter Tuning)
Adapter 方法在 Transformer 模块内部增加少量可训练参数。Adapter 层包含一系列特征降维、非线性变换与升维操作 [106]。Adapter 的变体包括:
- 顺序插入 adapter 层 [106]
- 并行插入 adapter 层 [38]
- Adapter 混合(AdaMix) [249]:在单层中使用多个 adapter 模块,输入会被随机路由到不同的降维-升维模块。推理时对多个 adapter 输出求平均,以避免额外时延。
LoRA(低秩适配) [250] 则通过学习低秩分解矩阵来冻结原始权重。推理时将学习到的权重与原始权重融合,避免延迟。
Prompt 微调(Prompt Tuning)
Prompt 是将预训练 LLM 适应下游任务的高效方式,但手写 Prompt 会带来不稳定性,例如单词微小变化会导致性能显著下降 [247]。
Prompt tuning 通过仅微调 0.001%–3% 的参数来缓解此问题 [251],方法是在模型的输入嵌入中拼接可训练的 Prompt 参数 [247, 40, 251]。
主要方法包括:
- 任务特定的固定离散 Prompt 拼接至输入嵌入 [40]。
- P-Tuning(连续 Prompt) [247]:由于离散 Prompt 不稳定,通过可学习映射将 Prompt 编码为连续 Prompt 并加入模型,仅 Prompt 编码器可训练。
- P-Tuning v2 [251]:将连续 Prompt 拼接到网络的每一层。
- Progressive Prompt [252]:通过逐步添加新的可训练 Prompt 嵌入,避免灾难性遗忘并保留先前任务的知识。
Prefix 微调(Prefix Tuning)
Prefix tuning [41] 在冻结的 Transformer 层前添加一组可训练的、任务特定的 prefix 向量。这些 prefix 向量作为虚拟 token,被右侧的上下文 token 进行注意力访问。
此外,自适应 prefix 微调 [253] 引入门控机制,以控制 prefix 与实际 token 的信息流动比例。
Bias 微调(Bias Tuning)
BitFit [254] 发现仅微调偏置项(bias)在小到中规模训练数据上超级有效:
- 在数据较少的任务中可达到与完整微调一样的性能
- 在数据较多的任务中也能获得相近表现

图14:参数高效微调范式示意图,其中x为输入,h为隐藏状态,图源自[38]。并行适配器和LoRA均属于适配器微调范畴。
3.6.2. 量化(Quantization)
LLM 在推理阶段需要大量计算和内存。例如,部署一个 175B 参数的 GPT-3 模型至少需要五张 80GB 的 A100 GPU,以及约 350GB 的 FP16 权重存储空间 [44]。如此高昂的软硬件需求,使得小型组织难以真正使用 LLM。模型压缩是一种有效解决方案,但在规模超过 6B 参数时常伴随明显性能下降。这是由于大模型中存在大量小模型不具备的大幅值异常点(outliers)[255],导致量化更为困难,需要专门的方法 [44, 256]。
后训练量化(Post-Training Quantization)
这种量化方法几乎不需要训练,且能在不显著降低性能的前提下进行模型压缩。
- LLM-8bit [255]:对与异常点相关的权重仍使用全精度矩阵乘法,其余权重用 8-bit 量化。低精度输出再转换为 FP16 并拼接。但量化后产生同质化词嵌入,导致性能下降。
- Token 级知识蒸馏 + 模块独立缩放 [45]:针对词嵌入退化的问题,引入 token-level 蒸馏,同时为不同模块引入单独量化缩放因子以适应不同的权重分布。
- Outlier Suppression [257]:针对非对称且跨通道出现的异常点,对每个通道的激活分布做平移/缩放,便于量化。
- SmoothQuant [44]:通过平滑激活并将量化难度迁移至权重,将激活和权重量化为 INT8。
权重中会产生少量异常点,但比未经平滑的激活更易量化。 - OPTQ [256]:基于 OBC(Optimal Brain Compression)[258],逐层量化模型并更新权重以补偿量化误差,同时通过懒更新和改善 Cholesky kernel 加速。
- OWQ(Outlier-Aware Weight Quantization) [259]:基于 OPTQ,对易出异常点的权重赋予更高精度,对其余权重赋予较低精度。
量化感知训练(Quantization-Aware Training, QAT)
为了补偿量化导致的性能下降,QAT 在量化模型上进行必定的训练。
- Alpha Tuning(基于 BCQ) [263]:使用二元编码量化(BCQ)量化模型,仅微调量化缩放因子,性能优于传统 PEFT。
- PEQA(Parameter-Efficient Quantization-Aware Adaptation) [264]:降低全连接层精度,仅微调量化缩放参数。
- LLMQAT [262]:从预训练模型生成训练数据,然后通过知识蒸馏训练量化后的学生模型。
- QLoRA [261]:将预训练 LLM 量化到 4-bit float,再结合 LoRA 微调,优于 4-bit int 或普通 float。
3.6.3. 裁剪(Pruning)
裁剪是压缩模型的另一种方式,可显著降低部署成本。
与任务无关的裁剪较难做,而任务相关裁剪更容易且性能更好:先对下游任务微调,再裁剪模型以加快推理。但如果每个任务都维护一个裁剪模型,成本会极高。因此许多结构化/非结构化裁剪方法旨在在保证泛化的情况下压缩模型 [265, 42, 266]。
非结构化裁剪(Unstructured Pruning)
不保持任何结构,直接删除不重大的权重。LLM 与小模型不同:它们只有少量隐藏状态被强烈激活 [255],可用于裁剪依据。
- Wanda [265]:按“权重 × 输入范数”衡量重大性,在每行中裁剪不重大权重,不需额外微调。
- OWL [267]:Wanda 的扩展。不同层的异常点数量不同,因此采用非均匀的裁剪比例。
- CAP(Contrastive Pruning) [43]:迭代式裁剪,通过对预训练模型、微调模型、历史稀疏模型使用对比损失,学习任务相关与任务无关知识。
结构化裁剪(Structured Pruning)
成组删除权重(按行、列、矩阵等),可直接提升推理速度,由于更适配硬件的 tensor core [265]。
- LLM-Pruner [42]:三阶段结构化裁剪:找出相互激活的隐藏状态组 → 保留关键组 → 用 LoRA 微调裁剪后的模型。
- SIMPLE [268]:使用可学习的 mask 进行稀疏化裁剪。
- 另一类方法 [266]:学习 mask 并移除因子分解矩阵中的不重大 rank-1 组件。
3.7. 多模态大模型(Multimodal LLMs, MLLMs)
受大型语言模型(LLMs)在自然语言处理任务中取得巨大成功的启发,越来越多的研究开始推动 LLM 感知多种模态的信息,例如图像 [269, 270, 271]、视频 [272, 273, 274]、音频 [275, 274, 276] 等。相比仅处理文本的标准 LLM,多模态大模型(MLLMs)具有显著优势:通过融合多模态信息,MLLM 能获得更深层的上下文理解,从而生成更智能、表达更丰富的响应。更重大的是,MLLM 更贴近人类的感知方式,能够利用多感官的协同特性构建对世界的整体理解 [276, 26]。再结合友善的用户交互界面,MLLM 能提供直观、灵活且适应性强的交互体验,使用户可以通过多种输入方式与智能系统进行沟通。
根据构建方式,目前的多模态大模型大致可以分为三类:预训练(pre-training)、微调(fine-tuning) 和 提示(prompting)。
本节将详细讨论这三类主流方法,以及 MLLMs 在视觉推理中的重大应用。
(1)预训练(Pre-training)
这类方法旨在通过统一的端到端模型同时支持多种模态。
- Flamingo [269]使用 gated cross-attention 将视觉模态与语言模态融合,其中视觉编码器和 LLM 均为预训练并冻结。
- BLIP-2 [270]提出两阶段预训练 Q-Former,实现视觉–语言对齐:
(i)第一阶段:基于冻结的视觉编码器进行视觉-语言表明学习;
(ii)第二阶段:使用冻结的 LLM 进行零样本图像到文本生成的视觉到语言生成学习。 - MiniGPT-4 [277]使用冻结的 ViT [278]、Q-Former 和 Vicuna LLM [159],仅训练一个线性投影层,以实现视觉和语言模态的对齐。
微调(Fine-tuning)
受到 NLP 中指令微调(instruction tuning)[16] 的启发,研究者使用多模态指令数据对预训练的 LLM 进行微调。通过这种方式,可以轻松将 LLM 扩展为多模态聊天助手 [277, 271, 29] 或多模态任务求解器 [279, 30, 280]。这一方向的关键挑战是:如何构建多模态的指令数据集 [58]。
典型解决方案包括:
- 基准集适配(benchmark adaptation) [279, 281, 282]
- 自指令生成(self-instruction) [19, 31, 283]
- 混合组合(hybrid composition) [284, 280]
为解决语言模态与新增模态之间的差距,研究者引入可学习的接口模块,用于连接冻结的多模态预训练模型。例如:
- LLaMA-Adapter [285]:使用高效 transformer 适配器以少量参数进行训练。
- LaVIN [284]:基于多模态混合适配器动态学习各模态特征权重。
另一类方法则使用专家模型将多模态直接转换为文本。例如:VideoChat-Text [272]:使用 Whisper [286](语音专家模型)从视频中生成文本描述,使后续 LLM 能理解视频内容。
提示(Prompting)
与需要更新模型参数的微调不同,提示通过向模型提供上下文、示例或指令,使其无需参数更新即可完成特定任务。由于提示技术显著降低了对大规模多模态数据的需求,它被广泛用于构建 MLLMs。一个核心应用是:多模态 Chain-of-Thought(CoT) 推理 [103]例如:
- Multimodal-CoT [287]分两步进行:先生成推理过程,再在第二阶段结合原始输入与推理过程生成答案。
- CoT-PT [288]利用 prompt tuning 与视觉偏置(visual bias)隐式生成推理链。
此外,LLM 也可以通过结合多模态描述和工具提示,将复杂任务拆解成多个子任务 [289, 290]。
视觉推理应用(Visual Reasoning Application)
最新的视觉推理系统 [291, 292, 216, 293] 一般结合 LLM 以改善视觉信息理解和视觉-语言融合能力。相比早期依赖小规模 VQA 数据集和小模型的研究 [294, 295],LLM 驱动的方法具有更强的泛化性、涌现能力和交互性 [58]。典型例子:
- PointClip V2 [292]:使用 LLM 生成 3D 专属提示,将其编码为文本特征并与视觉特征结合,用于三维识别。
- GPT4Tools [31]:基于 LoRA [250] 微调 LLM,以适配工具操作相关指令。
在视觉推理体系中,LLM 可以担任:
- 控制器(controller)[293]
- 决策者(decision maker)[296]
- 语义增强器(semantic refiner)[291, 297]
从而显著推动视觉推理研究的发展。
3.8. 总结与讨论
3.8.1. 架构
由于大规模语言模型(LLM)规模巨大,架构和训练策略中的细微改动都会对性能和稳定性产生显著影响。本节总结了 LLM 中常用的关键架构模块,这些模块能够提升性能、减少训练时间和内存占用,并改善训练稳定性。
层归一化(Layer Normalization)
层归一化对 LLM 的性能和训练稳定性具有显著影响。“前置归一化(Pre-norm)”——即对层的输入而非输出执行归一化——更常用于 LLM 中,由于它能增强训练稳定性 [6, 127, 108]。
- BLOOM [13] 和 AlexaTM [122] 在嵌入层前额外加入层归一化,用以稳定大规模模型训练;但其零样本泛化能力可能会受到负面影响 [13]。
- 不过,另一项研究 [33] 指出:前置归一化相比后置归一化,会导致微调性能下降,并且在超过 100B 参数后不再带来额外稳定性收益。
因此 GLM-130B [33] 使用了一种后置归一化的变体——DeepNorm,目的是在微调后获得更好的下游任务表现。
位置编码(Positional Encoding)
位置编码作为模型的构建模块之一,也会影响 LLM 的性能和训练稳定性。
- BLOOM [13] 的实验发现:ALiBi 的表现优于 learned positional encoding 和 rotary positional encoding。
- 相反,GLM-130B [33] 则认为:Rotary positional encoding 的表现优于 ALiBi。
因此,目前文献中尚未就哪种位置编码最优达成一致结论。
并行注意力(Parallel Attention)
在这种注意力设计中,Transformer Block 中的前馈网络(FFN)与注意力层并行放置,而非顺序堆叠。
- 研究显示其可减少 15% 的训练时间,且没有观察到性能下降。
- PaLM [15]、GPT-NeoX [118]、CodeGen [140] 均采用该结构。
多查询注意力(Multi-Query Attention)
这种结构在 Transformer Block 中让 所有注意力头共享 key 和 value,但 query 仍独立投影。
优点:
- 降低内存占用
- 加速自回归解码阶段的采样速度
- 允许更大的 batch size,提高训练效率
- 文献中尚未观察到性能下降
该方法已用于 [15, 142] 中的模型。
专家混合(Mixture of Experts, MoE)
MoE 结构支持模型规模扩展到数万亿参数 [92, 91]。特点:
- 每次计算只激活少量专家,因此计算成本低
- 在一样数据量下,性能超过稠密模型
- 微调时所需的计算量更小
- 不易发生灾难性遗忘,因此适合持续学习 [92]
- 可从 MoE 中提取小型子模型用于下游任务,且几乎不损失性能,使其对硬件更友善 [92]
稀疏 vs 稠密激活
- GPT-3 [6] 使用稀疏 Transformer [67]
- GLaM [91] 与 PanGu-α [92] 使用 MoE [121]
这些方法可降低计算成本,同时允许增大模型规模和容量。当前文献的观点:
- 稀疏模块不会降低性能 [67]
- 但仍需更多实验以进一步验证
3.8.2. 训练策略(Training Strategies)
在大规模训练模型时,需要使用一系列技巧来降低训练成本、避免损失发散,并获得更好的性能。下面总结并讨论不同 LLM 中采用的一些关键策略。
混合精度(Mixed Precision)
混合精度是 LLM 中广泛使用的、用于降低显存占用并提高训练效率的方法。
- 在混合精度中,前向与反向传播使用 FP16,而优化器状态与主权重保持为 FP32 [120]。
- 该精度转换的缺点是:
由于 FP16 数值范围较小,训练可能出现不稳定,如损失值突然飙升 [33]。
一种替代方案是 BF16:
- BF16 具有更大的数值范围;
- 对精度敏感的运算(如梯度累积、softmax)仍以 FP32 执行 [13];
- BF16 训练更稳定、性能更好;
- 但占用更多显存,并需要特定硬件(如 A100 GPU),因此在 LLM 中的采用仍受限。
训练不稳定性(Training Instability)
损失发散或损失尖峰是在 LLM 训练中常见的问题,且可能多次发生。其出现一般伴随着 梯度裁剪(gradient clipping) [15]。缓解方法包括:
- 从较早的检查点重启训练 [15, 33, 91]
- 在发散点跳过之前的 200–500 个 batch [15]
- 重新随机打乱 batch 顺序 [91]
此外:
- 嵌入层梯度缩放(embedding layer gradient shrink) 可稳定训练——由于嵌入层的梯度范数远大于其他层 [33]。
- 另一提议是:对于大模型,不要在 dense 层和 normalization 层中使用 bias,如 [15] 所示。
权重初始化(Weight Initialization)
权重初始化对模型收敛和训练稳定性至关重大。
- GPT-NeoX [118] 对残差前的前馈层使用12d2d1 的初始化方式 [153],其他层则采用 small-init 策略 [298],以避免随着深度增加激活指数式增大。
- MT-NLG [117] 发现:较大的初始化方差会导致训练不稳定,因此 small-init 被验证更可靠。
- 某些模型使用随机初始化可能导致“坏初始化”,Galactica [148] 提议延长 warmup 来消除影响。
学习率(Learning Rate)
合适的学习率对稳定训练十分关键。
- 文献提议使用较小的学习率 [13, 15, 124],并结合 warmup 与衰减(cosine 或 linear)。
- LLM 中学习率一般处于1e−4 ~ 8e−4 范围。
- MT-NLG(530B)[117] 与 GPT-NeoX(20B)[118] 推荐基于 GPT-3(13B~175B)模型插值学习率,从而避免手动调参。
训练并行(Training Parallelism)
3D 并行(数据并行 + 流水并行 + 张量并行) 是 LLM 中最常见的并行方式[33, 15, 14, 13, 117, 115, 112]。
- BLOOM [13] 在此基础上使用 ZeRO 优化器 [37] 来切分优化器状态。
- PanGu-α [108] 和 PanGu-Σ [92] 采用更进一步的 5D 并行,额外包含优化器并行和重物化(rematerialization)。
模式切换(Mode Switching)
在训练中,在文本前加入任务相关的特殊 token,用于区分自然语言理解(NLU)与自然语言生成(NLG)等模式。文献 [125, 124, 122] 表明这能提升下游任务表现。在微调与推理阶段,会根据任务添加相应 token。
可控文本生成(Controllable Text Generation)
从预训练模型中生成可信且可控的文本是一项挑战。
- GPT-3 [6] 与其他 LLM 使用 in-context learning 来控制生成内容。
- ERNIE 3.0 Titan [35] 进一步提出:
- 使用 对抗损失(adversarial loss) 对生成文本按可信度排序;
- 使用软提示(soft prompts),如体裁、主题、关键词、情感、长度,以增强文本的可控性。
3.8.3. 监督模型 vs 通用模型
尽管通用模型能够执行多种任务并达到良好效果,但它们在许多 NLP 任务中仍未超过监督训练模型。文献 [6, 15, 18] 显示监督模型仍在多个任务上保持显著领先。
3.8.4. 零样本 vs 少样本
LLMs 在零样本(zero-shot)和少样本(few-shot)场景中表现良好,但:
- 对于仅预训练的模型,zero-shot 与 few-shot 性能差距 很大 [6, 15]
- 因此 LLM 被称为 元学习器(meta-learners) [6]
此外:
- 在神经机器翻译中,预训练 LLM 的 zero-shot 能力不如无监督方法 [6]
- 文献表明:仅靠预训练不足以获得优秀的 zero-shot 能力 [15, 16]
提升 zero-shot 的关键:指令微调(instruction fine-tuning),显著提升 zero-shot 表现
,能泛化到未见任务
- Flan-PaLM [16] 通过 Chain-of-Thought(CoT)训练 进一步激发 zero-shot 推理能力。
3.8.5. Encoder vs Decoder vs Encoder-Decoder
传统上:
- Encoder-only:适用于 NLU(如 BERT、RoBERTa)
- Decoder-only:适用于 NLG(如 GPT 系列)
- Encoder-Decoder:适用于 Seq2Seq(如 T5、UL2)
LLM 主要有两类:
- Decoder-only(GPT-3、GPT-NeoX、BLOOM、LLaMA 等)
- Encoder-Decoder(T5、UL2、AlexaTM 等)
文献存在分歧:
- PaLM、GPT-3 等 decoder-only 模型在 NLU + NLG 上均获得巨大提升。
- 但 T5 [10] 和 UL2 [125] 认为 encoder-decoder 架构整体表现更强。
- PaLM [15] 发现:随着 decoder-only 模型规模增大,两种架构的性能差距缩小。
近期趋势:
- 一些 encoder-decoder 模型加入 模式切换 token 实现任务切换 [125, 122]。
- CodeT5+ [34] 使用多任务训练目标,并根据任务启用 encoder、decoder 或两者。
这种动态配置使模型能够适配不同任务场景,因此,未来的 LLM 架构有很大可能回归或强化 Encoder-Decoder 体系。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...